I have 250+ GB of RAM and 48 GB on A6000
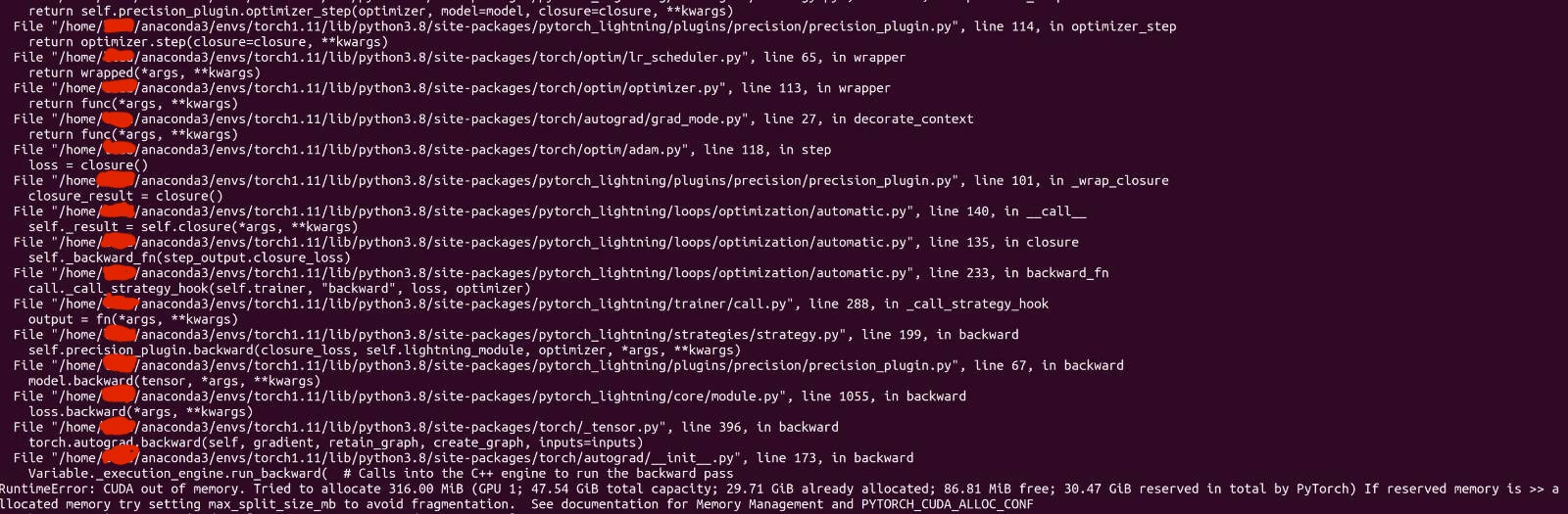
You are running out of GPU memory and would need to reduce the memory usage in each process. You could use torch.cuda.set_per_process_memory_fraction to limit the fraction per process.
Thanks. I also tried to follow this guide, but didn’t find working way to set the memory allocation strategy, can you please assist? How can I set it to heuristic?
https://iamholumeedey007.medium.com/memory-management-using-pytorch-cuda-alloc-conf-dabe7adec130
One more thing. Suppose I have a training that may potentially use all the 48 GB of the GPU memory, in such case I will set the torch.cuda.set_per_process_memory_fraction to 1. It starts running knowing that it can allocate all the memory, but it didn’t yet. Another process starts and tries to allocate some significant chunk of memory, which process will be killed?
I also didn’t mentioned that oom killer kills the process although the process does not consume system RAM, it consumes GPU RAM, can oom killer do it’s scoring based on GPU RAM?
Here is the dmesg log for killed trainings.
[1049496.935479] **Out of memory**: Killed process 3718080 (python) total-vm:40401236kB, anon-rss:6162012kB, file-rss:68616kB, shmem-rss:287344kB, UID:1001 pgtables:18492kB oom_score_adj:0
[1049506.723130] **Out of memory**: Killed process 3717888 (python) total-vm:40402784kB, anon-rss:6163596kB, file-rss:68064kB, shmem-rss:313964kB, UID:1001 pgtables:18548kB oom_score_adj:0
[1049519.565244] **Out of memory**: Killed process 3717292 (python) total-vm:40445528kB, anon-rss:6206448kB, file-rss:68480kB, shmem-rss:366624kB, UID:1001 pgtables:18736kB oom_score_adj:0
[1049535.486537] **Out of memory**: Killed process 3718466 (python) total-vm:40458440kB, anon-rss:6219144kB, file-rss:68788kB, shmem-rss:343796kB, UID:1001 pgtables:18716kB oom_score_adj:0
Unclear, but I would assume the process trying to allocate memory and failing will raise the error.
I doubt it as the OS doesn’t care about GPU memory but will kill the process if it’s running out of host RAM.
That is strange, as the python processes that had been killed by oom, were not using System RAM, in fact as we may see in the image attached, the GPU memory is consumed. In fact We’ve never used even 50% of the System RAM on the machine.
Can pytorch set the OOM score somehow to influence the OOM Killer behaviour ?
This is impossible as Python will of course use system RAM to store its runtime, variables etc.
Also the OOM message shows the used memory:
[1049535.486537] **Out of memory**: Killed process 3718466 (python) total-vm:40458440kB, anon-rss:6219144kB, file-rss:68788kB, shmem-rss:343796kB, UID:1001 pgtables:18716kB oom_score_adj:0
as virtual memory and resident memory.
Sorry my bad, I mean it wasn’t using that much memory, we hardly use 50% of our System RAM, System RAM congestion could not be the reason for OOM Killer wake up.