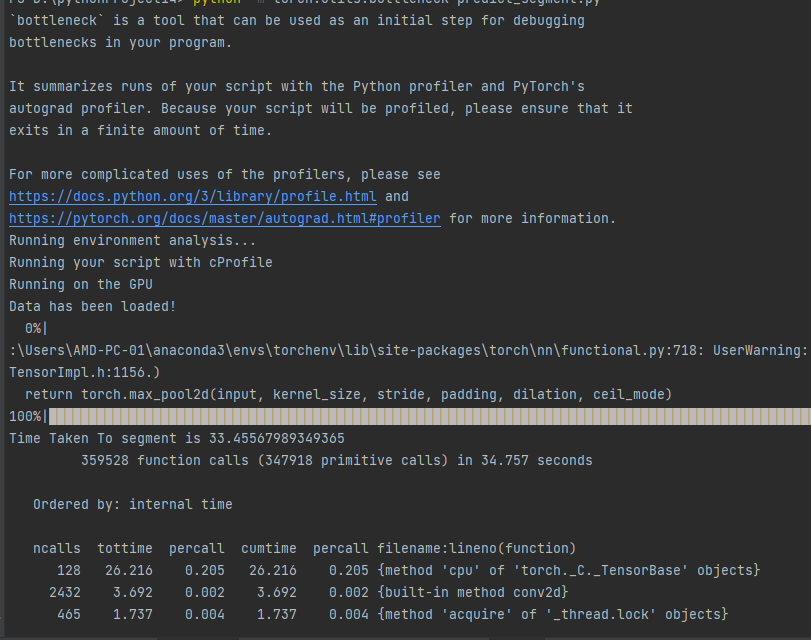
did some profiling using pytorch profiler (not an expert), and it seems that indexing a tensor is faster than using item. the latter requires cuda + cpu operations while the former only cpu.
profiling code: profiler.py
import torch
from torch.profiler import profile, record_function, ProfilerActivity
def function():
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
z = torch.rand(1000, 1000).to(DEVICE)
zs = z.sum().view(1, )
torch.cuda.synchronize()
with profile(activities=[ProfilerActivity.CPU,
ProfilerActivity.CUDA],
record_shapes=True) as prof:
with record_function("compute_th"):
zs.item()
print(prof.key_averages().table(sort_by="cuda_time_total",
row_limit=10))
with profile(activities=[ProfilerActivity.CPU,
ProfilerActivity.CUDA],
record_shapes=True) as prof:
with record_function("compute_th"):
zs[0]
print(prof.key_averages().table(sort_by="cuda_time_total",
row_limit=10))
if __name__ == '__main__':
cuda = "1"
DEVICE = torch.device(
"cuda:{}".format(cuda) if torch.cuda.is_available() else "cpu")
function()
$ python profileer.py
------------------------------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
compute_th 87.05% 1.708ms 94.34% 1.851ms 1.851ms 0.000us 0.00% 2.000us 2.000us 1
aten::item 1.17% 23.000us 7.14% 140.000us 140.000us 0.000us 0.00% 2.000us 2.000us 1
aten::_local_scalar_dense 2.96% 58.000us 5.96% 117.000us 117.000us 2.000us 100.00% 2.000us 2.000us 1
Memcpy DtoH (Device -> Pageable) 0.00% 0.000us 0.00% 0.000us 0.000us 2.000us 100.00% 2.000us 2.000us 1
aten::zeros 2.91% 57.000us 5.15% 101.000us 101.000us 0.000us 0.00% 0.000us 0.000us 1
aten::empty 0.92% 18.000us 0.92% 18.000us 9.000us 0.000us 0.00% 0.000us 0.000us 2
aten::zero_ 1.48% 29.000us 1.48% 29.000us 29.000us 0.000us 0.00% 0.000us 0.000us 1
cudaMemcpyAsync 2.70% 53.000us 2.70% 53.000us 53.000us 0.000us 0.00% 0.000us 0.000us 1
cudaStreamSynchronize 0.31% 6.000us 0.31% 6.000us 6.000us 0.000us 0.00% 0.000us 0.000us 1
cudaDeviceSynchronize 0.51% 10.000us 0.51% 10.000us 10.000us 0.000us 0.00% 0.000us 0.000us 1
------------------------------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 1.962ms
Self CUDA time total: 2.000us
------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::zeros 5.13% 12.000us 8.12% 19.000us 19.000us 1
aten::empty 3.42% 8.000us 3.42% 8.000us 4.000us 2
aten::zero_ 0.43% 1.000us 0.43% 1.000us 1.000us 1
compute_th 69.23% 162.000us 88.46% 207.000us 207.000us 1
aten::select 15.81% 37.000us 18.38% 43.000us 43.000us 1
aten::as_strided 2.56% 6.000us 2.56% 6.000us 6.000us 1
cudaDeviceSynchronize 3.42% 8.000us 3.42% 8.000us 8.000us 1
------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 234.000us
$ CUDA_LAUNCH_BLOCKING=1 python profiler.py
------------------------------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
compute_th 82.48% 1.224ms 91.71% 1.361ms 1.361ms 0.000us 0.00% 2.000us 2.000us 1
aten::item 2.36% 35.000us 9.03% 134.000us 134.000us 0.000us 0.00% 2.000us 2.000us 1
aten::_local_scalar_dense 2.63% 39.000us 6.67% 99.000us 99.000us 2.000us 100.00% 2.000us 2.000us 1
Memcpy DtoH (Device -> Pageable) 0.00% 0.000us 0.00% 0.000us 0.000us 2.000us 100.00% 2.000us 2.000us 1
