hello, today I train the nn.LSTM with multi-gpu by nn.DataParallel. I set the batch_size=12 in data.DataLoader, so the shape of input is (12, T, *), T represents the max frame in the 12 sentences(these 12 sentences has been padded into equal length), and * represents the dimension of the feature for each frame. the number of gpu is 3.
the model is as follows:
############################################################
train_rnn_pack_sort.py[115] 2018-55-16 09:55:20 INFO: Let’s use 3 GPUs!
train_rnn_pack_sort.py[126] 2018-55-16 09:55:20 INFO: DataParallel(
(module): LSTM(
(lstm): Sequential(
(0): LSTM(840, 256, batch_first=True, bidirectional=True)
(1): LSTM(512, 256, batch_first=True, bidirectional=True)
(2): LSTM(512, 256, batch_first=True, bidirectional=True)
(3): LSTM(512, 256, batch_first=True, bidirectional=True)
(conn): LSTM(512, 4800, batch_first=True, bidirectional=True)
)
)
)
###########################################################
the code for using the nn.DataParallel
########################################
if th.cuda.is_available():
if args.multi_gpu == 1:
if th.cuda.device_count() > 1:
logger.info(“Let’s use {} GPUs!”.format(th.cuda.device_count()))
nnet = nn.DataParallel(nnet, device_ids=[0,1,2]) # dim = 0 [30, xxx] → [10, …], [10, …], [10, …] on 3 GPUs
elif th.cuda.device_count() == 1:
logger.info(“!!!WARNINGS:Only 1 GPU detected and Let’s use the only one GPUs!!!”)
else:
logger.info(“!!!ERROR!!!”)
else:
logger.info(“!!!Training on single GPU!!!”)
else:
logger.info("!!!WARNINGS:NO GPUs detected! AND The Net Will Be Trained On CPU!!!")
logger.info(nnet)
###########################
the propagation of the model is as follows:
###########################
class LSTM(nn.Module):
def init(self, input_size, hidden_layer, hidden_size, num_classes,
rnn_type=‘lstm’, dropout=0.0, bidirect=True, residual=False):
super(LSTM, self).init()
if bidirect:
layer = [nn.LSTM( input_size=input_size, hidden_size=hidden_size, batch_first=True, bidirectional=bidirect, dropout=dropout)]
for i in range(hidden_layer):
layer.append(nn.LSTM(hidden_size2, hidden_size, batch_first=True, dropout=0.0, bidirectional=bidirect))
self.lstm = nn.Sequential(layer)
self.lstm.add_module(“conn”,nn.LSTM(hidden_size2, num_classes, batch_first=True, dropout=0.0, bidirectional=bidirect))
def forward(self, x, input_len):
max_length = x.shape[1]
x = rnn_pack.pack_padded_sequence(x, input_len, batch_first=True)
x = self.lstm(x)
out , _ = rnn_pack.pad_packed_sequence(x, total_length=max_length, batch_first=True)
return out
##########################
def train_one_epoch(nnet, criterion, optimizer, train_loader, num_parallel, is_rnn=False):
nnet.train()
pos_frames = 0.0
train_frames = 0.0
for index, (key, feats, labels, len_list) in enumerate(train_loader):
print “=============”
print key
print feats.shape ##(12,T,)
print labels.shape ##(12,T)
#print type(len_list)
#print len_list.shape
print “=============”
labels = labels.view(labels.shape[0], labels.shape[1])
input_len = np.array(len_list)
input_sort_id = np.argsort(-input_len)
input_len = input_len[input_sort_id]
feat_mat = feats[th.LongTensor(input_sort_id)]
feat_mat = Variable(feat_mat.cuda())
input_unsort_id = th.LongTensor(np.argsort(input_sort_id))
optimizer.zero_grad()
if is_rnn:
label_mat = labels.view(labels.size(0) * labels.size(1))
targets = Variable(label_mat.cuda())
out = nnet(feat_mat, input_len)
out = out[input_unsort_id]
out_num = out.shape[2]
max_frame = int(max(len_list))
.
.
.
but the error occurs:
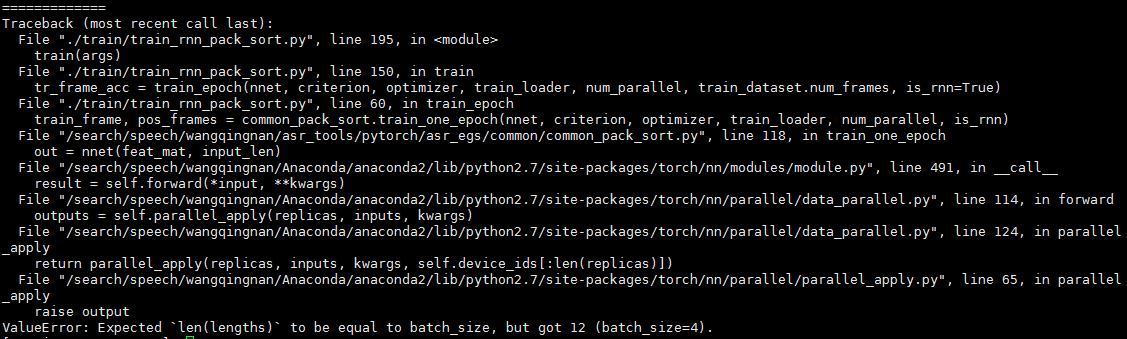
Any help would be appreciated…