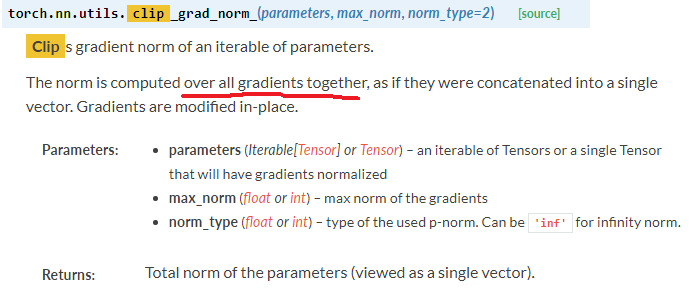
To find the cause of the problem, I did the following experiments. I found something interesting.
import torch
import torch.nn as nn
import torch.optim as optim
class ModelA(nn.Module):
"""docstring for ModelA"""
def __init__(self):
super(ModelA, self).__init__()
self.fc1 = nn.Linear(3, 3)
self.fc2 = nn.Linear(3, 3)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
class ModelB(nn.Module):
"""docstring for ModelA"""
def __init__(self):
super(ModelB, self).__init__()
self.fc1 = nn.Linear(3, 3)
self.fc2 = nn.Linear(3, 3)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
class Model_comb(nn.Module):
"""docstring for Model_com"""
def __init__(self):
super(Model_comb, self).__init__()
self.modelA = ModelA()
self.modelB = ModelB()
def forward(self, x):
x = self.modelA(x)
x = self.modelB(x)
return x
class Model_ALL(nn.Module):
"""docstring for ModelA"""
def __init__(self):
super(Model_ALL, self).__init__()
self.fc1 = nn.Linear(3, 3)
self.fc2 = nn.Linear(3, 3)
self.fc3 = nn.Linear(3, 3)
self.fc4 = nn.Linear(3, 3)
# self.fc5 = nn.Linear(3, 3)
# self.fc6 = nn.Linear(3, 3)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
x = self.fc4(x)
return x
model_A = ModelA()
model_B = ModelB()
model_comb = Model_comb()
model_ALL = Model_ALL()
optimizer_A = optim.SGD(model_A.parameters(), lr=0.01)
optimizer_B = optim.SGD(model_B.parameters(), lr=0.01)
optimizer_comb = optim.SGD(model_comb.parameters(), lr=0.01)
optimizer_ALL = optim.SGD(model_ALL.parameters(), lr=0.01)
criterion_A = nn.CrossEntropyLoss()
criterion_B = nn.CrossEntropyLoss()
criterion_comb = nn.CrossEntropyLoss()
criterion_ALL = nn.CrossEntropyLoss()
inputs = torch.rand(2, 3)
labels = torch.tensor([0, 1])
model_comb.modelA.fc1.weight = model_ALL.fc1.weight
model_comb.modelA.fc1.bias = model_ALL.fc1.bias
model_comb.modelA.fc2.weight = model_ALL.fc2.weight
model_comb.modelA.fc2.bias = model_ALL.fc2.bias
model_comb.modelB.fc1.weight = model_ALL.fc3.weight
model_comb.modelB.fc1.bias = model_ALL.fc3.bias
model_comb.modelB.fc2.weight = model_ALL.fc4.weight
model_comb.modelB.fc2.bias = model_ALL.fc4.bias
print('ALL:')
print('ALL parameters before zero_grad:')
for para in model_ALL.parameters():
print(para.data)
print('Combine parameters before zero_grad:')
for para in model_comb.parameters():
print(para.data)
optimizer_ALL.zero_grad()
print('ALL parameters after zero_grad:')
for para in model_ALL.parameters():
print(para.data)
outputs_all = model_ALL(inputs)
print('ALL output:')
print(outputs_all)
loss_ALL = criterion_ALL(outputs_all, labels)
print('ALL loss:')
print(loss_ALL)
loss_ALL.backward()
torch.nn.utils.clip_grad_norm_(model_ALL.parameters(), 1)
print('ALL parameters after clip, before update:')
for para in model_ALL.parameters():
print(para.data)
optimizer_ALL.step()
print('ALL parameters after update:')
for para in model_ALL.parameters():
print(para.data)
print('Combine:')
optimizer_comb.zero_grad()
print('Combine parameters after zero_grad:')
for para in model_comb.parameters():
print(para.data)
outputs_comb = model_comb(inputs)
print('Combine output:')
print(outputs_comb)
loss_comb = criterion_comb(outputs_comb, labels)
print('Combine loss:')
print(loss_comb)
loss_comb.backward()
torch.nn.utils.clip_grad_norm_(model_comb.parameters(), 1)
print('Combine parameters after clip, before update:')
for para in model_comb.parameters():
print(para.data)
optimizer_comb.step()
print('Combine parameters after update:')
for para in model_comb.parameters():
print(para.data)
The results are as follow,
ALL:
ALL parameters before zero_grad:
tensor([[-0.4071, -0.4386, -0.5222],
[-0.0855, 0.2986, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1182, -0.5761])
tensor([[ 0.1895, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2463]])
tensor([-0.1314, -0.2521, 0.0374])
tensor([[ 0.2153, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2757, -0.0736, 0.2502]])
tensor([-0.2666, 0.5407, -0.1402])
tensor([[-0.1796, -0.1530, 0.5736],
[-0.3743, -0.4519, 0.2864],
[-0.2824, -0.3592, 0.2727]])
tensor([ 0.2545, 0.1062, 0.5753])
Combine parameters before zero_grad:
