Hello,
I am working on a pytorch project, where I’m using a webcam video stream. An object detector is used to find objects within the frame. Then, I want to analyse each bounding box with an CNN-LSTM and classify (binary classification) the current frame based on the previous frame sequence of that box (for the last 5 frames). I want the program to run a close to real-time as possible.
Currently I am stuck with the CNN-LSTM part of my problem - the detector works quite well already.
I am a little bit clueless on how to approach this task. Here are the questions I have:
-
How does inferencing work in this case? Do I have to save np arrays for each bounding box containing the last 5 frames, then add the current frame and delete the oldest one? Then use the model for each bounding box that is in the current frame. This way sounds very slow and inefficient. Is there a faster or easier way?
-
Do you have any tipps for creating the dataset? I have a couple of videos with bounding boxes and labels. Should I loop through the videos and save save each frame sequence for each bounding box in a new folder, together with a csv that contains the label? I have never worked with an CNN-LSTM, so I don’t know how to load the data for training.
-
Would it be possible to use the extracted features of the CNN in parallel? As mentioned above, The extracted features should be used by the LSTM for a binary classification problem. The classification is only needed for the current frame. I would like to use an additional classifier (8 classes) based on the extracted CNN features, also only for the current frame. For this classifier, the LSTM is not needed.
Since my explaining propably is very confusing, the following image hopefully helps with understanding what I want to build (in this example only last 3 frames):
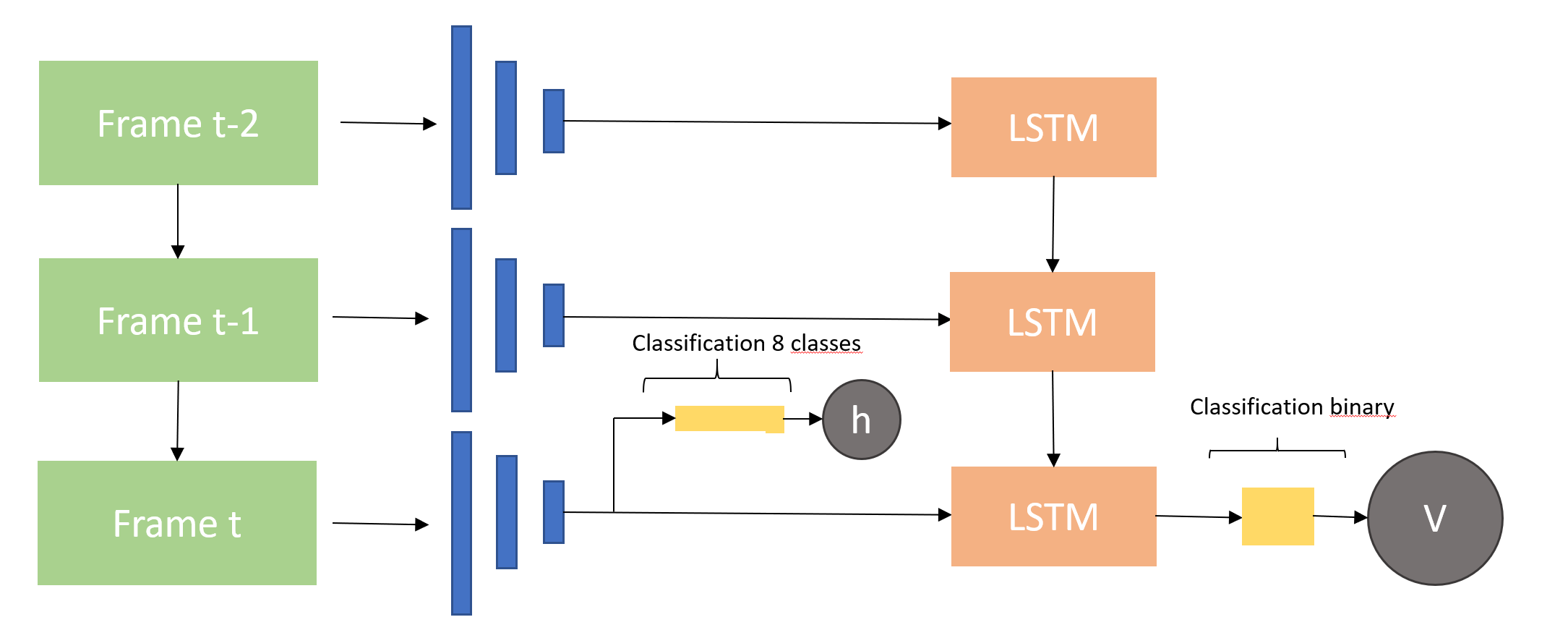
This is the architecture I want to use. Is this possible using Pytorch? Any help is apprechiated ![]()