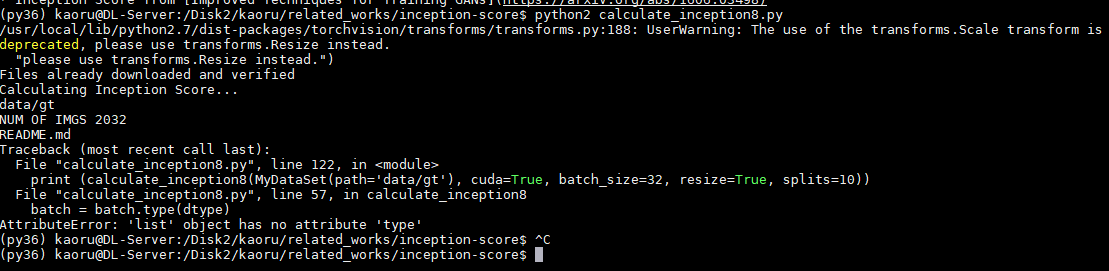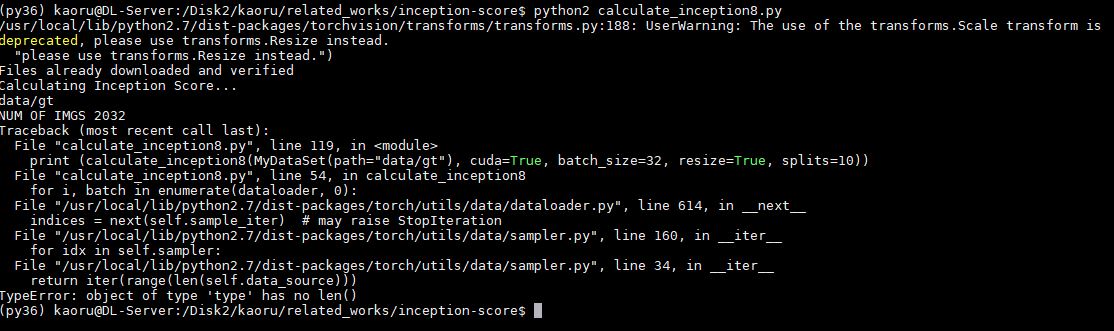
I have an error like this. I want to read my dataset and calculate inception score.
import torch
from torch import nn
from torch.autograd import Variable
from torch.nn import functional as F
import torch.utils.data
from torchvision.models.inception import inception_v3
import numpy as np
from scipy.stats import entropy
import os
import sys
from os.path import isfile,join
root = ‘/Disk2/kaoru/related_works/inception-score/data’
def calculate_inception7(imgs, cuda=True, batch_size=32, resize=False, splits=1):
“”“Computes the inception score of the generated images imgs
imgs – Torch dataset of (3xHxW) numpy images normalized in the range [-1, 1]
cuda – whether or not to run on GPU
batch_size – batch size for feeding into Inception v3
splits – number of splits
“””
N = len(imgs)
print(“NUM OF IMGS”+str(N))
assert batch_size > 0
assert N > batch_size
# Set up dtype
if cuda:
dtype = torch.cuda.FloatTensor
else:
if torch.cuda.is_available():
print("WARNING: You have a CUDA device, so you should probably set cuda=True")
dtype = torch.FloatTensor
# Set up dataloader
dataloader = torch.utils.data.DataLoader(dataset=MyDataSet, batch_size=batch_size)
# Load inception model
inception_model = inception_v3(pretrained=True, transform_input=False).type(dtype)
inception_model.eval();
up = nn.Upsample(size=(299, 299), mode='bilinear').type(dtype)
def get_pred(x):
if resize:
x = up(x)
x = inception_model(x)
return F.softmax(x).data.cpu().numpy()
# Get predictions
preds = np.zeros((N, 1000))
for i, batch in enumerate(dataloader, 0):
batch = batch.type(dtype)
batchv = Variable(batch)
batch_size_i = batch.size()[0]
preds[i*batch_size:i*batch_size + batch_size_i] = get_pred(batchv)
# Now compute the mean kl-div
split_scores = []
for k in range(splits):
part = preds[k * (N // splits): (k+1) * (N // splits), :]
py = np.mean(part, axis=0)
scores = []
for i in range(part.shape[0]):
pyx = part[i, :]
scores.append(entropy(pyx, py))
split_scores.append(np.exp(np.mean(scores)))
return np.mean(split_scores), np.std(split_scores)
if name == ‘main’:
class IgnoreLabelDataset(torch.utils.data.Dataset):
def init(self, orig):
self.orig = orig
def __getitem__(self, index):
return self.orig[index][0]
def __len__(self):
return len(self.orig)
import torchvision.datasets as dset
import torchvision.transforms as transforms
cifar = dset.CIFAR10(root='data/', download=True,
transform=transforms.Compose([
transforms.Scale(32),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
)
#IgnoreLabelDataset(cifar)
class MyDataSet(torch.utils.data.Dataset):
images=[]
def __init__(self, path):
self.images=[f for f in listdir(path) if isfile(join(path,f))]
def __getitem__(self,index):
return io.imread(self.images[index])
def __len__(self):
return len(self.images)
#torch.utils.data.DataLoader(dataset=MyDataSet)
print ("Calculating Inception Score...")
try:
folder =sys.argv[1]
except:
folder = 'gt'
folder='data'/+folder
print(folder)
print (calculate_inception8(MyDataSet(path="data/gt"), cuda=True, batch_size=32, resize=True, splits=10))
this is my code. I only added class MyDataSet. It reads correct number of images from my dataset folder. But it doesn’t run inception score part.
someone helps me, please