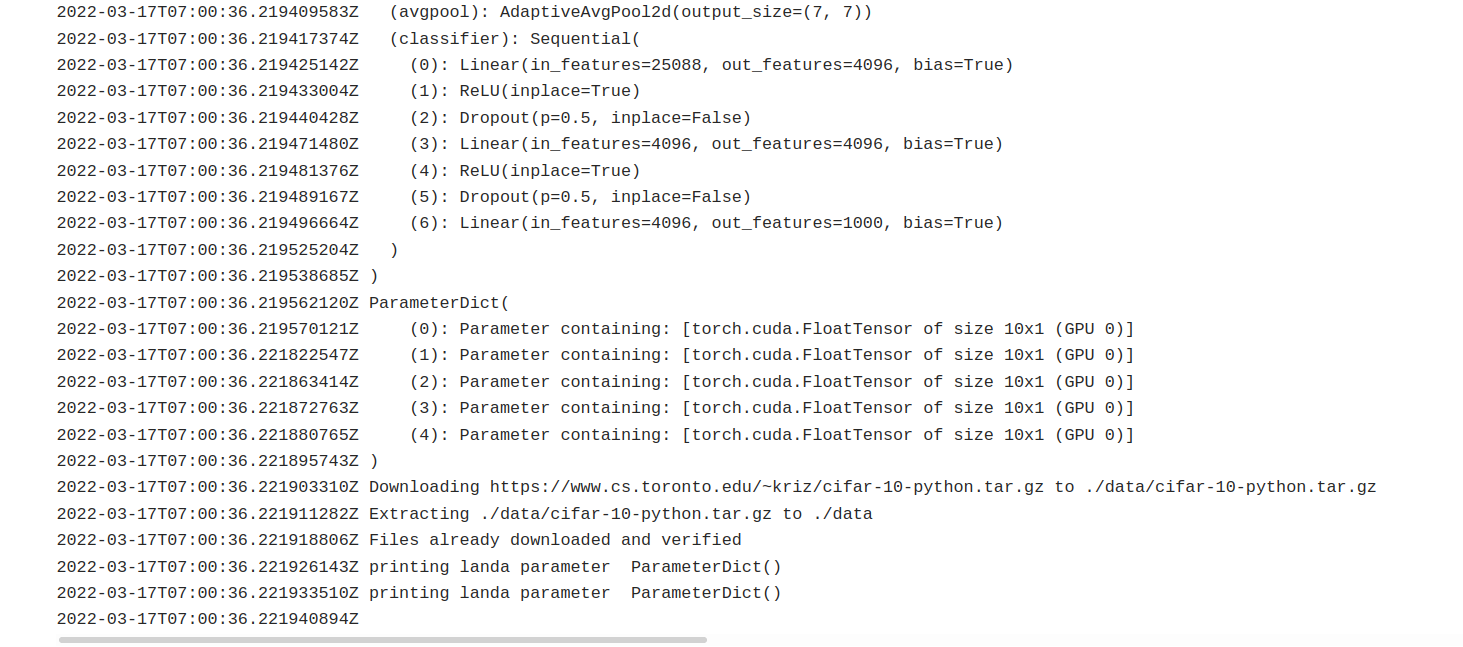
@ptrblck I provided a minimal case of my code that can be run. I put two print function in the class FeatureExtractor where I want to display the content of the parameter called graph_landas. Also, I create the parameter before wrapping it by nn.DataParallel.
Thank you in advance for your attention given to my issue.
from torch import nn
from torchvision import models
from torchvision import datasets
from torchvision import transforms
from PIL import Image
import torch
from torch import optim
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class FeatureExtractor():
def __init__(self):
self.gradients = []
def save_gradient(self, grad):
self.gradients.append(grad)
def __call__(self, x, model, graph_landas=None):
self.gradients = []
featuremaps = []
labels = x[1]
x = x[0]
print('printing landa parameter ', graph_landas)
graph_landas = graph_landas.to(x.device)
class_landas = None
for class_index in [0,1,2,3,4]:
class_index = str(class_index)
if class_landas == None:
class_landas = graph_landas[class_index]
else:
class_landas = torch.concat((class_landas, graph_landas[class_index]), 1)
print('landa belonging to each class \n', class_landas)
return featuremaps, x
class create_modifiedCNN(nn.Module):
def __init__(self, model):
super(create_modifiedCNN, self).__init__()
self.modified_cnn = model
self.feature_extractor = FeatureExtractor()
num_classes = 5
self.landa = nn.ParameterDict({
str(class_index) : nn.Parameter(torch.ones((10,1),device=device),requires_grad=True)
for class_index in range(num_classes)
})
def __call__(self, data):
featuremaps = []
for name, module in self.modified_cnn._modules.items():
if name == 'features':
featuremaps, x = self.feature_extractor(data, self.modified_cnn.features, self.landa)
elif "avgpool" in name.lower():
x = module(x)
x = x.view(x.size(0), -1)
else:
x = module(x)
return featuremaps, x
model = models.vgg16(pretrained=True)
out_feature = 5
in_feature = model.classifier[6].in_features
model.classifier[6] = nn.Linear(in_features=in_feature, out_features=out_feature, bias=True)
modified_model = torch.nn.DataParallel(create_modifiedCNN(model))
modified_model = modified_model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer_specs = [{'params': modified_model.module.landa[class_index]}
for class_index in modified_model.module.landa.keys()]
optimizer = optim.Adam(optimizer_specs, lr=0.1)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
#### Creating data transformation
image_size = 128
data_transform = {'train': transforms.Compose([
transforms.Resize((image_size, image_size), Image.BILINEAR),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize((image_size, image_size), Image.BILINEAR),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize((image_size, image_size), Image.BILINEAR),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
### Creating dataloader
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=data_transform['train'])
train_loader = torch.utils.data.DataLoader(trainset, batch_size=1,shuffle=True, num_workers=1)
testset = datasets.CIFAR10(root='./data', train=False,download=True, transform=data_transform['test'])
test_loader = torch.utils.data.DataLoader(testset, batch_size=1,shuffle=False, num_workers=1)
dataloaders = {'train': train_loader, 'test': test_loader}
### Feeding the model with images
for inputs, labels in dataloaders['train']:
optimizer.zero_grad()
class_index = labels
_, modified_output = modified_model((inputs,class_index))