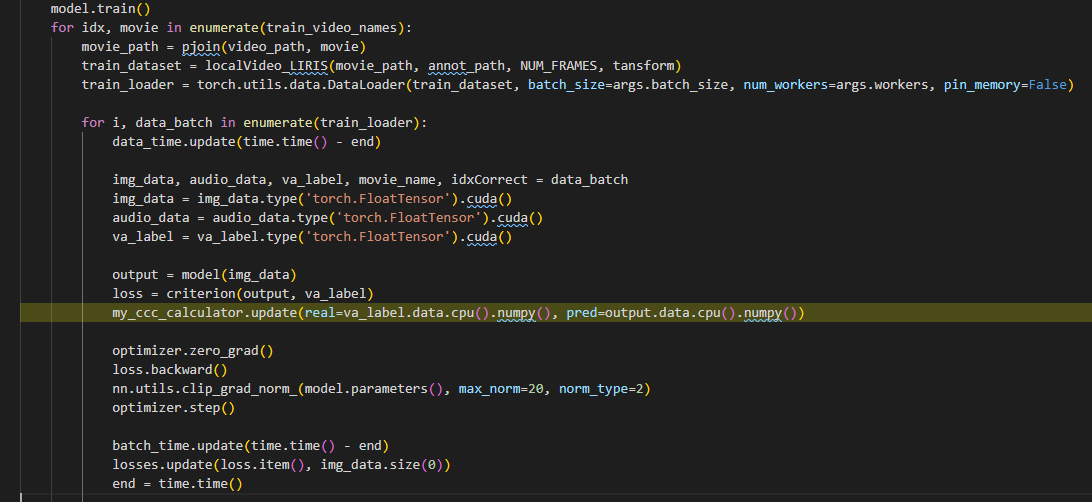
content
The metrics of train() is not bad. But when it comes to validating/eval mode, the metrics result is disaster. So I try to print the predict value as the graph below.
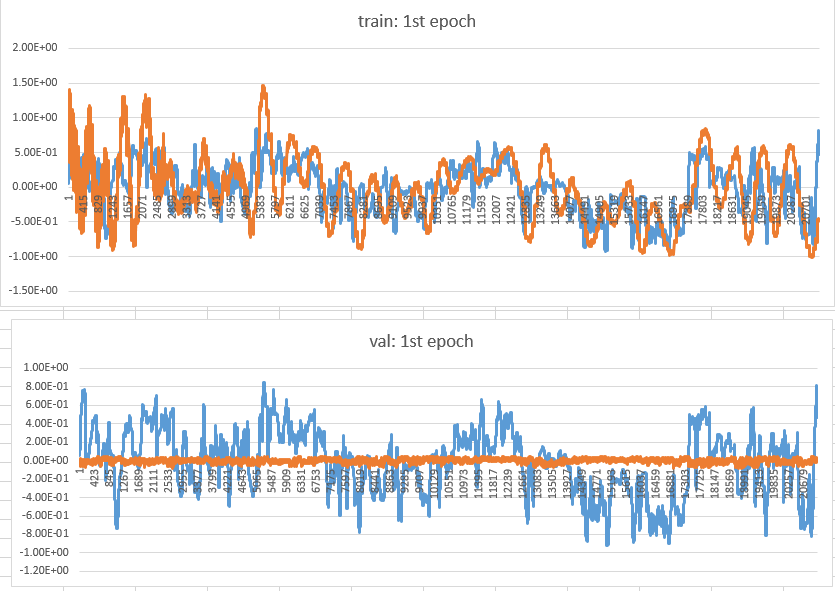
the blue one is the ground truth, and the orange one is my prediction.
From the graph, the output of the model in validating mode is almost the same every time. So I’m wondering that why it happened and what can I do to fix it? Here is parts of my code. In case of overfitting, I use the same dataset in training and validating actually. But the output of validating is still the same.
Pseudo code:
def train(train_inf, model, criterion, optimizer):
# some not important code is ignored
model.train()
for idx, movie in enumerate(train_video_names):
movie_path = os.path.join(video_path, movie)
train_dataset = video_dataset(movie_path, annot_path)
train_loader = DataLoader(train_dataset, batch_size=4, num_workers=4)
for i, data_batch in enumerate(train_loader):
img_data, label = data_batch
img_data = img_data.type(‘torch.FloatTensor’).cuda()
label = label.type(‘torch.FloatTensor’).cuda()
output = model(img_data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=20, norm_type=2)
optimizer.step()
def validate(val_inf, model, criterion, optimizer):
# some not important code is ignored
model.eval()
for idx, movie in enumerate(val_video_names):
movie_path = os.path.join(video_path, movie)
train_dataset = video_dataset(movie_path, annot_path)
train_loader = DataLoader(val_dataset, batch_size=4, num_workers=4)
for i, data_batch in enumerate(val_loader):
img_data, label = data_batch
img_data = img_data.type(‘torch.FloatTensor’).cuda()
label = label.type(‘torch.FloatTensor’).cuda()
output = model(img_data)
loss = criterion(output, label)
def main():
train(train_inf, model, criterion, optimizer)
valdate(val_inf, model, criterion, optimizer)
Notes:
- I have already make sure that the data in validation mode is not the same, even not close, though the result is still almost the same.
- Because I use the same data in train mode and eval mode, so it should not be the problem of overfitting.
- I use the transformer architecture. I don’t think that it gonna make this thing happen, just trying to provide more information.
Thanks for your help. Any kind of suggestion will be my pleasure.