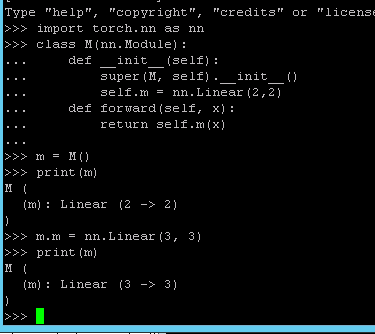
hi, i am trying to finetune the resnet model with my own data,i follow the imagenet folders main.py example to modify the fc layer in this way, i only finetune in resnet not alexnet
def main():
global args, best_prec1
args = parser.parse_args()
# create model
if args.pretrained:
print("=> using pre-trained model '{}'".format(args.arch))
model = models.__dict__[args.arch](pretrained=True)
#modify the fc layer
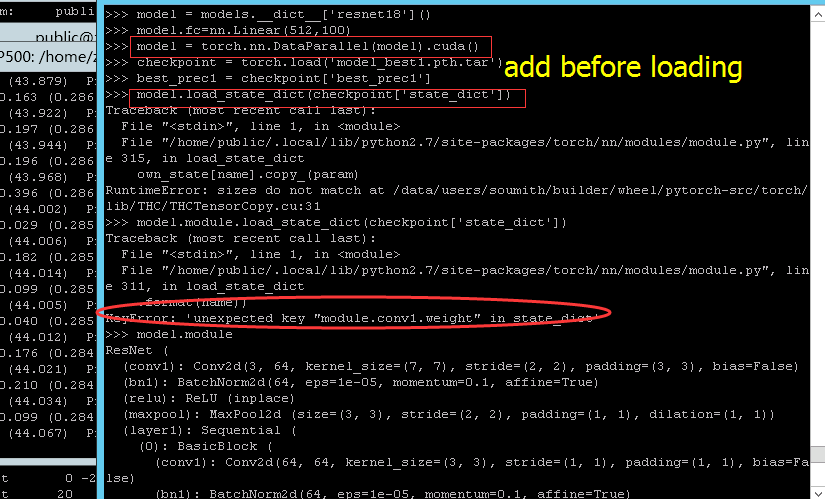
model.fc=nn.Linear(512,100)
else:
print("=> creating model '{}'".format(args.arch))
model = models.__dict__[args.arch]()
if args.arch.startswith('alexnet') or args.arch.startswith('vgg'):
model.features = torch.nn.DataParallel(model.features)
model.cuda()
else:
model = torch.nn.DataParallel(model).cuda()
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
print("=> loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
cudnn.benchmark = True
the other code remain same as the imagenet main.py
https://github.com/pytorch/examples/blob/master/imagenet/main.py
and when testing the model i trained ,i found the fc layer is still 1000 kinds
,i struggle to figure it out for a long time ,but it still the same ,i dont why
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU (inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential (
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): BasicBlock (
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU (inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
)
)
(avgpool): AvgPool2d (
)
(fc): Linear (512 -> 1000)
)
)
here is my testing code:
import torch
import torch.nn as nn
#from __future__ import print_function
import argparse
from PIL import Image
import torchvision.models as models
import skimage.io
from torch.autograd import Variable as V
from torch.nn import functional as f
from torchvision import transforms as trn
# define image transformation
centre_crop = trn.Compose([
trn.ToPILImage(),
trn.Scale(256),
trn.CenterCrop(224),
trn.ToTensor(),
trn.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
filename=r'2780-0-20161221_0001.jpg'
img = skimage.io.imread(filename)
x = V(centre_crop(img).unsqueeze(0), volatile=True)
model = models.__dict__['resnet18']()
model = torch.nn.DataParallel(model).cuda()
checkpoint = torch.load('model_best1.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
best_prec1 = checkpoint['best_prec1']
logit = model(x)
print(logit)
print(len(logit))
h_x = f.softmax(logit).data.squeeze()
anyone can tell me where do i go wrong and how to extrac the last averarge pooling layer features ,thank you so much!