Hello,
I’m learning how to train a model using DDP torch.nn.parallel.DistributedDataParallel. I run my experiments in cluster with three GPU nodes, each node has one GPU (Nvidia T4). I’m (kind of) aware that my setup isn’t ideal. I’m not yet trying to get the last drop of FLOPS from my cluster, I’m simply stuck trying to get marginal improvement on train time when distributed across the three workers.
It looks like I’m missing something obvious can you help me find what ? More precisely I’m trying to figure out:
- Why my wall training time is only 40% faster when I distribute the training on three nodes ?
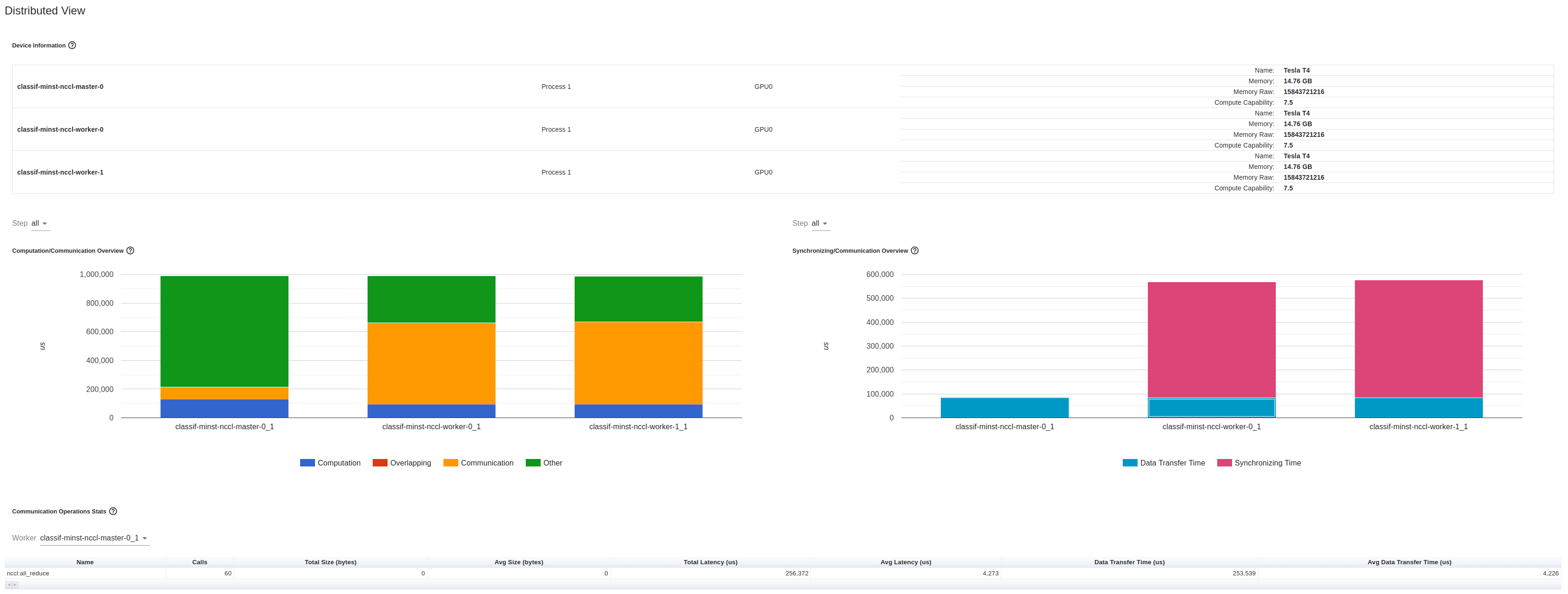
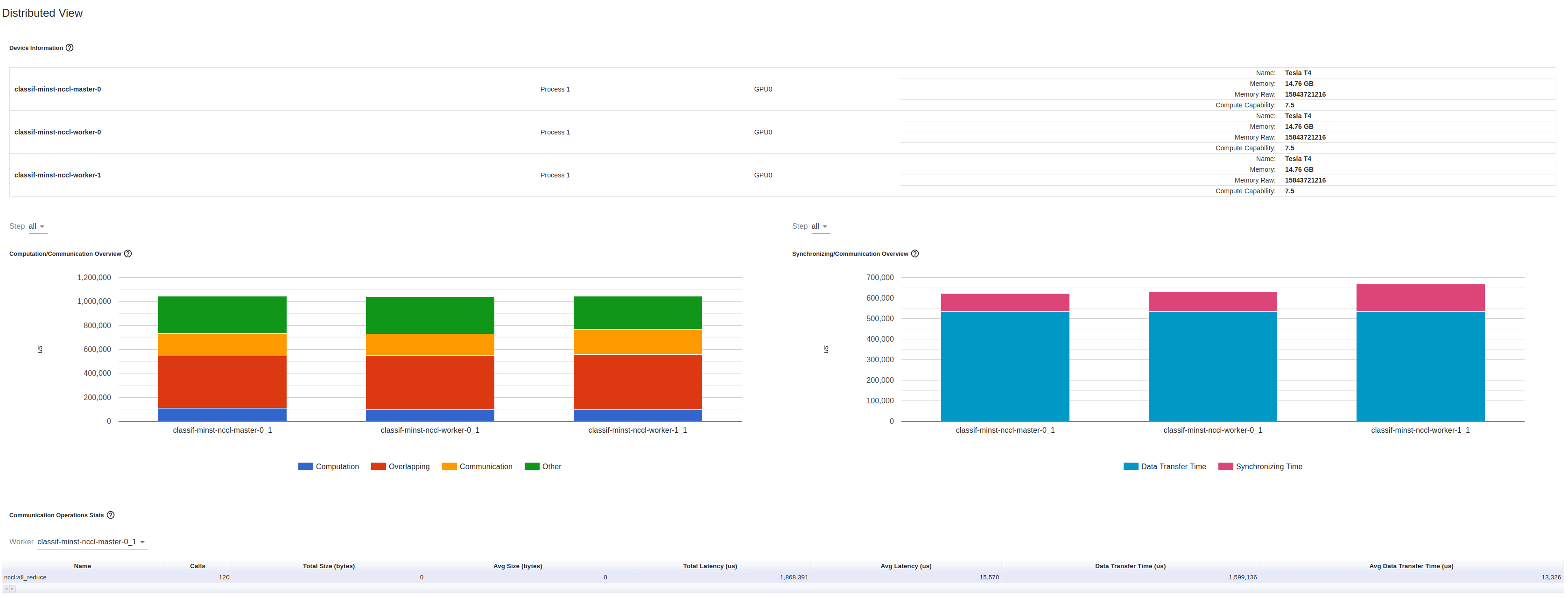
- When distributing the training, is it expected that half of GPU time is spent on
