I am trying to add skip connections to the network. and facing this error while trying to return two values.
i am new to pytorch what is it I am doing wrong.
This image explains where I am trying to add skip connections.
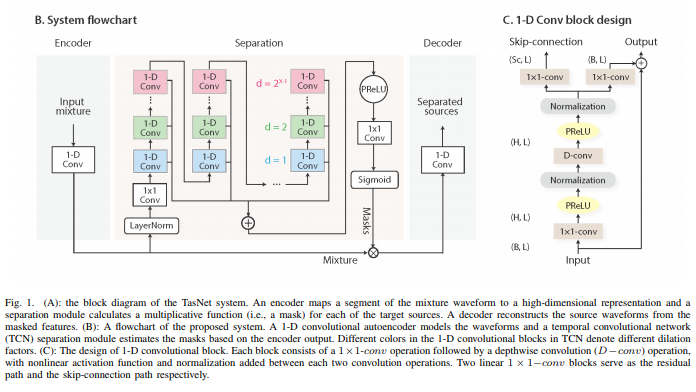
Here is the code below:
import torch
import torch.nn as nn
import torch.nn.functional as F
from utils import overlap_and_add
EPS = 1e-8
class ConvTasNet(nn.Module):
def __init__(self, N, L, B, Sk, H, P, X, R, C, norm_type="gLN", causal=False,
mask_nonlinear='relu'):
"""
Args:
N: Number of filters in autoencoder
L: Length of the filters (in samples)
B: Number of channels in bottleneck 1 × 1-conv block
Sk: Skip Connections
H: Number of channels in convolutional blocks
P: Kernel size in convolutional blocks
X: Number of convolutional blocks in each repeat
R: Number of repeats
C: Number of speakers
norm_type: BN, gLN, cLN
causal: causal or non-causal
mask_nonlinear: use which non-linear function to generate mask
"""
super(ConvTasNet, self).__init__()
# Hyper-parameter
self.N, self.L, self.B, self.Sk, self.H, self.P, self.X, self.R, self.C = N, L, B, Sk, H, P, X, R, C
self.norm_type = norm_type
self.causal = causal
self.mask_nonlinear = mask_nonlinear
# Components
self.encoder = Encoder(L, N)
self.separator = TemporalConvNet(N, B, Sk, H, P, X, R, C, norm_type, causal, mask_nonlinear)
self.decoder = Decoder(N, L)
# init
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_normal_(p)
def forward(self, mixture):
"""
Args:
mixture: [M, T], M is batch size, T is #samples
Returns:
est_source: [M, C, T]
"""
mixture_w = self.encoder(mixture)
est_mask = self.separator(mixture_w)
est_source = self.decoder(mixture_w, est_mask)
# T changed after conv1d in encoder, fix it here
T_origin = mixture.size(-1)
T_conv = est_source.size(-1)
est_source = F.pad(est_source, (0, T_origin - T_conv))
return est_source
@classmethod
def load_model(cls, path):
# Load to CPU
package = torch.load(path, map_location=lambda storage, loc: storage)
model = cls.load_model_from_package(package)
return model
@classmethod
def load_model_from_package(cls, package):
model = cls(package['N'], package['L'], package['B'], package['Sk'], package['H'],
package['P'], package['X'], package['R'], package['C'],
norm_type=package['norm_type'], causal=package['causal'],
mask_nonlinear=package['mask_nonlinear'])
model.load_state_dict(package['state_dict'])
return model
@staticmethod
def serialize(model, optimizer, epoch, tr_loss=None, cv_loss=None):
package = {
# hyper-parameter
'N': model.N, 'L': model.L, 'B': model.B, 'Sk': model.Sk, 'H': model.H,
'P': model.P, 'X': model.X, 'R': model.R, 'C': model.C,
'norm_type': model.norm_type, 'causal': model.causal,
'mask_nonlinear': model.mask_nonlinear,
# state
'state_dict': model.state_dict(),
'optim_dict': optimizer.state_dict(),
'epoch': epoch
}
if tr_loss is not None:
package['tr_loss'] = tr_loss
package['cv_loss'] = cv_loss
return package
class Encoder(nn.Module):
"""Estimation of the nonnegative mixture weight by a 1-D conv layer.
