I’m trying to DDP train a MNIST image classification, the code is as follows.
def main():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running DDP on rank {rank}.")
transform = transforms.Compose([transforms.Resize((32, 32)), transforms.ToTensor()])
train_dataset = MNIST("./MNIST", train=True, download=True, transform=transform) # 训练数据集
train_sampler = DistributedSampler(train_dataset, shuffle=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=256, sampler=train_sampler)
device_id = rank % torch.cuda.device_count()
model = LeNet().to(device_id)
model = DDP(model, device_ids=[device_id])
epochs = 10 # 定义训练轮数
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
# 定义随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
for epoch in range(epochs):
train_loss, correct, total = 0, 0, 0
for index, (inputs, targets) in enumerate(train_dataloader):
# 将输入数据放置在正确的设备上
inputs, targets = inputs.to(device_id), targets.to(device_id)
optimizer.zero_grad()
outputs = model(inputs) # 通过模型输出
loss = criterion(outputs, targets) # 计算每个 batch 的损失
loss.backward() # 损失函数反向传播
optimizer.step() # 随机梯度优化器对模型参数优化
train_loss += loss.item()
_, predict = outputs.max(1)
total += targets.size(0)
correct += predict.eq(targets).sum().item()
print(f"epoch on rank {rank}: {epoch + 1} / {epochs}, loss: {loss:.4f}, accuracy: {(100 * correct / total):.2f}%")
if rank == 0: # 只在一个进程中保存模型,以防止多个进程尝试写入同一个文件
torch.save(ddp_model.module.state_dict(), 'model.pth') # 保存模型参数
dist.destroy_process_group()
if __name__ == "__main__":
main()
Then I ran the code via torchrun.
torchrun --nnodes=1 --nproc_per_node=2 main.py
Then I used watch -n 1 nvidia-smi to check the process and found that there were three processes, two of which were on GPU 0.
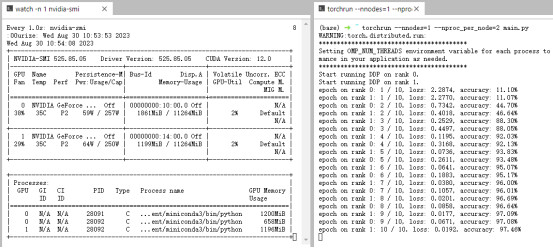
Why 3 processes instead of 2?