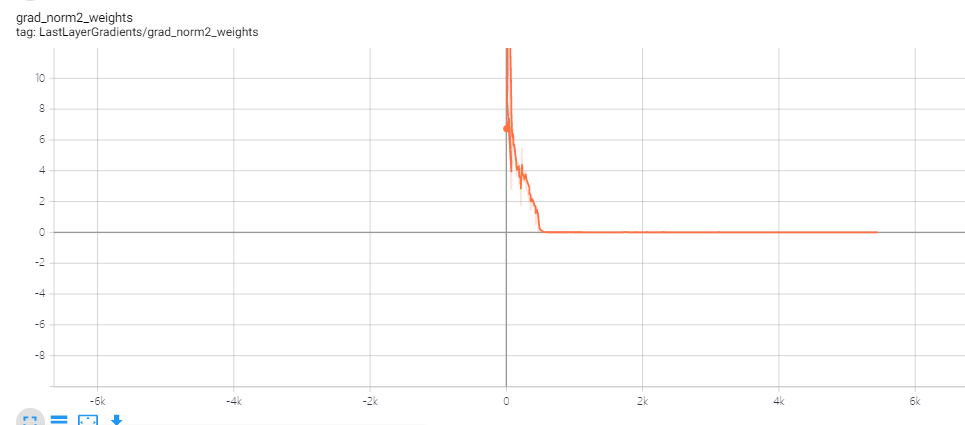
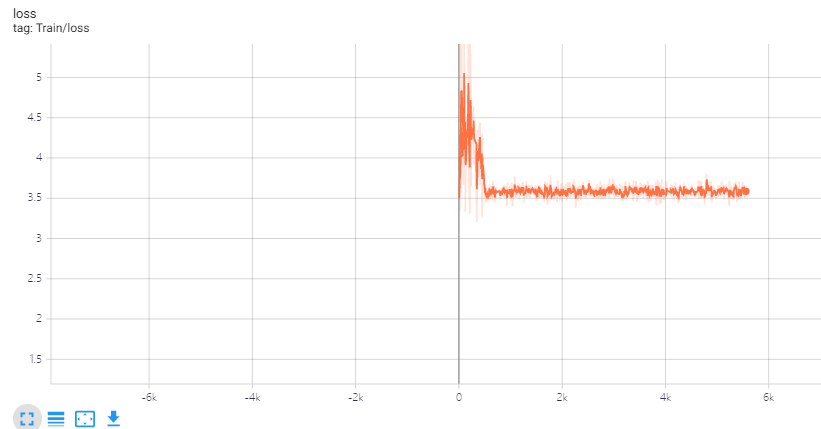
I made a inception model and train it on my image datasets.Using a learnning rate at 0.1 and using CrossEntropy as a loss function.The optimizer is SGD with momentum.
As shown in the figure above,the weight gradient drops quickly, but the loss don’t go the same.
I got confuse about it does the network trap in local optimum?
And what can I do about it? Using a larger lr or something else?
1 Like
The original Inception model was trained using the auxiliary outputs (which are also provided in the torchvision implementation) to “increase the gradient signal” as explained in the paper.
If you are not using it, I would guess the gradient might vanish at some point.
0.1 is a high learning rate, especially if you are using momentum. I looked at how googlenet (inception v1) was trained and they used SGD with initial lr 0.01 and momentum 0.9 (quick_solver.prototxt also contains the details of their learning rate decay schedule).