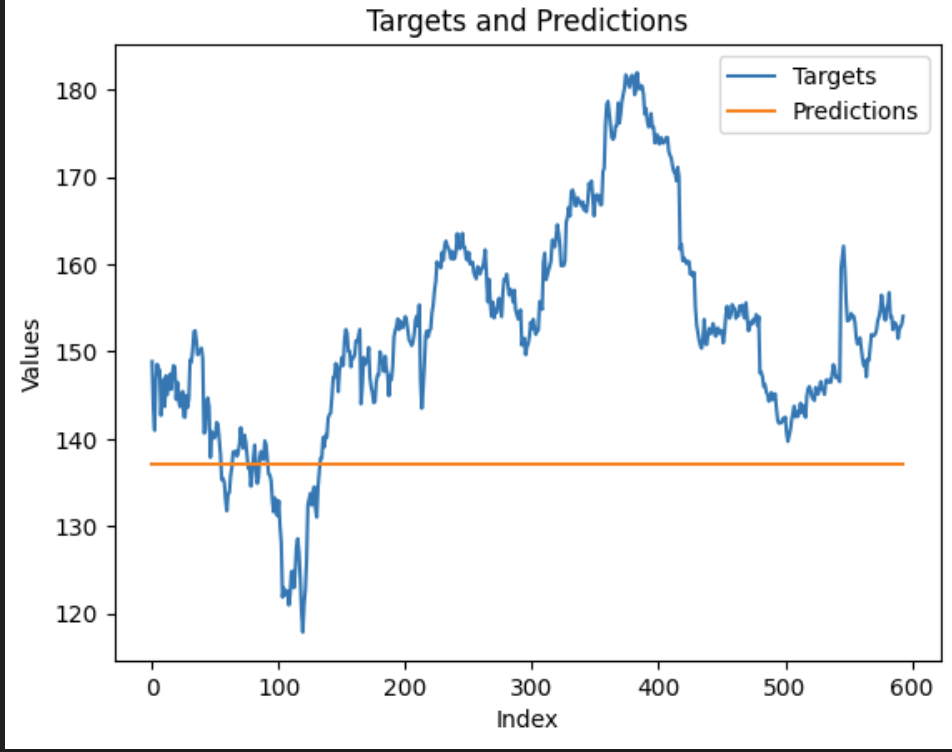
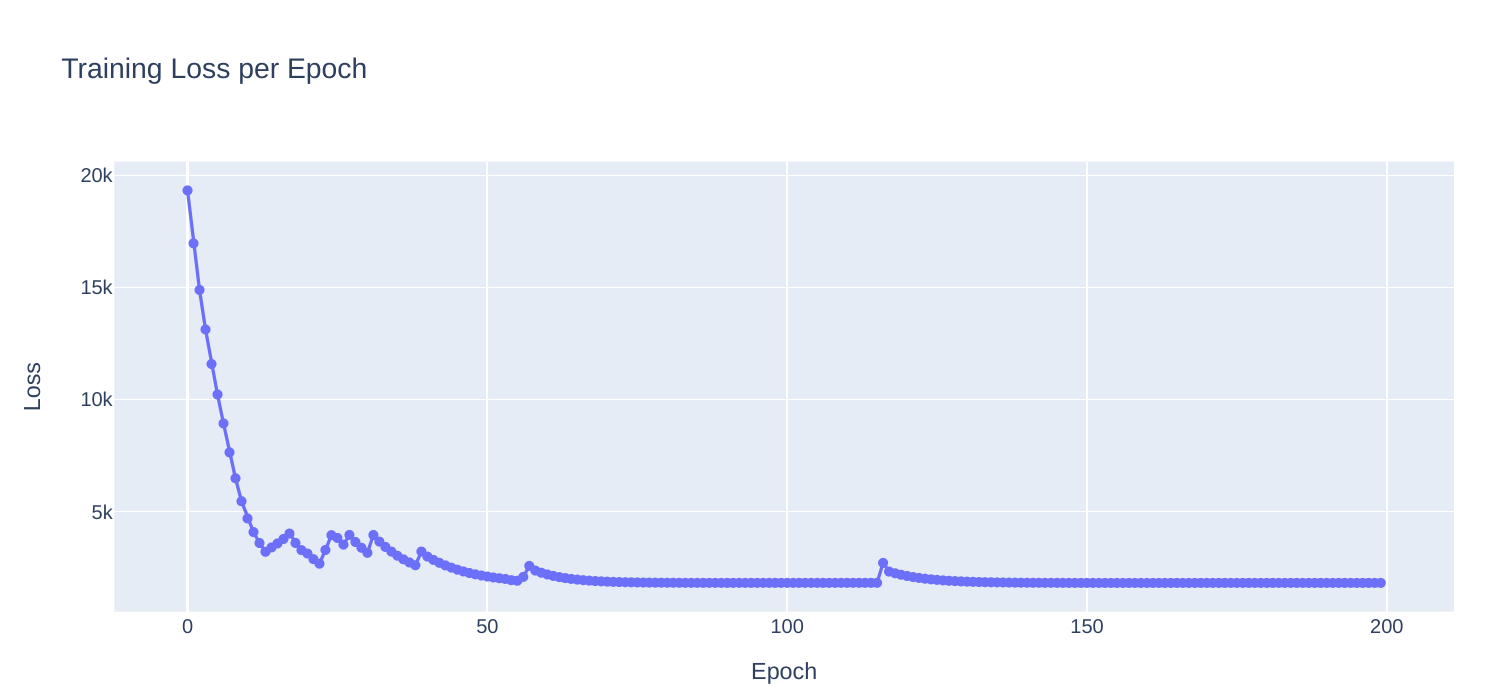
Hey @ptrblck , I seem to have a pretty identical issue while training a LSTM. My network produces a curve with a roughly correct “shape” but off by orders of magnitude in terms of scaling making it look flat when compared to the target output. Continued training doesn’t help, it seems to plateu. Any suggestions?
Code’s pretty simple, but here’s my model class and train function:
class stockLSTM(nn.Module):
def __init__(self, input_dim, hidden_size, output_dim) -> None:
super(stockLSTM, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_dim, hidden_size, batch_first=True)
self.output_dim = output_dim
self.output_layer = nn.Linear(hidden_size, output_dim)
def forward(self, x):
output, (h, _) = self.lstm(x)
output = self.output_layer(h.squeeze())
return output
def train(model, train_loader, val_loader, loss_function, optim, epochs, device, scheduler, start_decay):
losses = [] #group losses for loss visualization
for epoch in range(epochs):
running_loss = 0
print("Epoch %d / %d" % (epoch+1, epochs))
print("-"*10)
if (epoch > start_decay):
scheduler.step()
model.train()
for i, (x, y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
y_pred = model(x)
# print(f"y shape: {y.shape}, y_pred shape: {y_pred.shape}")
loss = loss_function(y_pred, y)
running_loss+=loss.item()
optim.zero_grad()
loss.backward() #backprop
optim.step() #update weights
losses.append((running_loss / i))
print("Step: {}/{}, current Epoch loss: {:.4f}".format(i, len(train_loader), (running_loss / i)))
val_loss = 0
with torch.no_grad():
for i, (x,y) in enumerate(val_loader):
y, x, = y.to(device), x.to(device)
y_pred = model(x)
loss = loss_function(y_pred, y)
val_loss += loss.item()
print("Epoch: {}, validation loss: {:.4f}".format(epoch+1, val_loss/len(val_loader)))
return losses
Edit: on further poking and proding, it now looks like it is actually just a straight line (not even maintaining the shape as it did initially)
Attaching loss and prediction curves for more context: