I was wondering if there are any tips or tricks when trying to find CPU memory leaks? I’m currently running a model, and every epoch the RAM usage (as calculated via psutil.Process(os.getpid()).memory_info()[0]/(2.**30) ) increases by about 0.2GB on average. And I’m really not sure where this leak is coming from.
Are there any tips or tricks for finding memory leaks? The only thing that comes to mind for me is enabling torch.autograd.set_detect_anomaly(True) at the top of my script
You could try to use e.g. valgrind to find memory leaks in an application.
Note however, that this would find real “leaks”, while users often call an increase of memory in PyTorch also a “memory leak”. Usually it’s not a real leak, but is expected due to a wrong usage in the code, e.g. storing a tensor with the complete computation graph in a container (e.g. list etc.). Tools to find real leaks won’t help you here and I’m unsure if you are trying to debug a real leak or an increased memory usage caused by your script.
Hi @ptrblck, thanks for the quick response! My CPU memory leak here is quite weird to explain, I did briefly expand upon this topic with a new, more specific topic (CPU Memory leak but only when running on specific machine). Which I could merge together with this topic if that makes more sense?
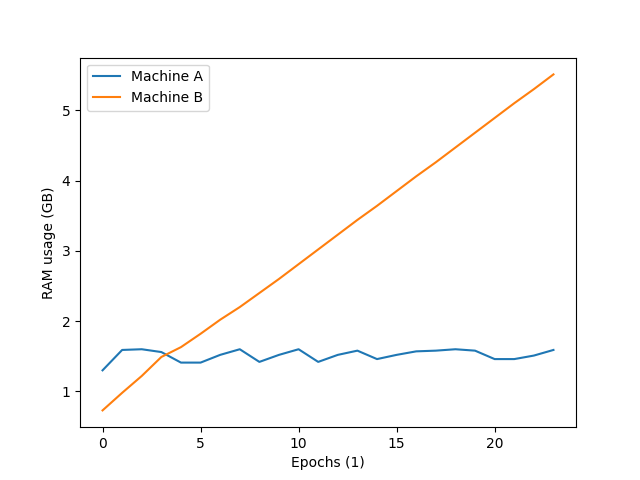
But in short, when I run my code on one machine (let’s say machine B) the memory usage slowly increases by around (200mb to 400mb) per epoch, however, running the same code on a different machine (machine A) doesn’t result in a memory leak at all. I’ve just rechecked this now to make sure I’m not doing some stupid but I’ve ran the same code (code extract from the same .tar.gz file) on two different machines and I get one machine leaking memory and the other one doesn’t. I’ve attached a graph to give a more visual comparison
Given both machines are running the same scripts, the only difference I can think of are environments and perhaps OS? Machine A is running Ubuntu 18.04 in a Conda environment (with pytorch 1.7.1 and cuda 11) Machine B is running Ubuntu 20.04 in a pip environment (with PyTorch 1.8.1+cpu). I did try running Machine B with a conda environment but I got a similar memory leak. Assuming it is an actual leak and not something within my script that stores a computational graph within a container (like you said) but if that were the case, surely it’d happen across both machines?
I would start the debugging by installing the same PyTorch version (install 1.8.1 on both machines), as this difference is I think the most likely root cause of it. Of course the OS and different machines might also cause (unknown) issues, but lets try to narrow it down by using the same software stack first.
Do you think running the code within pip on one machine and on conda on the other machine, might be an issue as well? I think there’s a way to save conda environment and transfer them between machines. What I’ll do as I wait for your response on that is upgrade both machines to 1.8.1 on pip/conda and rerun the scripts! Thank you!
Yes, it could also be an issue with a specific release in either conda, pip or both.
Note that you can also create new conda environments and install the 1.8.1 release there, which would keep your current environments (if that’s needed).
Nevertheless I would generally recommend to update to the latest stable release to get the most features and bug fixes.
Hi @ptrblck! So, I’ve updated both machines to run 1.8.1 (and both within a conda environment!) The only differences are OS and CUDA installation. Machine A has 11.0 Cuda installed whereas Machine B is cpu install only! I don’t think that would cause an error? I instantiate all my class at the beginning of the code and fix them to a device there, and there only. So, I don’t think there could be an issue with doing net = net.to('cpu')? The leak still exists, so it seems less a difference in PyTorch and perhaps something else that I’m missing.
