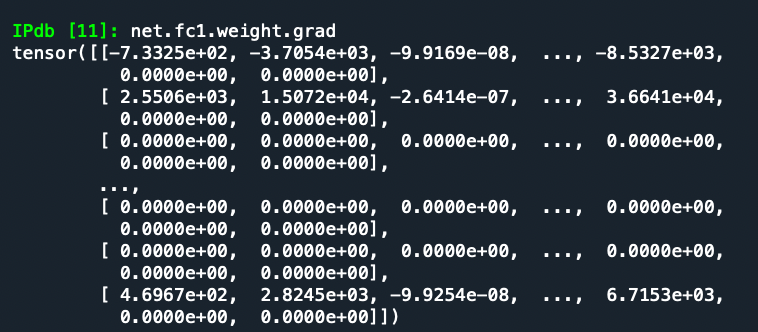
Hi, I am new to pytorch. The weights of my NN gradients become close to zero at the beginning, and my loss function does not change much. Any help or suggestions will be much appreciated.
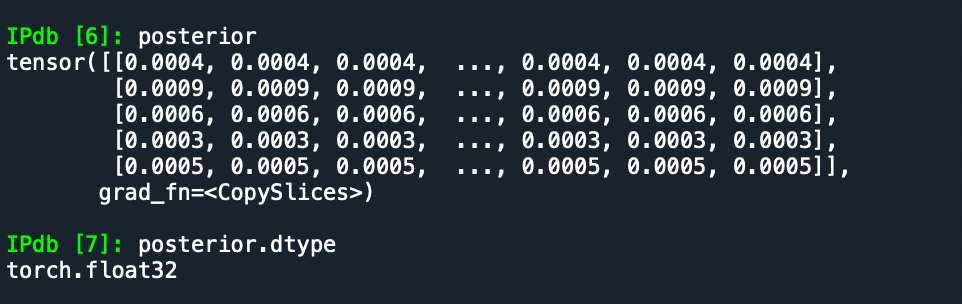
Problem description: My dataset contains two variables, namely ‘posterior’ and ‘theta’. The variable ‘posterior’ is the input of the NN, which is basically a probability distribution. As an example, For a particular observation, at the beginning, the ‘posterior’ is taken from a uniform distribution over 1801 grid points. The final output will also like a probability distribution, where 9 of the grid points will be highly probable (close to 1) and remaining close to zero.
The NN will take the posterior input and will give a matrix A at the output. Then, based on the input ‘theta’, a variable X, and then another variable y= AX will be computed and then, by doing some calculation, an updated posterior will be returned. The posterior will be updated for N samples of X. BCELoss function is used to compute the loss between the updated posterior and the label.
class model(nn.Module):
def __init__(self):
super().__init__()
self.input = nn.Linear(1801,2048)
self.fc1 = nn.Linear(2048,2048)
self.fc2 = nn.Linear(2048,2048)
self.out = nn.Linear(2048,10*100)
def forward(self,x):
x = F.relu(self.input(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.out(x)
return x
net = model()
#lossfun = nn.BCEWithLogitsLoss()
lossfun = nn.BCELoss()
optimizer = torch.optim.Adam(net.parameters(),lr = .001)
return net,lossfun,optimizer
def trainModel(train_loader,numepochs,samples,device):
net,lossfun,optimizer = createModel()
net.to(device)
losses = np.zeros(numepochs)
for epochi in range(numepochs):
batchLoss = []
for theta, posterior, label in train_loader:
theta = theta.to(device)
posterior = posterior.to(device)
label = label.to(device)
for samp in range(samples): # Iterate through the samples in X
# Computing A matrix as the NN output and do some postprocessing
A_tmp = net(posterior)
A_tmp = A_tmp.cpu()
A_shaped = A_tmp.view(-1,10,100)
A_r =A_shaped[:,:,:50]
A_i = A_shaped[:,:,50:]
A = A_r+1j*A_i
# Initializing a sample for X
X = torch.zeros((theta.shape[0],50,1),dtype = torch.cfloat)
# Computing X from theta for every data in a batchj
for i in range(theta.shape[0]):
theta_loop = theta[i,:]
received_loop = ap.arr_received_tensor(50, theta_loop, 1, 20)
X[i,:,:] = received_loop # Array received signal
#Computing y
y = A@X
posterior = torch.zeros((theta.shape[0],1801))
# Updating posterior
for i in range(y.shape[0]):
y_loop = y[i,:,:] # Grab i th y data from a batch of 32
Ry_loop = y_loop@y_loop.conj().T
posterior[i,:] = ap.op_angle_tensor(-90, 90, .1, Ry_loop, 9)[2]
print(f'Sample No: {samp}\n\n')
loss = lossfun(posterior,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
batchLoss.append(loss.item())
losses[epochi] = np.mean(batchLoss)
print(f'Loss in epoch {epochi} is {losses[epochi]}')
return losses,net ```