Hello, I am toying with tensor parallelism - it seems to be working great for the most part, but I noticed that it spawns additional processes on GPU0 which can take up a substantial amount of memory.
This seems to happen after model parallelization, before starting the training loop (though the memory overhead of those additional processes grows once data is fed through the model and gradients are computed).
Output of nvidia-smi after model instantiation but before parallelization:

Output of nvidia-smi after after calls to parallelize_module:
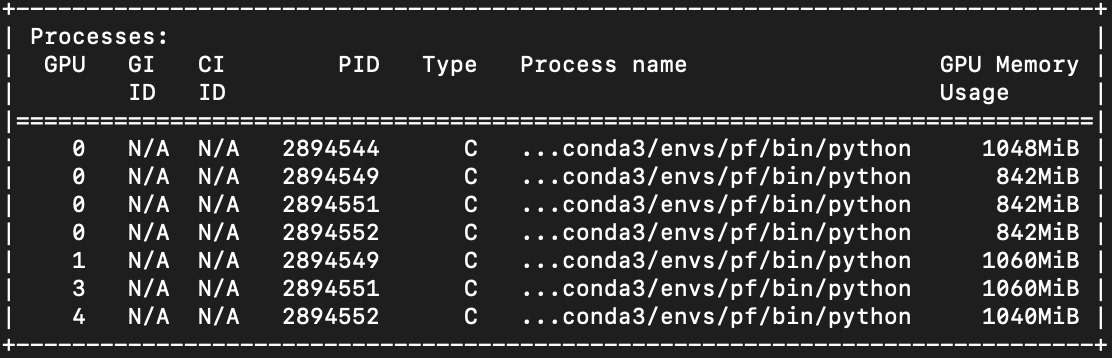
Output of nvidia-smi during training loop:
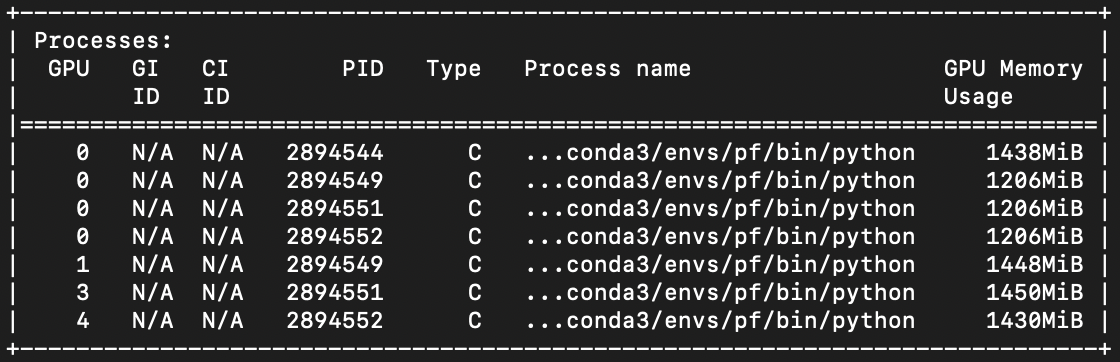
Here is a self-contained script that reproduces this:
import torch
import time
from torch.distributed.tensor.parallel import (
parallelize_module,
ColwiseParallel,
RowwiseParallel,
)
from torch.distributed import device_mesh, get_world_size, init_process_group, get_rank
from torch.utils.data import Dataset, DataLoader
from torch.optim import Adam
from tqdm.auto import tqdm
import numpy as np
class TestModule(torch.nn.Module):
def __init__(self, Nin, Nmid, Nout):
super().__init__()
self.l1 = torch.nn.Linear(Nin, Nmid)
self.l2 = torch.nn.Linear(Nmid, Nout)
self.nonlin = torch.nn.Softmax()
def forward(self, input):
mid = self.l1(input)
mid = self.nonlin(mid)
out = self.l2(mid)
out = self.nonlin(out)
return out
class TestDataset(Dataset):
def __init__(self, size_in, size_out, length):
super().__init__()
self.length = length
self.size_in = size_in
self.size_out = size_out
def __len__(self):
return self.length
def __getitem__(self, idx):
inp = np.float32(np.random.randn(self.size_in))
out = np.float32(np.random.randn(self.size_out))
return inp, out
init_process_group()
rank = get_rank()
torch.set_default_device(rank)
in_d = 1024
mid_d = 1024
out_d = 1024
d_len = 1000000
model = TestModule(in_d, mid_d, out_d)
mesh = device_mesh.init_device_mesh("cuda", (get_world_size(),))
parallelize_module(
model.l1,
device_mesh=mesh,
parallelize_plan=ColwiseParallel(),
)
parallelize_module(
model.l2,
device_mesh=mesh,
parallelize_plan=RowwiseParallel(),
)
dataset = TestDataset(in_d, out_d, length=d_len)
dataloader = DataLoader(dataset, batch_size = 128)
optimizer = Adam(model.parameters(), lr = .001)
for I, O in tqdm(dataloader):
print(I.cuda().device)
optimizer.zero_grad()
out = model(I)
loss = ((out - O)**2).sum()
loss.backward()
optimizer.step()
Run via torchrun --nproc-per-node=4 simple_tp_test.py