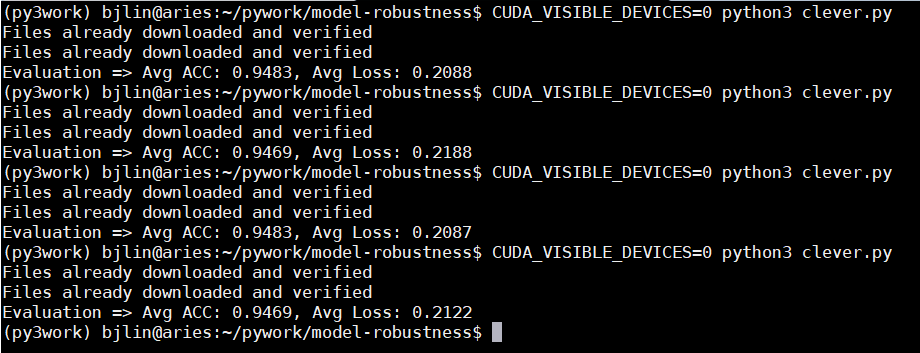
Hi,
I test the resnet18 several times, but the accuracy and the loss value are different in every time I test.
Does anyone can answer this situation, I am so confused…
Thanks!
Here is my test function
def eval_model(device, model, loader):
model.eval()
avg_acc = 0.0
avg_loss = 0.0
with torch.no_grad():
for batch_idx, batch_data in enumerate(loader):
images, labels = batch_data
images = images.to(device)
labels = labels.to(device)
batch_size = images.shape[0]
outputs = model(images)
loss = F.cross_entropy(outputs, labels)
# accuracy
preds = torch.max(outputs, 1)[1]
acc = (torch.eq(preds, labels).sum().item() / batch_size)
avg_loss += loss.item()
avg_acc += acc
avg_loss /= len(loader)
avg_acc /= len(loader)
print('Evaluation => Avg ACC: {:.4f}, Avg Loss: {:.4f}'.format(avg_acc, avg_loss))
Here is the result