We are using MemoryViz tool to profile the GPU utilization of our application, following the “Understanding GPU Memory” blogpost.
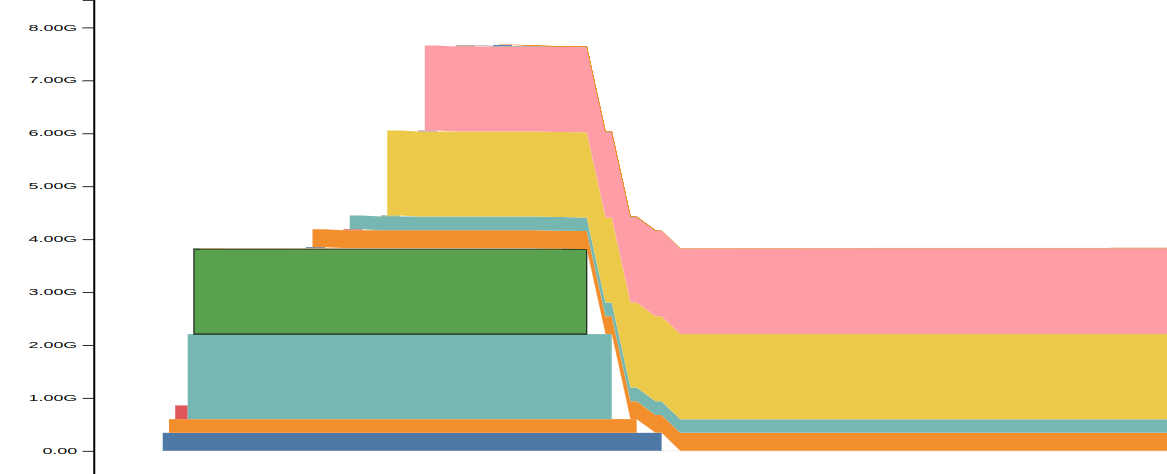
This tool has helped us identify this pattern at the very beginning of an epoch:
All the big chunks of memory are input tensors. The short-lived ones (on the left) are the tensors loaded in GPU pre-shuffling. Then we shuffle those tensors on every epoch using something like below, and new sorted vectors are created, which persist through the epoch.
class CustomDataloader:
...
if self.shuffle:
permutation = torch.randperm(self.data_len)
self.data = [tensor[permutation] for tensor in self.data]
Our understanding of the previous plot is that some tensors (e.g. light blue, dark green) are cleaned by the Garbage Collector after they are replaced with the sorted versions (e.g. yellow, pink).
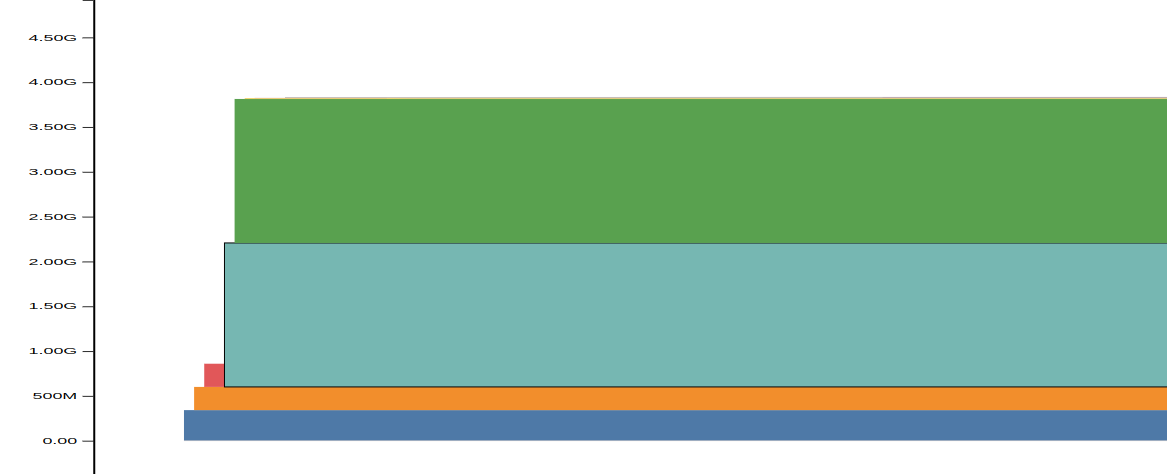
If we disable shuffling on every epoch (which happens on the __iter__() call of our DataLoader), the memory utilization does not have this spike:
Would there be any way to do the tensor shuffling in-place, so that there is no duplication of the tensors, generating the undesired and temporary peak in memory utilization?
