Hello everyone, we recently encountered an issue where our distributed storage system became very slow during a training process. As a result, the training speed decreased to one-fifth of its usual speed. From the monitoring data, it is evident that the main cause of this slowdown is the increased time taken for data loading, as shown in the following graph:

Due to the synchronization of Sync-BN across multiple GPUs, the forward time of our training process has also slowed down, which is expected. However, we are curious as to why the GPU utilization has not changed significantly during this period.
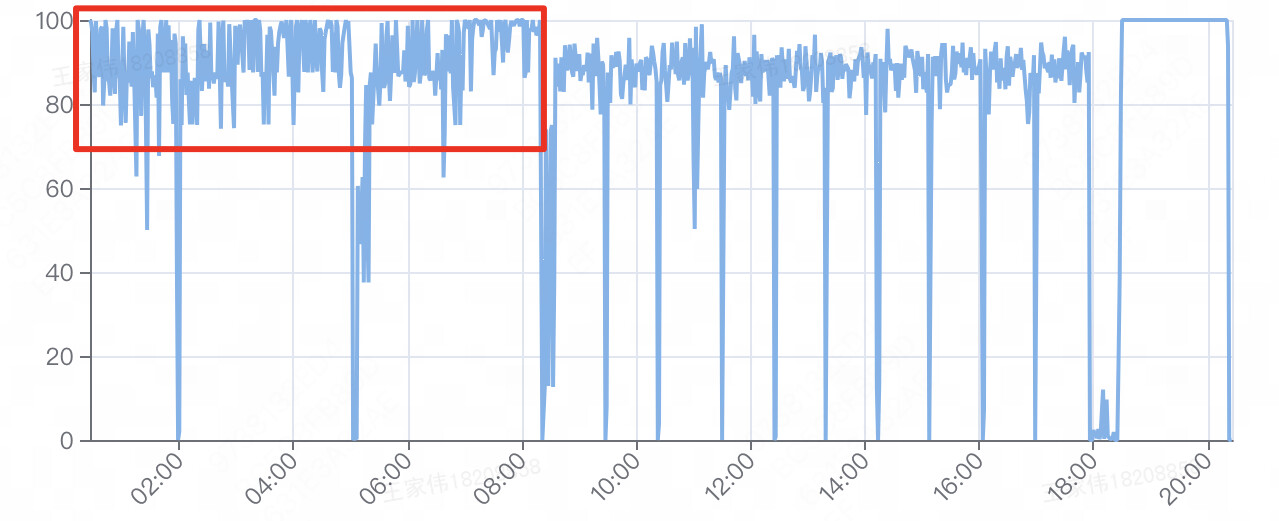
Does anyone know why this is the case? (We speculate that one possible reason is that NCCL synchronization may lead to excessively high GPU utilization, but we couldn’t find any relevant information online.)