I face a problem about copy tensor to cpu.
I test same step on V100 and P100 card. Same environment.
On V100 card machine, the .cpu() step only cost less than 0.01s.
But on P100 card machine, this single step cost 5 second at most(based on the length of tensor, one dimesion length about 10,0000)
Is that only about the GPU? I use CUDA 9 and pytorch 1.0.0.
How are you testing?
Moving to CPU is going to potentially require synchronization as most GPU operations are asynchronous. So it depends on whether the GPU result is actually there and the time will often be due to other operations that aren’t yet completed.
It’s also likely to depend a fair bit on bus latency which will depend on connection method and also other load on the system. Are they both NVLink or both PCIe? Performance will likely differ a lot between the two.
In general though you want to avoid waiting on CPU transfers. Not actually accessing the CPU tensor immediately I think generally results in not synchronising when you call .cpu() (though would love clarification here), or you can explicitly do an asynchronous transfer to CPU (a search will find details, but think the basics are to pin your destination host memory and use dest.copy_(src, non-blocking=True). Though I think this was only enabled in PyTorch 1.2 due to a previous bug. That issue should also have or link to full code.
I’ve added the synchhronize(), result didn’t change.
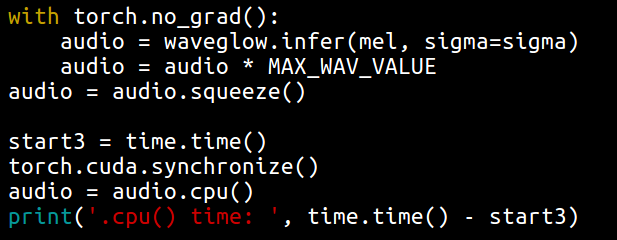
here is the code I test:
both are PCIe. I tried use copy_() like:
y = torch.empty(audio.shape[0], device=‘cpu’)
y.copy_(audio, non_blocking=True)
the time is almost same as copy()
That code will likely be partly (perhaps mostly) measuring the time taken to do the actual processing in waveglow.infer which would of course be expected to be faster on the V100. To measure just the copy you should synchronize before the copy, start timing, copy and them sync again before taking the end time. As in:
The synchronize here is needed to retrieve the time, it is not actually related to timing and can be done at a later point. So you don’t have to slow down the processing with synchronize by collecting timing.
Oh, I forgot to note that asynchronous copies can only happen on a non-default stream, they won’t work on the default stream 0. By default all work in PyTorch occurs on the stream 0 so asynchronous copies won’t happen. If you use a non-default stream you also need to synchronize it to the default stream yourself, by, for example recording an event on the default stream after issuing the work (i.e. calling the appropriate tensor methods, remembering they are asynchronous so work is not completed immediately), and then having the non-default stream wait on that event before copying. I won’t give an example as you need to understand the issues around synchronisation before applying this. There are examples of at least the PyTorch specific parts of this, though they generally assume some familiarity with CUDA programming.
I believe you also need to pin the CPU memory you are copying to, either by calling pin_memory on an existing tensor, or by passing pin_memory when creating the tensor (though I’m not sure all methods of creation support this parameter).
And, as noted asynchronous copies from GPU to CPU are only fixed in PyTorch 1.2 so unless you have upgraded they won’t work.
I can confirm that if properly implemented they can help, I reduced the impact of some work in a forward hook (so slowing down the training loop) by taking care of all the above issues (non-default stream/pin-memory/synchronise streams/PyTorch 1.2). But they won’t always help. If you go on to access items in the CPU tensor immediately after the copy then it will force synchronisation and performance won’t increase. But I think just issuing PyTorch operations on the CPU tensor is fine as they are asynchronous (again happy to be corrected by someone more knowledgeable here).