for idx, batch in enumerate(Data_Loader):
…
When we iterate over data_loader, do all samples in the current (idx_th) batch get loaded in parallel or they are loaded one-by-one and then collated by collate_fn ?
for idx, batch in enumerate(Data_Loader):
…
When we iterate over data_loader, do all samples in the current (idx_th) batch get loaded in parallel or they are loaded one-by-one and then collated by collate_fn ?
Each worker (specified by num_workers in the DataLoader) will load a full batch by loading and processing the samples sequentially. The workers work in parallel.
Isn’t there a method to use multi-processing to load all samples of one batch in parallel?
I am using map-style dataloader with batch_size of 512 images. Loading of one batch (i.e. 512 images) takes around 20 seconds which is acting as a bottleneck in my training.
I think you could try to use a BatchSampler and pass the indices of the entire batch to the Dataset.__getitem__ as described here. Inside the __getitem__ you could then try to use multiple processes to load the samples in parallel.
Alright. Do you think that initiating multiple processes in __getitem__ (in this particular case) will create issues for a scenario user sets num_workers>0?
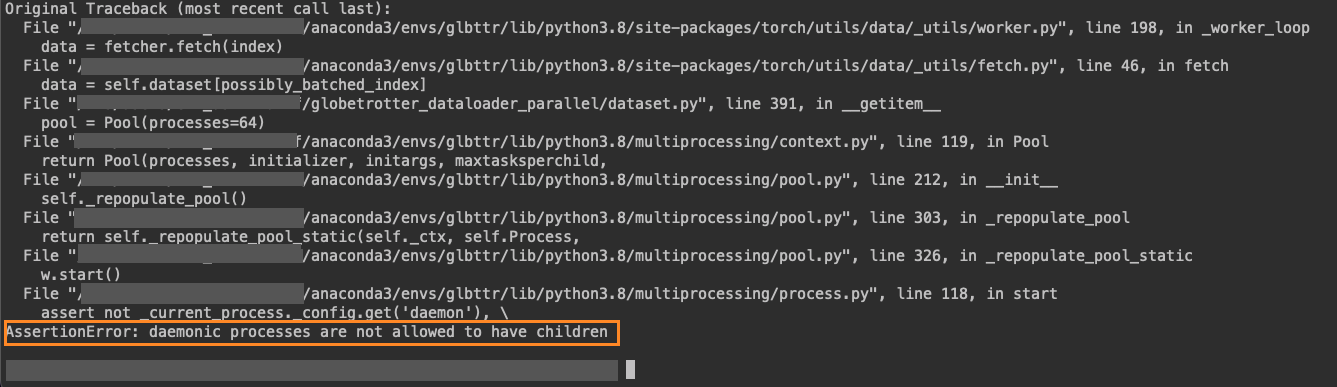
I have tried using parallel batch loading in conjunction with num_workers>0 , however, processes linked to num_workers>0 do not get initiated and get the following error:
AssertionError: daemonic processes are not allowed to have children
You might want to try to use the spawn startmethod and see if this would fix the issue. However, note that I have not verified it as I wasn’t running in your use case yet.