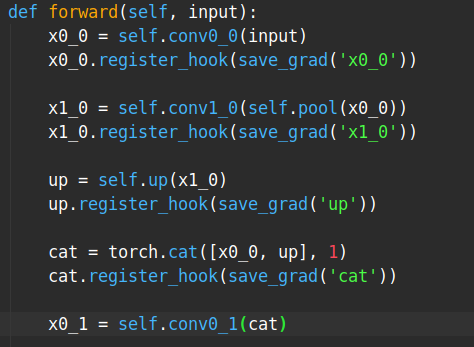
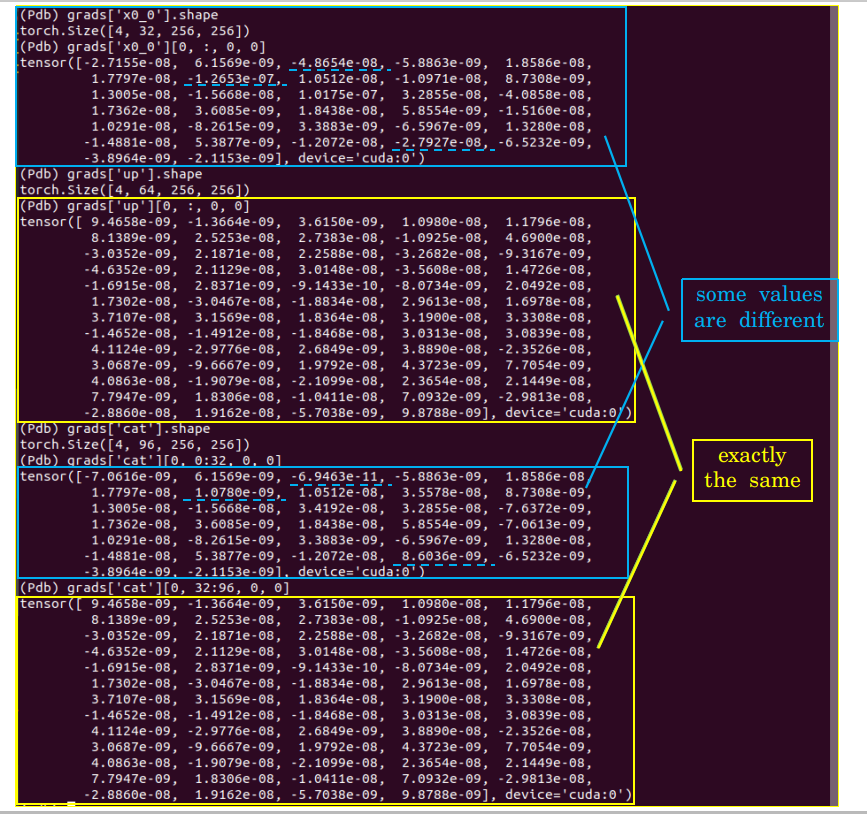
Tensor ‘x0_0’ ([4, 32, 256, 256]) and ‘up’ ([4, 64, 256, 256]) are concatenated together during the forward process. When I was checking the gradients after calling loss.backward(), I found the gradients assignment mismatch with the torch.cat() operation? Detailed results are showed as follows:
Hi,
I tried to reproduce with the following script but it works fine.
Do you have a small code sample that shows the problem?
import torch
a = torch.rand(100, 100, requires_grad=True)
b = torch.rand(100, 100, requires_grad=True)
c = torch.cat([a, b], 1)
c.retain_grad()
(c+1).backward(torch.rand(c.size()))
print((a.grad - c.grad.narrow(1, 0, 100)).abs().max())
print((b.grad - c.grad.narrow(1, 100, 100)).abs().max())
I have figured this out. That’s because Tensor ‘x0_0’ is not only concatenated with ‘up’, but also is passed to ‘x1_0’. So the final grads of ‘x0_0’ come from two parts. And the two parts grads are added directly.
Thank for your reply. And I’d like to ask where can I take a look the backward formulas of different PyTorch operations? I want to know how grads are computed for some specified functions, like F.interpolate()?
Hi,
We don’t have one rule of where the backward formulas are defined. Most of them are defined in this file and all the corresponding code is generated automatically.
For F.interpolate(), there is not one definition as it is implemented as one of many functions. You can check the interpolate implementation here to see which function is used in your case, and what is its backward.