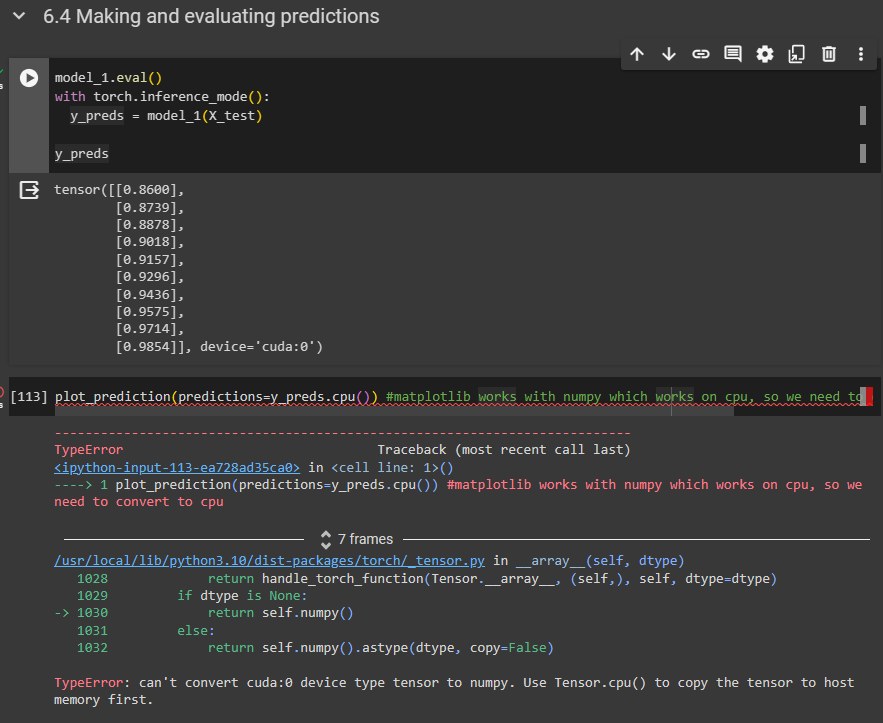
y_preds is a tensor thats on the GPU, but since Matplotlib can only work with NumPy, i tried to move it to the CPU by using the .cpu() method but the same error shows up.
I also tried the .cpu().numpy(), but the same error shows up. Could anyone advice me on how to solve this?
Could you post a minimal and executable code snippet reproducing the error, please?
import torch
from torch import nn
import matplotlib.pyplot as plt
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
#Create some data using the linear regression formula
def plot_prediction(train_data = X_train,
train_labels = y_train,
test_data = X_test,
test_labels = y_test,
predictions = None):
plt.figure(figsize=(10, 7))
plt.scatter(train_data, train_labels, c="b", s = 4, label = "Training data")
plt.scatter(test_data, test_labels, c="g", s = 4, label = "Test data")
if predictions is not None:
plt.scatter(X_test, predictions, c="r", label = "predictions")
plt.legend(prop={"size" : 14})
weight = 0.7
bias = 0.3
#Create range values
start = 0
end = 1
step = 0.02
#Create X and y (features and labels)
X = torch.arange(start, end, step).unsqueeze(dim = 1) #without unsqueeze, errors will pop up, shape errors during matmul in training loop
y = weight * X + bias
#.unsqueeze(dim = 1)
X[:10], y[:10]
train_split = int(0.8 * len(X))
X_train, y_train = X[:train_split], y[: train_split]
X_test, y_test = X[train_split:], y[train_split: ]
len(X_train),len(y_train),len(X_test),len(y_test)
plot_prediction(X_train, y_train, X_test, y_test)
class LinearRegressionModelV2(nn.Module):
def __init__(self):
super().__init__()
#use nn.Linear() for creating the model parameters/also called linear transform/probing layer/fully connected layer
self.linear_layer = nn.Linear(in_features = 1, out_features = 1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear_layer(x)
#set the manual seed
torch.manual_seed(42) #the values arent exactly the same because of how pytorch works behind the scenes but, there is still reproducibility
model_1 = LinearRegressionModelV2()
model_1, model_1.state_dict()
model_1.to(device)
next(model_1.parameters()).device
#Set up loss function
loss_fn = nn.L1Loss() #MAE
#Set up optimizer
optimizer = torch.optim.SGD(params = model_1.parameters(),lr = 0.01)
torch.manual_seed(42)
epochs = 200
#put data on the same device as the model
X_train = X_train.to(device)
y_train = y_train.to(device)
X_test = X_test.to(device)
y_test = y_test.to(device)
for epoch in range(epochs):
model_1.train()
y_pred = model_1(X_train)
loss = loss_fn(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
###Testing
model_1.eval()
with torch.inference_mode():
test_pred = model_1(X_test)
test_loss = loss_fn(test_pred, y_test)
if epoch % 10 == 0:
print(f"Epoch: {epoch} | Loss:{loss} | Test Loss: {test_loss}")
print(model_1.state_dict())
model_1.eval()
with torch.inference_mode():
y_preds = model_1(X_test)
y_preds
plot_prediction(predictions=y_preds.cpu()) #matplotlib works with numpy which works on cpu, so we need to convert to cpu
Above is the code snippet! Sorry about the comments, I am still learning Pytorch and these are like my notes
plot_prediction expects 4 inputs, which are set to default tensors, and one optional input argument, which is the only passed input argument in:
plot_prediction(predictions=y_preds.cpu())
The default arguments are set as X_train, y_train, etc. which are all CUDATensors, so you would also need to move these to the CPU.
Besides that you are also using X_test directly:
if predictions is not None:
plt.scatter(X_test, predictions, c="r", label = "predictions")
instead of the assigned local variable test_data, which is also wrong.
After fixing this issue and passing all inputs explicitly, your code works.