aten::zeros 4.58% 68.000us 7.68% 114.000us 114.000us 0.000us 0.00% 0.000us 0.000us 1
aten::empty 0.94% 14.000us 0.94% 14.000us 7.000us 0.000us 0.00% 0.000us 0.000us 2
aten::zero_ 2.36% 35.000us 2.36% 35.000us 35.000us 0.000us 0.00% 0.000us 0.000us 1
cudaMemcpyAsync 3.71% 55.000us 3.71% 55.000us 55.000us 0.000us 0.00% 0.000us 0.000us 1
cudaStreamSynchronize 0.34% 5.000us 0.34% 5.000us 5.000us 0.000us 0.00% 0.000us 0.000us 1
cudaDeviceSynchronize 0.61% 9.000us 0.61% 9.000us 9.000us 0.000us 0.00% 0.000us 0.000us 1
------------------------------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 1.484ms
Self CUDA time total: 2.000us
------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::zeros 4.69% 12.000us 7.42% 19.000us 19.000us 1
aten::empty 3.12% 8.000us 3.12% 8.000us 4.000us 2
aten::zero_ 0.39% 1.000us 0.39% 1.000us 1.000us 1
compute_th 69.14% 177.000us 89.06% 228.000us 228.000us 1
aten::select 17.58% 45.000us 19.14% 49.000us 49.000us 1
aten::as_strided 1.56% 4.000us 1.56% 4.000us 4.000us 1
cudaDeviceSynchronize 3.52% 9.000us 3.52% 9.000us 9.000us 1
------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 256.000us
now, when we change to other operations that implicitly use .item() (according to this), such as max(), we get this:
import torch
from torch.profiler import profile, record_function, ProfilerActivity
def function():
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
z = torch.rand(1000, 1000).to(DEVICE)
zs = z.sum().view(1, )
torch.cuda.synchronize()
with profile(activities=[ProfilerActivity.CPU,
ProfilerActivity.CUDA],
record_shapes=True) as prof:
with record_function("compute_th"):
z.max()
print(prof.key_averages().table(sort_by="cuda_time_total",
row_limit=10))
with profile(activities=[ProfilerActivity.CPU,
ProfilerActivity.CUDA],
record_shapes=True) as prof:
with record_function("compute_th"):
z.max().view(1, )[0]
print(prof.key_averages().table(sort_by="cuda_time_total",
row_limit=10))
if __name__ == '__main__':
cuda = "1"
DEVICE = torch.device(
"cuda:{}".format(cuda) if torch.cuda.is_available() else "cpu")
function()
results:
$ python profiler.py
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
compute_th 0.01% 265.000us 99.99% 1.910s 1.910s 0.000us 0.00% 25.000us 25.000us 1
aten::max 0.09% 1.748ms 99.98% 1.909s 1.909s 25.000us 100.00% 25.000us 25.000us 1
void at::native::reduce_kernel<512, 1, at::native::R... 0.00% 0.000us 0.00% 0.000us 0.000us 24.000us 96.00% 24.000us 24.000us 1
Memset (Device) 0.00% 0.000us 0.00% 0.000us 0.000us 1.000us 4.00% 1.000us 1.000us 1
aten::zeros 0.00% 48.000us 0.00% 85.000us 85.000us 0.000us 0.00% 0.000us 0.000us 1
aten::empty 0.00% 45.000us 0.00% 45.000us 15.000us 0.000us 0.00% 0.000us 0.000us 3
aten::zero_ 0.00% 23.000us 0.00% 23.000us 23.000us 0.000us 0.00% 0.000us 0.000us 1
aten::as_strided 0.00% 5.000us 0.00% 5.000us 5.000us 0.000us 0.00% 0.000us 0.000us 1
cudaMemsetAsync 0.00% 31.000us 0.00% 31.000us 31.000us 0.000us 0.00% 0.000us 0.000us 1
cudaLaunchKernel 99.88% 1.908s 99.88% 1.908s 1.908s 0.000us 0.00% 0.000us 0.000us 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 1.910s