tensor([[-0.4071, -0.4386, -0.5222],
[-0.0855, 0.2986, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1182, -0.5761])
tensor([[ 0.1895, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2463]])
tensor([-0.1314, -0.2521, 0.0374])
tensor([[ 0.2153, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2757, -0.0736, 0.2502]])
tensor([-0.2666, 0.5407, -0.1402])
tensor([[-0.1796, -0.1530, 0.5736],
[-0.3743, -0.4519, 0.2864],
[-0.2824, -0.3592, 0.2727]])
tensor([ 0.2545, 0.1062, 0.5753])
ALL parameters after zero_grad:
tensor([[-0.4071, -0.4386, -0.5222],
[-0.0855, 0.2986, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1182, -0.5761])
tensor([[ 0.1895, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2463]])
tensor([-0.1314, -0.2521, 0.0374])
tensor([[ 0.2153, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2757, -0.0736, 0.2502]])
tensor([-0.2666, 0.5407, -0.1402])
tensor([[-0.1796, -0.1530, 0.5736],
[-0.3743, -0.4519, 0.2864],
[-0.2824, -0.3592, 0.2727]])
tensor([ 0.2545, 0.1062, 0.5753])
ALL output:
tensor([[ 0.1584, -0.0804, 0.4186],
[ 0.1634, -0.0734, 0.4245]])
ALL loss:
tensor(1.2453)
ALL parameters after clip, before update:
tensor([[-0.4071, -0.4386, -0.5222],
[-0.0855, 0.2986, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1182, -0.5761])
tensor([[ 0.1895, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2463]])
tensor([-0.1314, -0.2521, 0.0374])
tensor([[ 0.2153, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2757, -0.0736, 0.2502]])
tensor([-0.2666, 0.5407, -0.1402])
tensor([[-0.1796, -0.1530, 0.5736],
[-0.3743, -0.4519, 0.2864],
[-0.2824, -0.3592, 0.2727]])
tensor([ 0.2545, 0.1062, 0.5753])
ALL parameters after update:
tensor([[-0.4072, -0.4386, -0.5222],
[-0.0855, 0.2985, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1181, -0.5761])
tensor([[ 0.1896, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2462]])
tensor([-0.1316, -0.2523, 0.0376])
tensor([[ 0.2154, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2759, -0.0736, 0.2501]])
tensor([-0.2666, 0.5408, -0.1396])
tensor([[-0.1801, -0.1520, 0.5734],
[-0.3749, -0.4506, 0.2862],
[-0.2813, -0.3616, 0.2731]])
tensor([ 0.2563, 0.1086, 0.5711])
Combine:
Combine parameters after zero_grad:
tensor([[-0.4072, -0.4386, -0.5222],
[-0.0855, 0.2985, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1181, -0.5761])
tensor([[ 0.1896, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2462]])
tensor([-0.1316, -0.2523, 0.0376])
tensor([[ 0.2154, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2759, -0.0736, 0.2501]])
tensor([-0.2666, 0.5408, -0.1396])
tensor([[-0.1801, -0.1520, 0.5734],
[-0.3749, -0.4506, 0.2862],
[-0.2813, -0.3616, 0.2731]])
tensor([ 0.2563, 0.1086, 0.5711])
Combine output:
tensor([[ 0.1613, -0.0768, 0.4129],
[ 0.1664, -0.0698, 0.4188]])
Combine loss:
tensor(1.2415)
Combine parameters after clip, before update:
tensor([[-0.4072, -0.4386, -0.5222],
[-0.0855, 0.2985, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1181, -0.5761])
tensor([[ 0.1896, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2462]])
tensor([-0.1316, -0.2523, 0.0376])
tensor([[ 0.2154, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2759, -0.0736, 0.2501]])
tensor([-0.2666, 0.5408, -0.1396])
tensor([[-0.1801, -0.1520, 0.5734],
[-0.3749, -0.4506, 0.2862],
[-0.2813, -0.3616, 0.2731]])
tensor([ 0.2563, 0.1086, 0.5711])
Combine parameters after update:
tensor([[-0.4072, -0.4386, -0.5222],
[-0.0855, 0.2985, -0.0911],
[-0.4010, 0.0293, 0.4651]])
tensor([ 0.2367, 0.1181, -0.5761])
tensor([[ 0.1896, 0.1700, 0.3264],
[-0.4208, 0.0316, -0.4164],
[ 0.0074, -0.1777, 0.2462]])
tensor([-0.1316, -0.2523, 0.0376])
tensor([[ 0.2154, 0.0360, -0.4593],
[-0.1261, -0.5126, -0.1848],
[-0.2759, -0.0736, 0.2501]])
tensor([-0.2666, 0.5408, -0.1396])
tensor([[-0.1801, -0.1520, 0.5734],
[-0.3749, -0.4506, 0.2862],
[-0.2813, -0.3616, 0.2731]])
tensor([ 0.2563, 0.1086, 0.5711])
We can see that there is a little difference between these two cases after I excute the zero_grad() function. The loss values of two cases have little difference as well. But the final parameters of two moel are the same.