I am a university student that is currently developing a Pytorch add-on. The add-on would aim to make models train 70%-90% faster.
However, this speed boost while training comes at the expense of model accuracy (approximately 3%-5%).
I was hoping to open a discussion about people’s thoughts on this proposed framework. More specifically, what people think about the speed vs accuracy trade off.
A model with a 2x throughput for an accuracy loss of 5% sounds like a really interesting use case.
Depending, how your method works, would it be possible to “restore the better accuracy” by disabling your method towards the end of the training?
Wouldn’t this slow down the training again and we have the original model back?
Anyway, I still think it’s an interesting idea and some quantization approaches use exactly this strategy (losing a bit of model accuracy to gain speed).
It might depend a bit on your use case and how exactly the method is applied.
E.g. if your method would also speedup the inference (and even on e.g. the mobile platform), this might be a valid “deployment” mode (a lower model accuracy might be acceptable on mobile platforms).
For general training you would have to check how much work implementing your method would be, as even small accuracy drops might scare people from trying out your method. E.g. the quantization accuracy results show a smaller accuracy drop for a similar or higher performance gain.
But again, it might depend on the overall complexity of your method and in which situation you are working on it. E.g. if it’s a new research direction, which might be part of your studies (or PhD), small steps might be good enough to create a foundation and fix some issues in the next steps.
Hello again ! I took your suggestions regarding the potentially concerning drop in accuracy seriously. I entirely agree with your points. Not only will the drop in performance possibly scare some users off, but a 5% drop in accuracy could potentially make the plugin useless in some applications (e.g. Medical Procedures, Self-driving cars, other high-risk tasks).
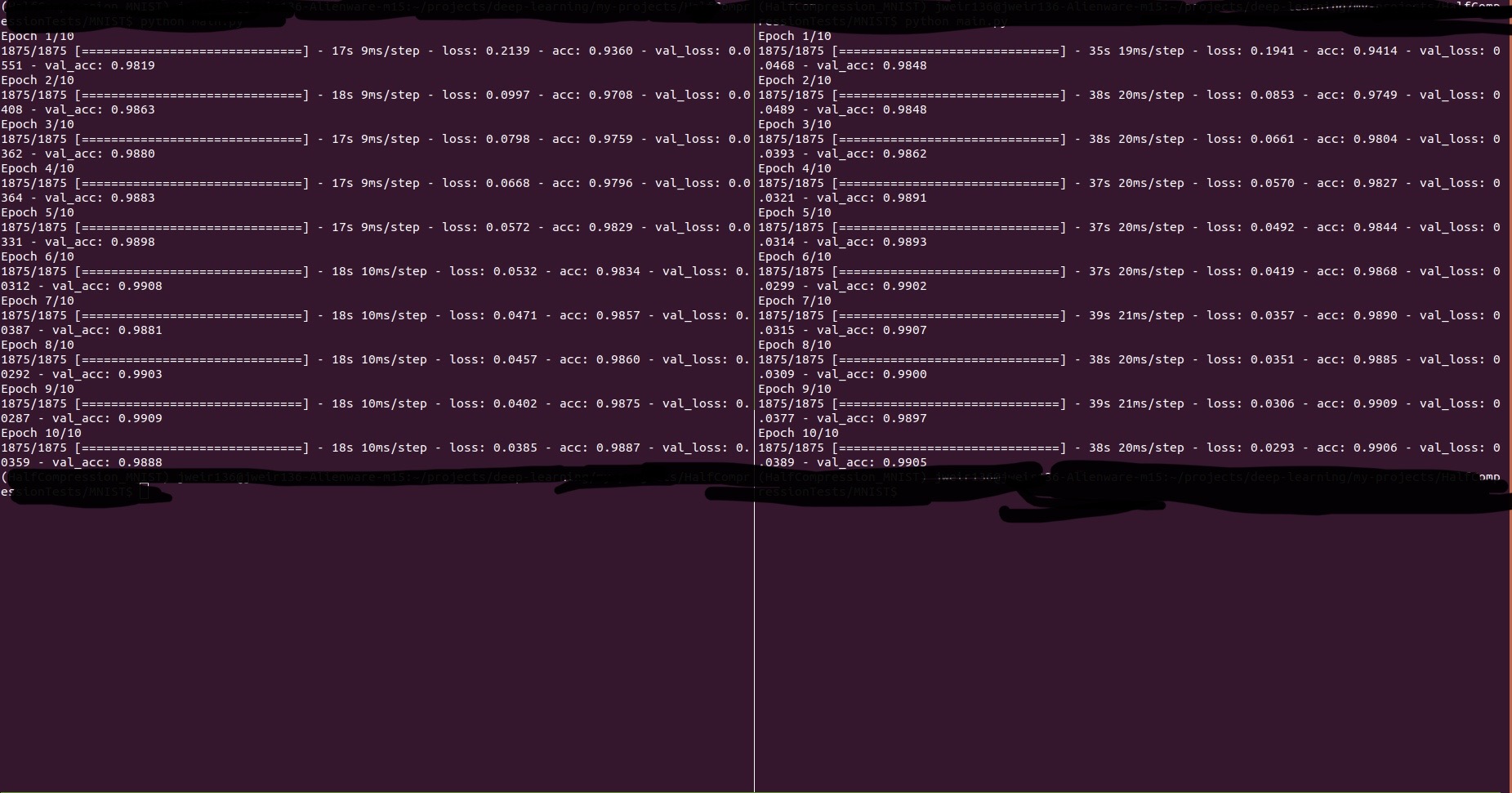
After redesigning the algorithm, I was able to remove the performance gap! Now the plugin is able to train a model approximately 50% faster without any noticeable drop in performance.
Below I have included a screenshot of my training to demonstrate the plugin’s performance. The same model was trained on the MNIST Digits dataset using a batch size of 32 and 10 epochs. The left panel on the image is training using the plugin and the right panel is training without the plugin.
I apologize for censoring some parts of the image (it was necessary to protect my privacy), and for using the Tensorflow framework instead of PyTorch.
If you have any comments please get back to me. Thank you!