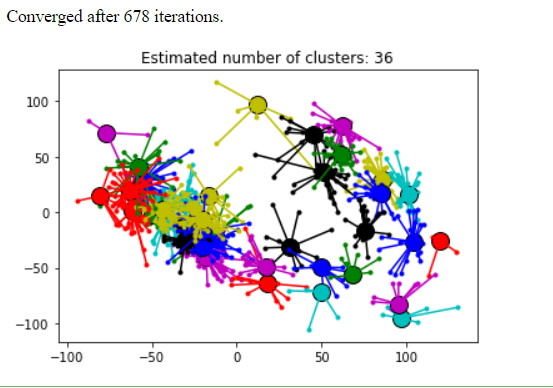
I am looking for tips regarding my code. I am interested in clustering by affinity propagation algorithm. I have a vector whose rows correspond to the observation (800) and columns correspond to features. Every time I change the number of max-iteration or any factors it gives me the same results; A large number of clusters as in the picture
from sklearn.cluster import AffinityPropagation
from itertools import cycle
import sklearn.metrics as metrics
from sklearn.datasets import make_blobs
import numpy as np
from sklearn.metrics.pairwise import cosine_distances
# Compute similarities
X=features_vector
X_norms = np.sum(X**2, axis=1)
S = - X_norms[:, np.newaxis] - X_norms[np.newaxis, :] + 2 * np.dot(X, X.T)
p = 10 * np.median(S)
# Compute Affinity Propagation
af = AffinityPropagation(random_state=5, convergence_iter=500, copy=True, damping=0.95, max_iter=5000,verbose=True, affinity = 'euclidean').fit(S, p)
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_
n_clusters_ = len(cluster_centers_indices)
#D = (S / np.min(S))
#print ("Silhouette Coefficient: %0.3f" %
# metrics.silhouette_score(D, labels, metric='precomputed'))
##############################################################################
# Plot result
import pylab as pl
from itertools import cycle
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
class_members = labels == k
cluster_center = X[cluster_centers_indices[k]]
pl.plot(X[class_members, 0], X[class_members, 1], col + '.')
pl.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
for x in X[class_members]:
pl.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col)
plt.title("Estimated number of clusters: %d" % n_clusters_)
plt.show()