class BERT4REC(nn.Module):
"""
BERT model : Bidirectional Encoder Representations from Transformers.
"""
def __init__(
self,
vocab_size: int = 20695+2,
max_len: int = 512,
hidden_dim: int = 256,
encoder_num: int = 12,
head_num: int = 12,
dropout_rate: float = 0.1,
dropout_rate_attn: float = 0.1,
initializer_range: float = 0.02,
sentence_embedding_path = 'sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2',
user_embed_dim = 8,
item_embed_dim = 8,
genre_num:int = 28,
country_codes:int = 4,
continue_play:int = 2,
pr_keywords:int = 8,
ch_keywords:int = 9,
gender:int = 2,
age_dim = 1,
):
"""
:param vocab_size: vocab_size of total words
:max_len : max len of seq
:param hidden_dim: BERT model hidden size
:param encoder_num: numbers of Transformer encoders
:param head_num : number of attention heads
:param dropout_rate : dropout rate
:param dropout_rate_attn : attention layer의 dropout rate
:param initializer_range : weight initializer_range
"""
super(BERT4REC, self).__init__()
self.vocab_size = vocab_size #
self.max_len = max_len
self.hidden_dim = hidden_dim
self.encoder_num = encoder_num
self.head_num = head_num
self.dropout_rate = dropout_rate
self.dropout_rate_attn = dropout_rate_attn
self.dropout = nn.Dropout(p=self.dropout_rate)
self.ff_dim = hidden_dim * 4
self.user_embed_dim = user_embed_dim
self.item_embed_dim = item_embed_dim
# embedding
self.embedding = BERTEmbeddings(vocab_size=self.vocab_size, embed_size=self.hidden_dim, max_len=self.max_len)
## Item side Informations ##
self.genre_embedding = nn.Embedding(num_embeddings=genre_num+2, embedding_dim=self.item_embed_dim)
self.country_embedding = nn.Embedding(num_embeddings=country_codes+2, embedding_dim=self.item_embed_dim)
self.continue_play_embedding = nn.Embedding(num_embeddings=continue_play+2, embedding_dim=self.item_embed_dim)
## User side Informations ##
self.pr_keyword_embedding = nn.Embedding(num_embeddings=pr_keywords, embedding_dim=self.user_embed_dim)
self.ch_keyword_embedding = nn.Embedding(num_embeddings=ch_keywords, embedding_dim=self.user_embed_dim)
self.gender_embedding = nn.Embedding(num_embeddings=gender, embedding_dim=self.user_embed_dim)
# self.user_info = nn.Linear(in_features=(self.pr_keyword_embedding,
# self.ch_keyword_embedding,
# ))
self.user_info_mlp = nn.Linear(self.user_embed_dim*3+1, self.user_embed_dim) # user embedding dim * 3 + age dim(1)
self.item_info_mlp = nn.Linear(self.item_embed_dim*3, self.item_embed_dim)
# sentence embedding
if sentence_embedding_path is not None:
self.sentence_embedder=AutoModel.from_pretrained(sentence_embedding_path).eval()
# freeze sentence embedding
for p in self.sentence_embedder.parameters():
p.requires_grad=False
self.projection_layer=nn.Linear(self.sentence_embedder.config.hidden_size,self.hidden_dim)
# activation
self.activation = nn.GELU()
self.fusion_layer=nn.Linear(self.user_embed_dim+self.hidden_dim+self.item_embed_dim,self.hidden_dim)
self.output_layer=nn.Linear(self.hidden_dim+self.item_embed_dim,vocab_size)
# Transformer Encoder
self.transformer_encoders = nn.ModuleList(
[
TransformerEncoder(
hidden_dim=self.hidden_dim+self.item_embed_dim,
head_num=self.head_num,
ff_dim=self.ff_dim,
dropout_rate=self.dropout_rate,
dropout_rate_attn=self.dropout_rate_attn,
)
for _ in range(self.encoder_num)
]
)
# weight initialization
self.initializer_range = initializer_range
self.apply(self._init_weights)
def _init_weights(self, module: nn.Module) -> None:
""" Initialize the weights.
