Ok. I have something weird going on. I want to calculate perceptual loss of an autoencoder. I store the activation maps of generated image and ground truth in two different dictionaries. Apparently after converting the activation maps from (Batch x C x H x W) → (Batch x H x W x C) one activation map is of type torch.float32 and the other is float32. But both activation maps goes through same function. How did this happened?
I am attaching the code below
def enc_percept_loss(model, image, gt):
enc_activation_img = {}
enc_activation_gt = {}
def get_activation_enc(name, dest):
def hook(model, input, output):
dest[name] = output.detach()
return hook
encoder.convA.register_forward_hook(get_activation_enc('convA', enc_activation_img))
encoder.l1A.register_forward_hook(get_activation_enc('l1A', enc_activation_img))
encoder.l2A.register_forward_hook(get_activation_enc('l2A', enc_activation_img))
encoder.lnA.register_forward_hook(get_activation_enc('lnA', enc_activation_img))
z_img = model(image)
for k in enc_activation_img.keys():
enc_activation_img[k] = convert_img(enc_activation_img[k])
#print(type(enc_activation_img[k]))
encoder.convA.register_forward_hook(get_activation_enc('convA', enc_activation_gt))
encoder.l1A.register_forward_hook(get_activation_enc('l1A', enc_activation_gt))
encoder.l2A.register_forward_hook(get_activation_enc('l2A', enc_activation_gt))
encoder.lnA.register_forward_hook(get_activation_enc('lnA', enc_activation_gt))
z_gt = model(gt)
for k in enc_activation_gt.keys():
enc_activation_gt[k] = convert_img(enc_activation_gt[k])
#print(type(enc_activation_gt[k]))
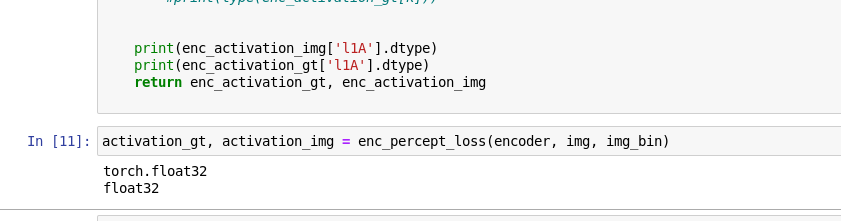
print(enc_activation_img['l1A'].dtype)
print(enc_activation_gt['l1A'].dtype)
return enc_activation_gt, enc_activation_img
and convert_img is
def convert_img(input_tensor):
if input_tensor.device.type == 'cuda':
input_tensor = input_tensor.to('cpu')
output_tensor = input_tensor.detach().numpy()
output_tensor = output_tensor.transpose(0, 2, 3 ,1)
return output_tensor