Self CUDA time total: 25.000us
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
compute_th 2.10% 73.000us 98.39% 3.422ms 3.422ms 0.000us 0.00% 22.000us 22.000us 1
aten::max 18.17% 632.000us 94.59% 3.290ms 3.290ms 22.000us 100.00% 22.000us 22.000us 1
void at::native::reduce_kernel<512, 1, at::native::R... 0.00% 0.000us 0.00% 0.000us 0.000us 21.000us 95.45% 21.000us 21.000us 1
Memset (Device) 0.00% 0.000us 0.00% 0.000us 0.000us 1.000us 4.55% 1.000us 1.000us 1
aten::zeros 0.95% 33.000us 1.38% 48.000us 48.000us 0.000us 0.00% 0.000us 0.000us 1
aten::empty 0.83% 29.000us 0.83% 29.000us 9.667us 0.000us 0.00% 0.000us 0.000us 3
aten::zero_ 0.09% 3.000us 0.09% 3.000us 3.000us 0.000us 0.00% 0.000us 0.000us 1
aten::as_strided 0.14% 5.000us 0.14% 5.000us 2.500us 0.000us 0.00% 0.000us 0.000us 2
cudaMemsetAsync 0.86% 30.000us 0.86% 30.000us 30.000us 0.000us 0.00% 0.000us 0.000us 1
cudaLaunchKernel 75.04% 2.610ms 75.04% 2.610ms 2.610ms 0.000us 0.00% 0.000us 0.000us 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 3.478ms
Self CUDA time total: 22.000us
$ CUDA_LAUNCH_BLOCKING=1 python profiler.py
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
compute_th 0.02% 247.000us 99.99% 1.585s 1.585s 0.000us 0.00% 27.000us 27.000us 1
aten::max 0.08% 1.316ms 99.98% 1.585s 1.585s 27.000us 100.00% 27.000us 27.000us 1
void at::native::reduce_kernel<512, 1, at::native::R... 0.00% 0.000us 0.00% 0.000us 0.000us 25.000us 92.59% 25.000us 25.000us 1
Memset (Device) 0.00% 0.000us 0.00% 0.000us 0.000us 2.000us 7.41% 2.000us 2.000us 1
aten::zeros 0.00% 51.000us 0.01% 90.000us 90.000us 0.000us 0.00% 0.000us 0.000us 1
aten::empty 0.00% 30.000us 0.00% 30.000us 10.000us 0.000us 0.00% 0.000us 0.000us 3
aten::zero_ 0.00% 28.000us 0.00% 28.000us 28.000us 0.000us 0.00% 0.000us 0.000us 1
aten::as_strided 0.00% 4.000us 0.00% 4.000us 4.000us 0.000us 0.00% 0.000us 0.000us 1
cudaMemsetAsync 0.00% 27.000us 0.00% 27.000us 27.000us 0.000us 0.00% 0.000us 0.000us 1
cudaLaunchKernel 99.89% 1.584s 99.89% 1.584s 1.584s 0.000us 0.00% 0.000us 0.000us 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 1.585s
Self CUDA time total: 27.000us
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
compute_th 3.66% 78.000us 98.08% 2.091ms 2.091ms 0.000us 0.00% 23.000us 23.000us 1
aten::max 16.84% 359.000us 91.98% 1.961ms 1.961ms 23.000us 100.00% 23.000us 23.000us 1
void at::native::reduce_kernel<512, 1, at::native::R... 0.00% 0.000us 0.00% 0.000us 0.000us 22.000us 95.65% 22.000us 22.000us 1
Memset (Device) 0.00% 0.000us 0.00% 0.000us 0.000us 1.000us 4.35% 1.000us 1.000us 1
aten::zeros 0.89% 19.000us 1.41% 30.000us 30.000us 0.000us 0.00% 0.000us 0.000us 1
aten::empty 1.22% 26.000us 1.22% 26.000us 8.667us 0.000us 0.00% 0.000us 0.000us 3
aten::zero_ 0.09% 2.000us 0.09% 2.000us 2.000us 0.000us 0.00% 0.000us 0.000us 1
aten::as_strided 0.28% 6.000us 0.28% 6.000us 3.000us 0.000us 0.00% 0.000us 0.000us 2
cudaMemsetAsync 1.31% 28.000us 1.31% 28.000us 28.000us 0.000us 0.00% 0.000us 0.000us 1
cudaLaunchKernel 72.94% 1.555ms 72.94% 1.555ms 1.555ms 0.000us 0.00% 0.000us 0.000us 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 2.132ms
Self CUDA time total: 23.000us