"""
if isinstance(module, (nn.Linear, nn.Embedding)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.initializer_range)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
def forward(
self,
tokens=None,
genres=None,
countries=None,
sex=None,
age=None,
input_ids=None,
token_type_ids=None,
attention_mask=None,
c_plays=None,
pr_keyword=None,
ch_keyword=None,
title_input_dict=None,
labels=None,
segment_info: Optional[torch.Tensor]=None,
**kwargs,
):
# mask : [batch_size, seq_len] -> [batch_size, 1, seq_len] -> [batch_size, 1, 1, seq_len]
# broad - casting
seq=tokens
mask = (seq > 0).unsqueeze(1).unsqueeze(1)
seq = self.embedding(seq, segment_info)
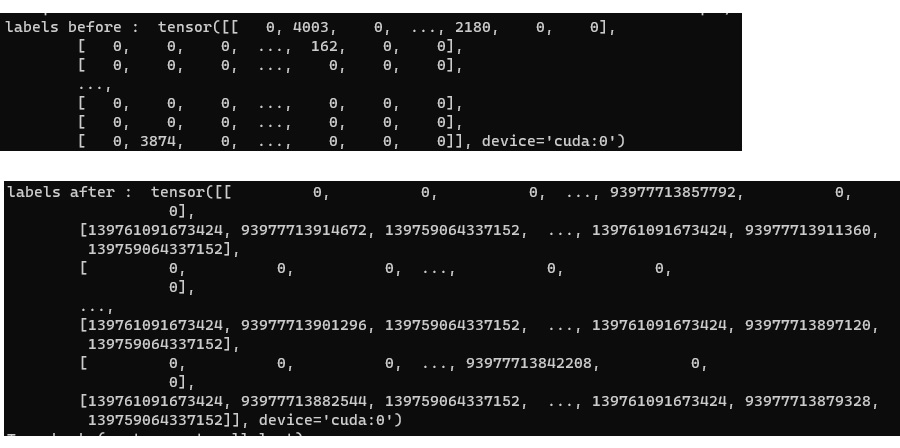
print("labels before : ",labels)
sentence_embeddings_batched=[]
## Item side Informations ##
for input_ids, token_type_ids, attention_mask in zip(input_ids,token_type_ids,attention_mask):
with torch.no_grad():
sentence_embedder_output = self.sentence_embedder(input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask,)
sentence_embeddings = mean_pooling(sentence_embedder_output, attention_mask)
sentence_embeddings = self.projection_layer(sentence_embeddings)
sentence_embeddings_batched.append(sentence_embeddings)
sentence_embeddings_batched = torch.stack(sentence_embeddings_batched)
seq = seq+sentence_embeddings_batched
# print("seq shape : ",seq.shape)
# print("genres : ",genres)
genre_embedding = self.gender_embedding(genres)
country_embedding = self.country_embedding(countries)
continue_play_embedding = self.continue_play_embedding(c_plays)
item_output=self.item_info_mlp(torch.cat([genre_embedding, country_embedding, continue_play_embedding], dim=-1))
item_output=self.dropout(self.activation(item_output))
seq=torch.cat([seq,item_output],dim=-1)
for transformer in self.transformer_encoders:
seq = transformer(seq, mask)
# seq=self.fusion_layer(torch.cat([user_output,seq],dim=-1))
logits=self.output_layer(seq) # logits : [batch_size, max_len, vocab_size]
print("labels after : ",labels)
# print("labels :",labels)
if labels is not None:
loss_fn=nn.CrossEntropyLoss(ignore_index=0)
loss = loss_fn(logits.transpose(1, 2), labels)
return loss,logits
return logits
hi, this is my custom BERT4REC model