"""
def __init__(self, L, N):
super(Encoder, self).__init__()
# Hyper-parameter
self.L, self.N = L, N
# Components
# 50% overlap
self.conv1d_U = nn.Conv1d(1, N, kernel_size=L, stride=L // 2, bias=False)
def forward(self, mixture):
"""
Args:
mixture: [M, T], M is batch size, T is #samples
Returns:
mixture_w: [M, N, K], where K = (T-L)/(L/2)+1 = 2T/L-1
"""
mixture = torch.unsqueeze(mixture, 1) # [M, 1, T]
mixture_w = F.relu(self.conv1d_U(mixture)) # [M, N, K]
return mixture_w
class Decoder(nn.Module):
def __init__(self, N, L):
super(Decoder, self).__init__()
# Hyper-parameter
self.N, self.L = N, L
# Components
self.basis_signals = nn.Linear(N, L, bias=False)
def forward(self, mixture_w, est_mask):
"""
Args:
mixture_w: [M, N, K]
est_mask: [M, C, N, K]
Returns:
est_source: [M, C, T]
"""
# D = W * M
source_w = torch.unsqueeze(mixture_w, 1) * est_mask # [M, C, N, K]
source_w = torch.transpose(source_w, 2, 3) # [M, C, K, N]
# S = DV
est_source = self.basis_signals(source_w) # [M, C, K, L]
est_source = overlap_and_add(est_source, self.L//2) # M x C x T
return est_source
class TemporalConvNet(nn.Module):
def __init__(self, N, B, Sk, H, P, X, R, C, norm_type="gLN", causal=False,
mask_nonlinear='relu'):
"""
Args:
N: Number of filters in autoencoder
B: Number of channels in bottleneck 1 × 1-conv block
Sk: Number of channels in Skip connections
H: Number of channels in convolutional blocks
P: Kernel size in convolutional blocks
X: Number of convolutional blocks in each repeat
R: Number of repeats
C: Number of speakers
norm_type: BN, gLN, cLN
causal: causal or non-causal
mask_nonlinear: use which non-linear function to generate mask
"""
super(TemporalConvNet, self).__init__()
# Hyper-parameter
self.C = C
self.mask_nonlinear = mask_nonlinear
# Components
# [M, N, K] -> [M, N, K]
layer_norm = ChannelwiseLayerNorm(N)
# [M, N, K] -> [M, B, K]
bottleneck_conv1x1 = nn.Conv1d(N, B, 1, bias=False)
# [M, B, K] -> [M, B, K]
repeats = []
residual = 0
for r in range(R):
blocks = []
for x in range(X):
dilation = 2**x
padding = (P - 1) * dilation if causal else (P - 1) * dilation // 2
block, skip_conn = TemporalBlock(B, H, P, stride=1,
padding=padding,
dilation=dilation,
norm_type=norm_type,
causal=causal)
blocks.append(block)
residual += skip_conn
repeats += [nn.Sequential(*blocks)]
nxt = nn.Sequential(*repeats)
residual = residual + nxt
# [M, B, K] -> [M, C*N, K]
mask_conv1x1 = nn.Conv1d(B, C*N, 1, bias=False)
# Put together
self.network = nn.Sequential(layer_norm,
bottleneck_conv1x1,
residual,
mask_conv1x1)
def forward(self, mixture_w):
"""
Keep this API same with TasNet
Args:
mixture_w: [M, N, K], M is batch size
returns:
est_mask: [M, C, N, K]
"""
M, N, K = mixture_w.size()
score = self.network(mixture_w) # [M, N, K] -> [M, C*N, K]
score = score.view(M, self.C, N, K) # [M, C*N, K] -> [M, C, N, K]
if self.mask_nonlinear == 'softmax':
est_mask = F.softmax(score, dim=1)
elif self.mask_nonlinear == 'relu':
est_mask = F.relu(score)
else:
raise ValueError("Unsupported mask non-linear function")
return est_mask
class TemporalBlock(nn.Module):
def __init__(self, B, H, kernel_size,
stride, padding, dilation, norm_type="gLN", causal=False):
super(TemporalBlock, self).__init__()
# [M, B, K] -> [M, H, K]
conv1x1 = nn.Conv1d(B, H, 1, bias=False)
prelu = nn.PReLU()
norm = chose_norm(norm_type, H)
# [M, H, K] -> [M, B, K]
dsconv , skipconv = DepthwiseSeparableConv(H, B, kernel_size,
stride, padding, dilation, norm_type,
causal)
# Put together
self.net1 = nn.Sequential(conv1x1, prelu, norm, dsconv)
self.net2 = nn.Sequential(conv1x1, prelu, norm, skipconv)
def forward(self, x):
"""
Args:
x: [M, B, K]
Returns:
[M, B, K]
"""
residual = x
out = self.net1(x)
nxt = out + residual
skip = self.net2(x)
# TODO: when P = 3 here works fine, but when P = 2 maybe need to pad?
return nxt , skip # look like w/o F.relu is better than w/ F.relu
# return F.relu(out + residual)
class DepthwiseSeparableConv(nn.Module):
def __init__(self, H, B, kernel_size,
stride, padding, dilation, norm_type="gLN", causal=False):
super(DepthwiseSeparableConv, self).__init__()
# Use `groups` option to implement depthwise convolution
# [M, H, K] -> [M, H, K]
depthwise_conv = nn.Conv1d(H, H, kernel_size,
stride=stride, padding=padding,
dilation=dilation, groups=H,
bias=False)
if causal:
chomp = Chomp1d(padding)
prelu = nn.PReLU()
norm = chose_norm(norm_type, H)
# [M, H, K] -> [M, B, K]
pointwise_conv = nn.Conv1d(H, B, 1, bias=False)
# Put together
if causal:
self.net1 = nn.Sequential(depthwise_conv, chomp, prelu, norm,
pointwise_conv)
self.net2 = nn.Sequential(depthwise_conv, chomp, prelu, norm,
pointwise_conv)
else:
self.net1 = nn.Sequential(depthwise_conv, prelu, norm,
pointwise_conv)
self.net2 = nn.Sequential(depthwise_conv, chomp, prelu, norm,
pointwise_conv)
def forward(self, x):
"""
Args:
x: [M, H, K]
Returns:
result: [M, B, K]
"""
return self.net1(x),self.net2(x)
class Chomp1d(nn.Module):
"""To ensure the output length is the same as the input.
"""
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
"""
Args:
x: [M, H, Kpad]
Returns:
[M, H, K]
"""
return x[:, :, :-self.chomp_size].contiguous()
def chose_norm(norm_type, channel_size):
"""The input of normlization will be (M, C, K), where M is batch size,
C is channel size and K is sequence length.
"""
if norm_type == "gLN":
return GlobalLayerNorm(channel_size)
elif norm_type == "cLN":
return ChannelwiseLayerNorm(channel_size)
else: # norm_type == "BN":
# Given input (M, C, K), nn.BatchNorm1d(C) will accumulate statics
# along M and K, so this BN usage is right.
return nn.BatchNorm1d(channel_size)
# TODO: Use nn.LayerNorm to impl cLN to speed up
class ChannelwiseLayerNorm(nn.Module):
"""Channel-wise Layer Normalization (cLN)"""
def __init__(self, channel_size):
super(ChannelwiseLayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
self.beta = nn.Parameter(torch.Tensor(1, channel_size,1 )) # [1, N, 1]
self.reset_parameters()
def reset_parameters(self):
self.gamma.data.fill_(1)
self.beta.data.zero_()
def forward(self, y):
"""
Args:
y: [M, N, K], M is batch size, N is channel size, K is length
Returns:
cLN_y: [M, N, K]
"""
mean = torch.mean(y, dim=1, keepdim=True) # [M, 1, K]
var = torch.var(y, dim=1, keepdim=True, unbiased=False) # [M, 1, K]
cLN_y = self.gamma * (y - mean) / torch.pow(var + EPS, 0.5) + self.beta
return cLN_y
class GlobalLayerNorm(nn.Module):
"""Global Layer Normalization (gLN)"""
def __init__(self, channel_size):
super(GlobalLayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
self.beta = nn.Parameter(torch.Tensor(1, channel_size,1 )) # [1, N, 1]
self.reset_parameters()
def reset_parameters(self):
self.gamma.data.fill_(1)
self.beta.data.zero_()
def forward(self, y):
"""
Args:
y: [M, N, K], M is batch size, N is channel size, K is length
Returns:
gLN_y: [M, N, K]
"""
# TODO: in torch 1.0, torch.mean() support dim list
mean = y.mean(dim=1, keepdim=True).mean(dim=2, keepdim=True) #[M, 1, 1]
var = (torch.pow(y-mean, 2)).mean(dim=1, keepdim=True).mean(dim=2, keepdim=True)
gLN_y = self.gamma * (y - mean) / torch.pow(var + EPS, 0.5) + self.beta
return gLN_y
if __name__ == "__main__":
torch.manual_seed(123)
M, N, L, T = 2, 3, 4, 12
K = 2*T//L-1
B, H, P, X, R, C, norm_type, causal = 2, 3, 3, 3, 2, 2, "gLN", False
mixture = torch.randint(3, (M, T))
# test Encoder
encoder = Encoder(L, N)
encoder.conv1d_U.weight.data = torch.randint(2, encoder.conv1d_U.weight.size())
mixture_w = encoder(mixture)
print('mixture', mixture)
print('U', encoder.conv1d_U.weight)
print('mixture_w', mixture_w)
print('mixture_w size', mixture_w.size())
# test TemporalConvNet
separator = TemporalConvNet(N, B, H, P, X, R, C, norm_type=norm_type, causal=causal)
est_mask = separator(mixture_w)
print('est_mask', est_mask)
# test Decoder
decoder = Decoder(N, L)
est_mask = torch.randint(2, (B, K, C, N))
est_source = decoder(mixture_w, est_mask)
print('est_source', est_source)
# test Conv-TasNet
conv_tasnet = ConvTasNet(N, L, B, H, P, X, R, C, norm_type=norm_type)
est_source = conv_tasnet(mixture)
print('est_source', est_source)
print('est_source size', est_source.size())