We would need some more information about your use case to help you out.
What kind of model are you loading?
How long does the loading take?
Are you pushing the model to the GPU or is it still on the CPU?
Thanks a lot for your attention.
This is the code that I want to repeat the training process.The model is SiamRPN,one of the trackers in the pysot.The losding takes for many hous and when I press ctrl+c,it shows as follows:
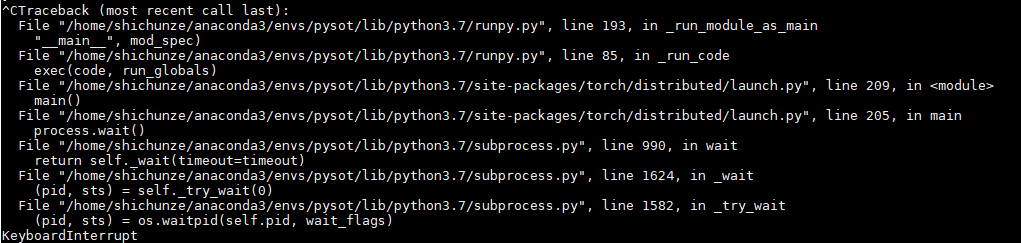
Although I use ctrl+c,the GPU still shows as follows:
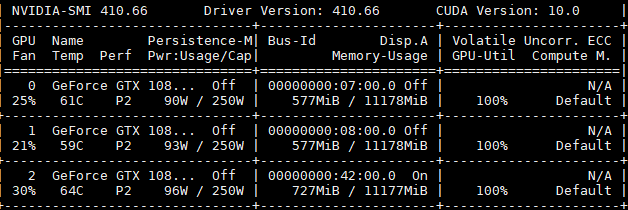
The gpu-util remains 100%.
The training process is pushed on these three GPUs.And I just stcuk here.
I try some things as changing the num_worker to 0 or decrease the batchsize,both of witch don’t work.
Could you please tell me why?
Is this issue specific to this particular repository and can you execute some of our tutorials or do you see the same error?
I think this issue is specific to this repository.
I have seen someone else have the same question in the github.
Could it be a problem with distributed training?I use 3 GPUs instead of 8.
sorry I have no idea.
I try single GPU to run,it works.
Maybe the reason of this issue is from distributed_training.
I still haven’t found the real reason.
Are you able to run the distributed example without any error?
I will try it then give a repply.
Thank you again for your attention.
I still can’t deal with it.
There is the same situation for the others in my lab.
And we don’t know why.