Hi,
I have print the tensor storage information during forward and backward, as this code snippet. I have inserted in pytorch c++ backend source code.
void Record_tensors(std::string func_name, std::vector<std::pair<std::string, std::reference_wrapper<at::Tensor>>> datas){
auto now = Clock::now();
Duration duration = std::chrono::duration_cast<FinalTime>(now - startTime);
out << func_name << " " << duration.count() << "ns ";
for (auto data: datas){
if(data.second.get().has_storage()){
void* storage_ptr = data.second.get().data_ptr();
out << data.first <<" : "<<storage_ptr<<" ";
}
}
out<<std::endl;
}
however, the result really confused me.
The resnet-50 network is used in my test, for the 1st iteration during training, the storage address of the first conv is 0x7fd25a900000.
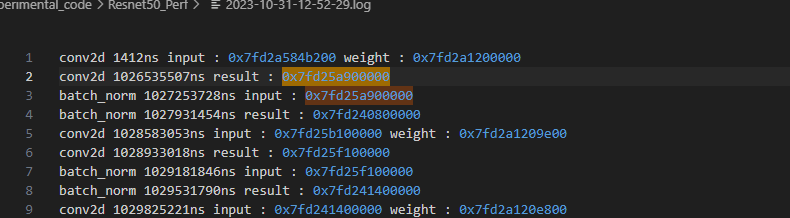
And, it will still be used in backward process, as follow,
.
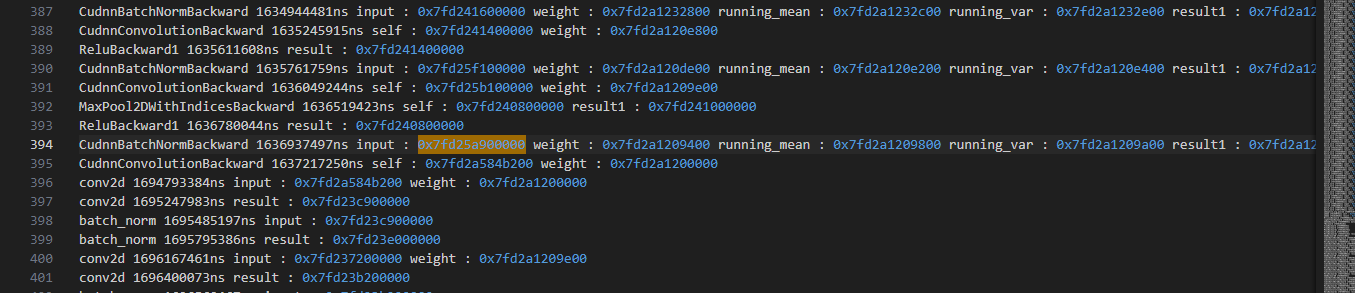
This seems normal, and then the following iterations process is weird.
This is the storage address of the first conv in 2nd iteration:
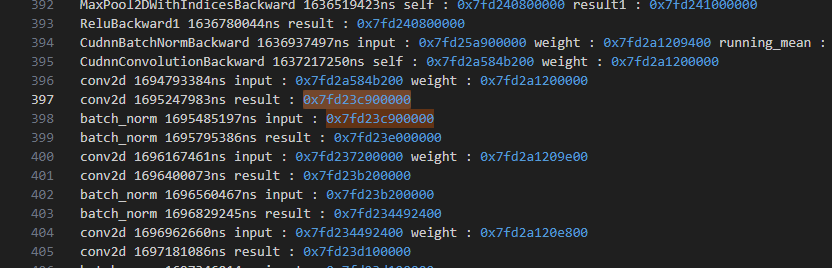
and it is same as the 3rd iteration and it’s the same as the iterations after that:
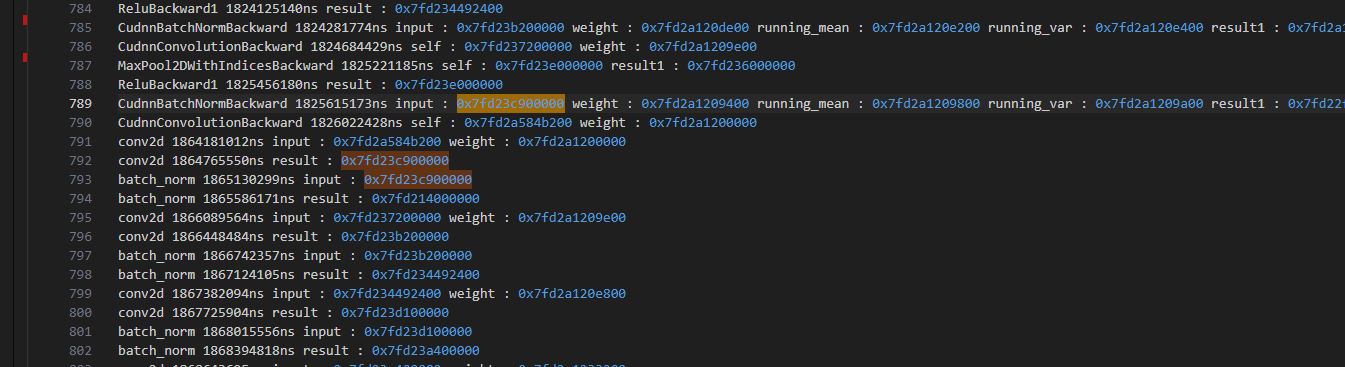

the different line number can reperesent for the different iterations. This is the same phenomenon for other intermediate results.
Can someone explain why this happens, because the address of the first iteration and the second iteration are different, I don’t think it is a problem of the code I wrote. Is there a sharing memory mechanism for the Pytorch?