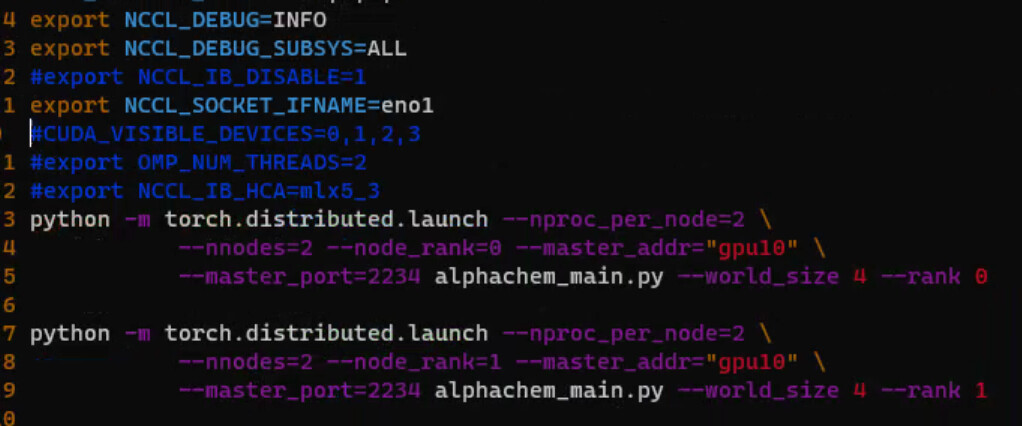
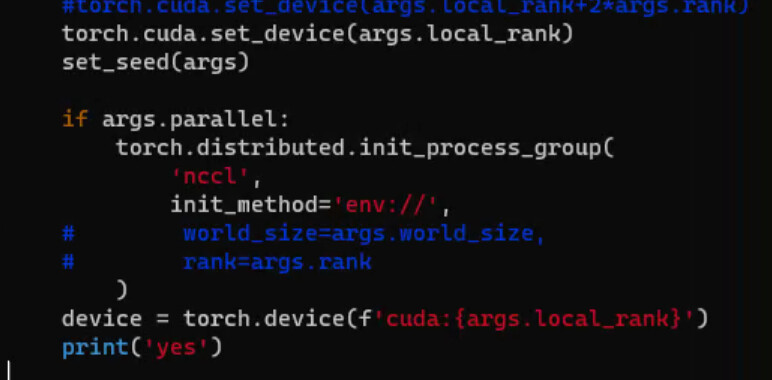
If I understand correctly, you are trying to train with 4 GPUs, 2 on one machine and 2 on another machine? If this is the case, then you will need to launch your training script separately on each machine. The node_rank for launch script on the first machine should be 0 and node_rank passed to the launch script on the second machine should be 1. It seems here like you are passing 2 separate node_ranks for processes launched on the same machine.
We don’t provide a way of doing this natively in PyTorch. Writing a simple bash script to do this should be doable though (take a list of hostnames, ssh into each one, copy over pytorch program, and run). You could also use slurm/mpirun if those are available in your environment.