Thanks in advance!
Further context:
We are training a model using tabular data stored in several GBs of parquet files.
After initially using PyTorch’s DataLoader with a custom Dataset implementation, we ended up implementing our own DataLoader too, because the random access to tensor positions with the __getitem__() call was too slow for us.
Our custom implementation loads the whole Parquet dataset into GPU tensors at once, and then the DataLoader iterator __next__() call returns a batch of elements by slicing the tensors through the appropriate indices.
As I understand it, self.data is a list of (references to) tensors. That
list holds on to those references until such time as the list itself is released.
This doesn’t happen until the full list comprehension has completed, at
which time the reassignment of self.data permits the original list and the
tensors it references to be freed. So you basically have two copies of
each tensor in memory until the full list comprehension is finished.
Try something like:
for i, t in enumerate (self.data):
self.data[i] = t[permutation]
As soon as self.data[i] is reassigned (within the loop), the tensor to which self.data[i] refers can be freed from memory (without waiting for the full
loop to finish).
Thank you both!
It is not exactly what I had in mind, but they are both definitely good tips! I was expecting PyTorch to have a functionality that allowed sorted views of an existing vector, or something on that line, but probably nothing like that exists and/or is feasible.
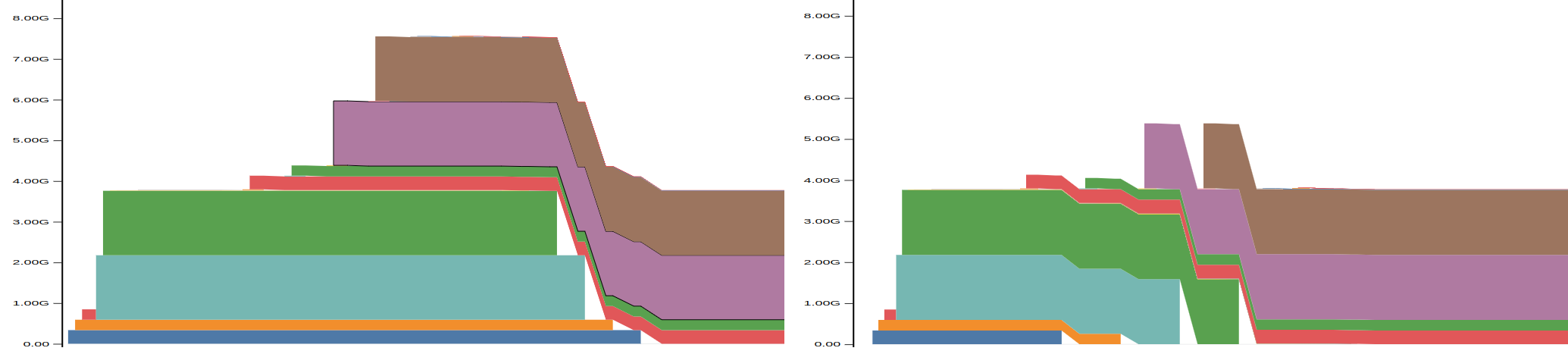
@KFrank I’ve tested your suggestion with good results. Now the maximum GPU utilization is bounded by the largest vector to sort (left is the list-comprehension implementation, right is the for-loop one).
Just in case this ends up being useful to somebody else, we iterated on top of this to do per-dimension shuffling instead of per-tensor shuffling.
Our data are 2D tensors, where each row represents an instance in the dataset, and each column is a different feature. By shuffling each feature individually instead of the whole tensor together, we reduced our peak memory utilization even further (left is the per-tensor for-loop, right is the per-feature for-loop).
The general idea is we ended up having something like this:
for tensor_idx in range(len(self.data)):
for feature_idx in range(self.data[tensor_idx].shape[1]):
tensor = self.data[tensor_idx][:, feature_idx]
self.data[tensor_idx][:, feature_idx] = tensor[permutation]
Performance-wise, execution times of all implementations are identical.