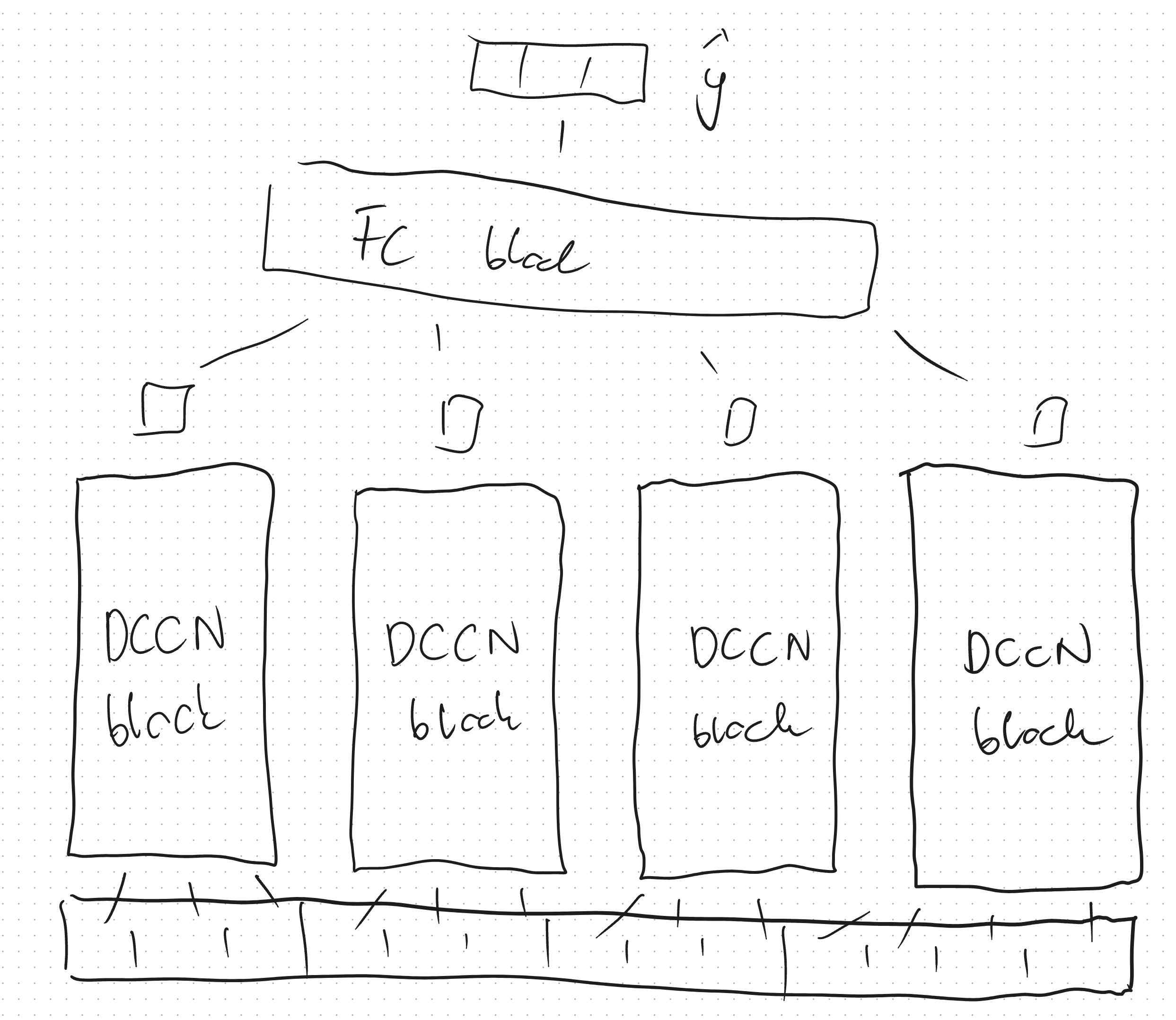
I found the reason. The issue occurs when I use MPS device. On CPU it works just fine.
# %%
import math
import torch
import torch.nn as nn
# %%
device = "mps"
# %%
class DCCN(nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, activation):
super().__init__()
layers = []
num_layers = int(math.log2(256))
for i in range(num_layers):
if i == 0:
in_ch, out_ch = in_channels, hidden_channels
elif i < num_layers - 1:
in_ch, out_ch = hidden_channels, hidden_channels
else:
in_ch, out_ch = hidden_channels, out_channels
layers.append(nn.Conv1d(in_ch, out_ch, kernel_size=2, dilation=2**i))
layers.append(activation())
self.model = nn.Sequential(*layers)
def forward(self, input):
return self.model(input)
class FC(nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
layers = []
num_layers = 3
for i in range(num_layers):
if i == 0:
in_ch, out_ch = in_channels, hidden_channels
elif i < num_layers - 1:
in_ch, out_ch = hidden_channels, hidden_channels
else:
in_ch, out_ch = hidden_channels, out_channels
layers.append(nn.Linear(in_ch, out_ch))
layers.append(nn.ReLU())
self.model = nn.Sequential(*layers)
def forward(self, input):
return self.model(input)
class Model(nn.Module):
def __init__(self, activation):
super().__init__()
self.dccn_1 = DCCN(3, 8, 2, activation=activation)
self.dccn_2 = DCCN(3, 8, 2, activation=activation)
self.dccn_3 = DCCN(3, 8, 2, activation=activation)
self.dccn_4 = DCCN(4, 8, 2, activation=activation)
self.fc = FC(4 * 2, 16, 3)
def forward(self, window):
dccn_1_out = self.dccn_1(window[:, :3])
dccn_2_out = self.dccn_2(window[:, 3:6])
dccn_3_out = self.dccn_3(window[:, 6:9])
dccn_4_out = self.dccn_4(window[:, 9:])
dccn_out = torch.cat([dccn_1_out, dccn_2_out, dccn_3_out, dccn_4_out], dim=1).permute(0, 2, 1)
fc_out = self.fc(dccn_out)
return fc_out
# %%
X, Y = torch.rand(512, 13, 259).to(device), torch.rand(512, 4, 3).to(device)
# %% [markdown]
# ### ReLU
# %%
model = Model(activation=nn.ReLU).to(device)
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.L1Loss()
# %%
model.train()
# %%
Y_pred = model(X)
optimizer.zero_grad()
loss = criterion(Y_pred, Y)
print(Y_pred.shape, Y.shape, loss)
loss.backward()
optimizer.step()
# %% [markdown]
# ### Tanh
# %%
model = Model(activation=nn.Tanh).to(device)
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.L1Loss()
# %%
model.train()
# %%
Y_pred = model(X)
optimizer.zero_grad()
loss = criterion(Y_pred, Y)
print(Y_pred.shape, Y.shape, loss)
loss.backward()
optimizer.step()