I’m new to deep learning (image classification). I finetune a resnet50 model by replacing the top layer with my own sequential layer to classify 10 plant diseases. I only take the gradient of the sequential layer and set the other to false. The test loss seemed to increase as soon as it starts. Below are the pieces of information that may help:
- Model: Resnet50 (pre-trained weights from ImageNet)
- Batch Size: 10
- Optimizer: Adam
- Learning rate: 0.001
- Loss: NLLLoss
- Pytorch 1.5+cu101
- Python 3.6.1
- VS Code
- 100 training images/class
- 40 test images/class
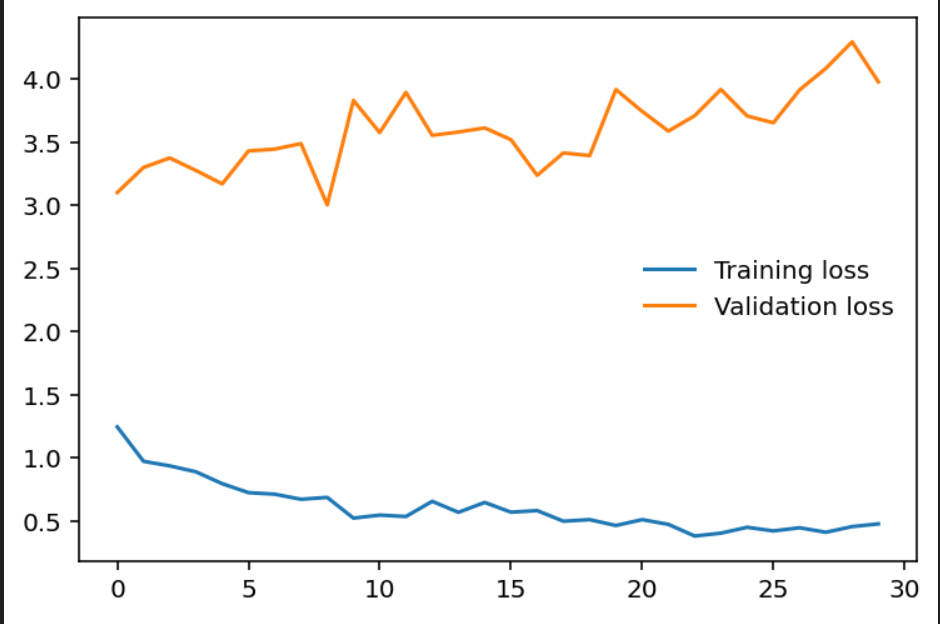
Train-test loss of 30 epochs
# Freeze parameters so we don't backprop through them
for param in model.parameters():
param.requires_grad = False
out_features = 10
hidden_layers = 1000
from collections import OrderedDict
classifier = nn.Sequential(OrderedDict([
('fc1', nn.Linear(model.fc.in_features, hidden_layers)),
('relu', nn.ReLU()),
('fc2', nn.Linear(hidden_layers, out_features)),
('output', nn.LogSoftmax(dim=1))
]))
model.fc = classifier
#writer = SummaryWriter('C:/Users/User/Desktop/Health-ID-Beta-v1/weights/resnet18/Log')
#Loss function
criterion = nn.NLLLoss()
#Gradient descent function applied only on the new classifier
#optimizer = optim.SGD(model.fc.parameters(), lr=0.001, momentum=0.9, nesterov=True )
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
epochs = 400
train_losses, test_losses = [], []
valid_loss_min = np.Inf
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
#Load the images and labels to gpu
images, labels = images.to(device), labels.to(device)
start = time.time()
# Clear the gradients, do this because gradients are accumulated
optimizer.zero_grad()
# Forward pass, then backward pass, then update weights
output = model(images)
#Calculate the loss with NLLLoss function
loss = criterion(output, labels)
#Calculate the gradient
loss.backward()
#Update the weights for the new classifier
optimizer.step()
running_loss += loss.item()
else:
## TODO: Implement the validation pass and print out the validation accuracy
test_loss = 0
accuracy = 0
with torch.no_grad():
model.eval()
for images, labels in testloader:
#Load the images and labels to GPU memory.
images, labels = images.to(device), labels.to(device)
#Forward Pass
output = model.forward(images)
#Calculate the probability from log-softmax using exponential function.
ps = torch.exp(output)
#Get the loss from the test set using nn.LLLoss()
test_loss += criterion(output, labels)
#Get the highest k value from the output
top_p, top_class = ps.topk(1, dim=1)
#Compare the predicted classes with the labels.
equals = top_class == labels.view(*top_class.shape)
#Finding the mean of equals to obtain the accuracy.
accuracy += torch.mean(equals.type(torch.FloatTensor))
model.train()
train_losses.append(running_loss/len(trainloader))
test_losses.append(test_loss/len(testloader))
print(f"Device = {device}; Time per batch: {(time.time() - start)/3:.3f} seconds")
print("Epoch: {}/{}.. ".format(e+1, epochs),
"Training Loss: {:.3f}.. ".format(train_losses[-1]),
"Test Loss: {:.3f}.. ".format(test_losses[-1]),
"Test Accuracy: {:.3f}".format(accuracy/len(testloader)))
if test_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
test_loss))
torch.save(model.state_dict(), 'weights/resnet-50/Health-ID-Beta-v1-720z720-Test.pt')
valid_loss_min = test_loss
Is this overfit? How can I improve it?