Edit: I’ve also been tracking the number of objects within the script via gc.get_objects() and the number of objects increases after the 1st epoch, but it’s constant from the 2nd epoch onward. This behaviour is the same on both machines, although the actual number of objects is slightly lower on the machine that has the leak.
Since the memory leak seems to be caused on the host memory (if I understand the issue correctly), I don’t think the installed CUDA toolkit version matters here.
Yes, that is concerning.
Could you post the machine details (if possible) of the “leaking” machine?
Are you running the workload in a container or on bare metal?
Would it also be possible to get an executable code snippet to debug this issue?
Were you able to check for memory leaks with valgrind?
When you say “machine details” do you mean like hardware? Or software?
Do you mean like a docker container? If so, no I’m just running this on a desktop with the conda evironment stated previously. Just straight from command line with python3 main.py
I’m trying to think of the best way to get a coding snippet working so you can reproduce the error. The only issue is the code is spread over a few files and all brought together within a main script. While waiting for your response, I did go through the code and rewrote it up (from scratch) to remove any potential memory issue that I could see being an issue and the ‘new’ version still has the existing memory leak - so I’m a little confused still!
To add to the confusion, I played around with the size of my network and the batch size to see if that affected the memory leak. Interestingly enough, I’ve found one thing that may correspond to the leak. To give a brief overview, my network is a feed-forward network and takes N inputs and returns 2 outputs (sign and logabsdet from torch.slogdet), and is used to calculate a scalar loss value which I subsequently minimize. However, I’ve noticed that if I have N=8 (for the network input) the memory leak seems to go away and the memory usage just fluctuates around 0.5 Gb but if I have say N=12 the memory leak is present and increases by around 0.1GB per epoch.
I haven’t been able to check with valgrind yet, I’ve only use valgrind once and that was to debug some Fortran95 code so I’m not 100% sure that would interface with an interpretative language like Python. I can have a look online and see how to use it!
@ptrblck thanks for distinction you provided, especially the example you provided. I’m a beginner to PyTorch and I was stupidly storing loss tensors with the entire computational graph iteratively in a Python list (though I only needed the loss value not the tensor), and the example you provided helped fix my issue immediately. Thank you!
@AlphaBetaGamma96 were you able to resolve the issue? It seems I have the same problem where there is memory leak on one computer, but not on another.
In my case there is a memory leak when I run my code on CPU on Ubuntu 22 in Conda and Docker and on a windows 10 computer in Docker, but not on windows with my OS python installation.
In all 4 cases there is not a memory leak when I run on GPU. I have tried running Pytorch 1.13 and 2.0.1 and python 3.10 and 3.11 (not every combination on every os etc.), but it seems that the memory leak is when I run on CPU on a Linux based system?
I observe the memory leak with psutil, but have not seen it with objgraph, gc and some other tools.
The code is really complex and I don’t believe I can recreate a smaller example from the code, unfortunately.
Based on your description it seems you are not seeing a leak when the GPU is used, which might point to a CPU compute library. I’m not familiar enough with e.g. MKL and pure CPU workloads, but would start by trying to disable these accelerator libs.
@AlphaBetaGamma96 Thanks for the reply! I got some error with that profiler, but with psutil I see ca. 50MB leak per epoch in the places I mentioned: windows docker, ubuntu Conda and ubuntu docker all with CPU. And no leak with GPU or with CPU on windows global python installation (just some tiny fluctuations until a buffer is full then it is stable).
@ptrblck, thank you for the reply! I will check out the accelerator libs and get back to you later.
@AlphaBetaGamma96, @ptrblck, I found the problem! It seems to have been that the loss was saved in a buffer without being detached. I believe this is the same problem as “thesaientist” had. However, I still find it weird that the problem only occurred on some machines and only when using CPU on those machines. I found that the different machines had different “opt einsum” versions in the backend, but did not go any deeper than that.
That’s indeed strange. It’s a common issue, but I assumed your computation graph (and the intermediate tensors) are stored on the GPU, which would thus also increase the GPU memory. Since only the CPU memory increased, were you using pure CPU ops in the model?
There seemed to only be a memory leak when I used CPU for the whole model if that is what you are asking. My Pytorch versions were both with GPU and CPU capabilities, is the computation graph stored on the GPU even if the model is on the CPU device?
My application has a leak with torch 2.0 but not torch 1.1 or torch==1.12.0a0+2c916ef, so I wrote a small script to that just allocates 1 tensor and then deletes it and logs psutil.Process(PID).memory_info().rss. Not sure whether this is expected behavior: