I am using Inception V3 pre-trained on ImageNet. I am following this architecture for the training and I am doing tile-based training.
After I saved the trained model, I load it to do aggregation of tiles prediction based on the average of output probabilities. Each WSI initially is chopped into a lot of tiles and each tile gets the weak label of the WSI.
I would like to know what “tile aggregation by averaging output probability” exactly mean and also how to get the output probability for each of the test data points? when I pass an image from the test to the trained model, I get two values not a probability.

and the architecture is:
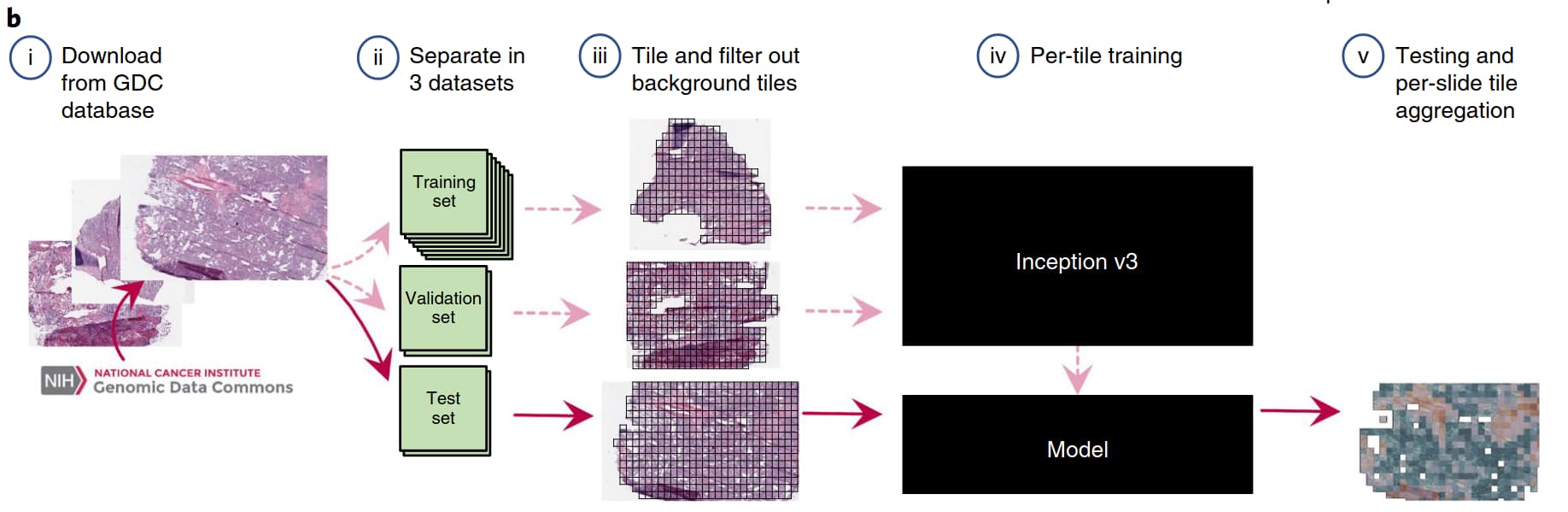
You can download the full paper here:
Here’s my test code:
test_large_images = {}
test_loss = 0.0
test_acc = 0
with torch.no_grad():
test_running_loss = 0.0
test_running_corrects = 0
print(len(dataloaders_dict['test']))
for i, (inputs, labels) in enumerate(dataloaders_dict['test']):
print(i)
test_input = inputs.to(device)
test_label = labels.to(device)
test_output = saved_model_ft(test_input)
_, test_pred = torch.max(test_output, 1)
print('test pred: ', test_output)
sample_fname, label = dataloaders_dict['test'].dataset.samples[i]
patch_name = sample_fname.split('/')[-1]
large_image_name = patch_name.split('_')[0]
if large_image_name not in test_large_images.keys():
test_large_images[large_image_name] = list()
test_large_images[large_image_name].append(test_pred.item())
else:
test_large_images[large_image_name].append(test_pred.item())
test_running_corrects += torch.sum(test_pred == test_label.data)
test_acc = test_running_corrects / len(dataloaders_dict['test'].dataset)
print(test_acc)
For example, here are some of the results:
0
test pred: tensor([[ 1.9513, -2.4072]], device='cuda:2')
1
test pred: tensor([[ 1.0274, -1.0467]], device='cuda:2')
2
test pred: tensor([[ 0.6868, -0.8948]], device='cuda:2')
3
test pred: tensor([[ 0.8908, -1.1201]], device='cuda:2')
4
test pred: tensor([[ 0.7935, -0.9384]], device='cuda:2')
5
test pred: tensor([[ 1.1609, -1.3650]], device='cuda:2')
6
so, how do I get the output probability? and how does tile aggregation by averaging output probability exactly work in this scenario.
About probabilities, I found this piece of code, but it still gives two values:
probability = torch.nn.functional.softmax(test_output[0], dim=0)
Is that what we are looking for or just the highest value between the two?
probability: tensor([0.9785, 0.0215], device='cuda:2')
test output: tensor([[ 1.6664, -2.1500]], device='cuda:2')
So, going back to the method in the paper, for
test_input = inputs.to(device)
test_label = labels.to(device)
test_output = saved_model_ft(test_input)
probabilities = torch.nn.functional.softmax(test_output[0], dim=0)
print('probabilities: ', probabilities)
probability = torch.max(torch.nn.functional.softmax(test_output[0], dim=0))
print('probability: ', probability)
_, test_pred = torch.max(test_output, 1)
print('test output: ', test_output)
print('test pred: ', test_pred)
should I do the torch.max on probability vector and save a probability value for each tile? this is for one tile in test set:
probabilities: tensor([0.8992, 0.1008], device='cuda:2')
probability: tensor(0.8992, device='cuda:2')
test output: tensor([[ 1.0471, -1.1416]], device='cuda:2')
test pred: tensor([0], device='cuda:2')
also, please assume we have the following results for two tiles in test set that both belong to the same WSI and that WSI presumably has two tiles.
if I have this for one test data point
probabilities: tensor([0.8992, 0.1008], device='cuda:2')
probability: tensor(0.8992, device='cuda:2')
test output: tensor([[ 1.0471, -1.1416]], device='cuda:2')
test pred: tensor([0], device='cuda:2')
and this for another test datapoint:
probabilities: tensor([0.7603, 0.2397], device='cuda:2')
probability: tensor(0.7603, device='cuda:2')
test output: tensor([[ 0.4782, -0.6760]], device='cuda:2')
test pred: tensor([0], device='cuda:2')
How do you do the tile aggregation by averaging the output probability here?
using (0.8992 * 0 + 0.7603 * 0) / 2 ?
If this is the case, my concern is since majority of data is class 0, this would result with 0 as the label as well.