ncclKernel_AllReduce_RING_LL_Sum_float?
Below are more details on what I do, I know that’s a lot of reading and I don’t expect much… I’ll gladly take any advice one can offer ![]()
Thanks a lot !
Hardware
I use a kubernetes cluster with:
- Kubeflow CRDs (PyTorchJob, …)
- 7 Nodes, 3 nodes have one Telsa T4
- A descent network connection between the nodes
Software
- I use pytorch 1.10.0
- I use CUDA
- I use NCCL backend
- I train for 20 epochs
- I use a 1024 batch-size
- I train the model straight from the example in PyTorchJob’s git repository (see below)
Results
- Single node training (no distribution of any kind) :
- Test accuracy at epoch 20 is 0.8386
- WALL training time is 63.598 seconds
- Training with 3 nodes :
- Test accuracy at epoch 20 is 0.7622
- WALL training time is 38.594 seconds (measured on master)
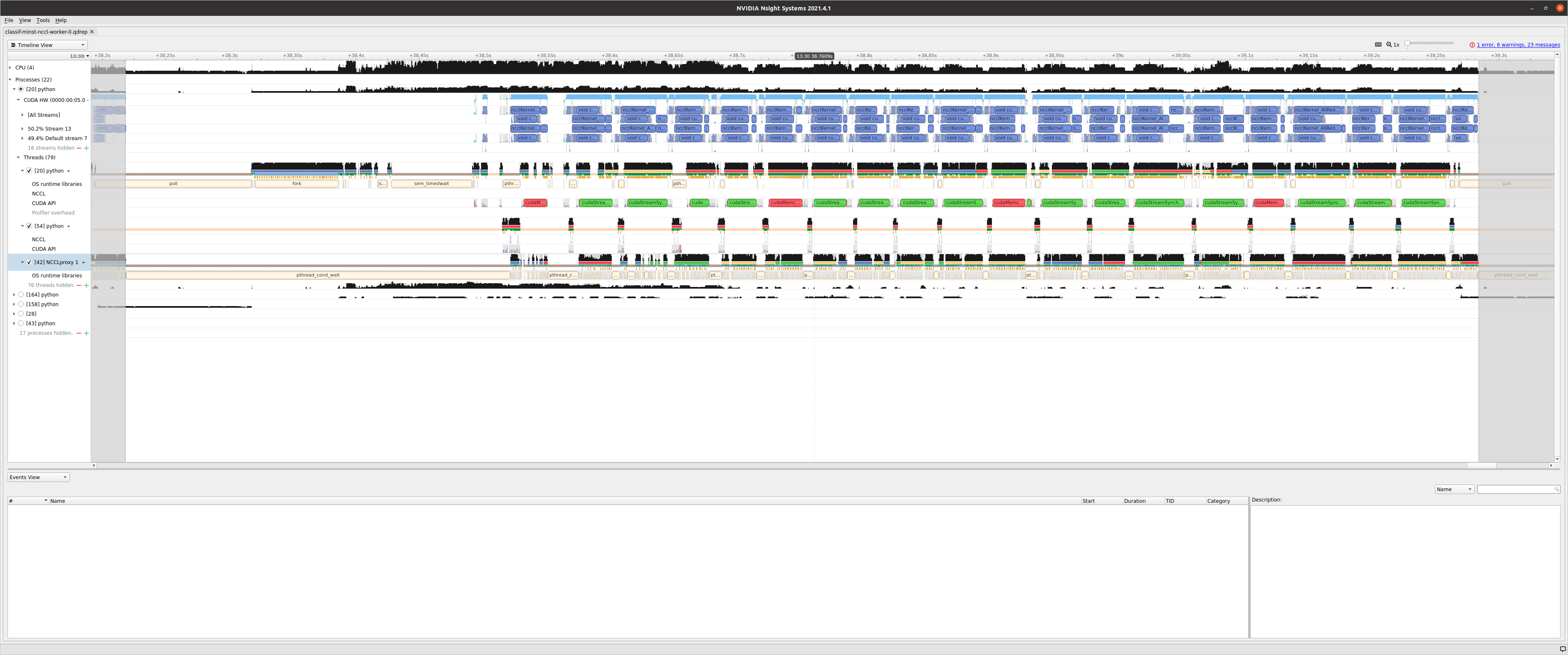
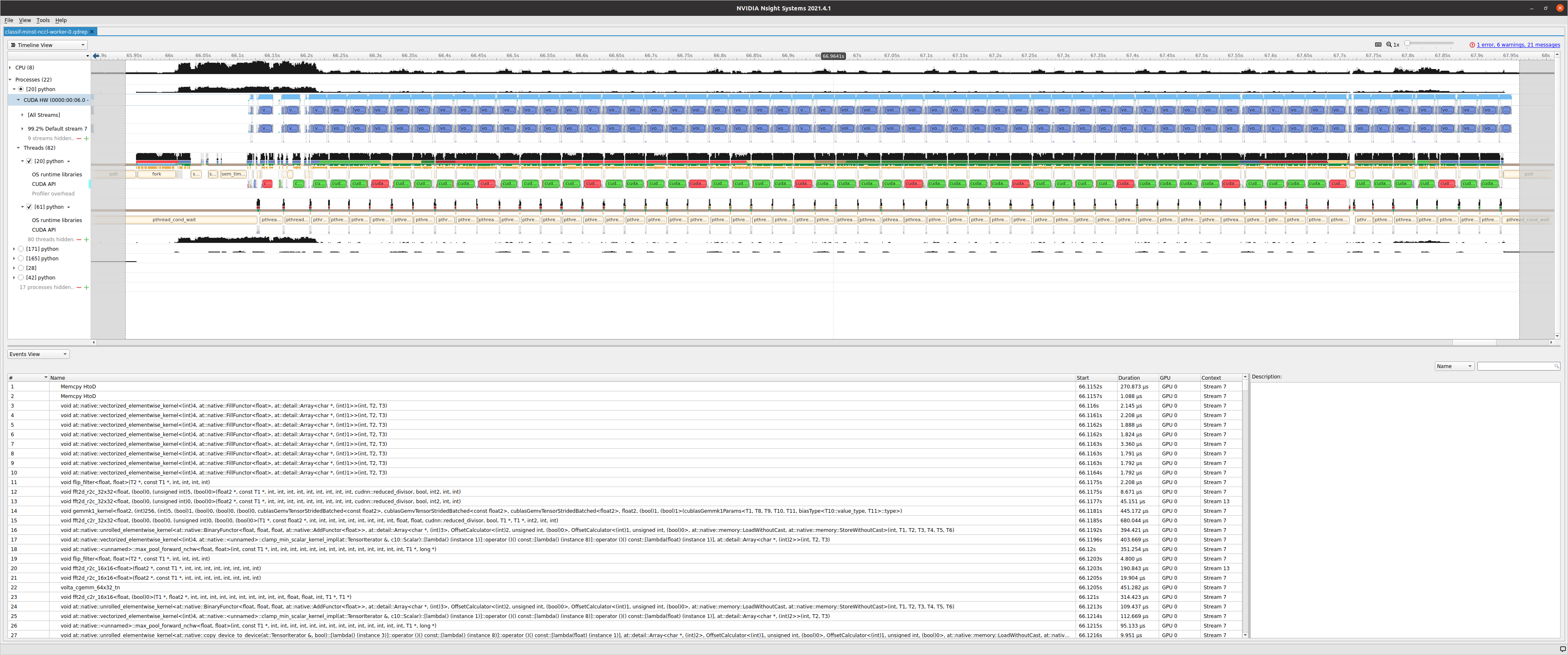
Profiling
I do profile using torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1) a step is an epoch.
Using three GPUs

For one single GPU

Code
Model
The Model has 431 080 trainable parameters :
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4 * 4 * 50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4 * 4 * 50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
Complete training code
Complete training code (most of it comes from the pytorch operator example):
import argparse
import logging
import os
import sys
import time
from typing import List, Any
import numpy as np
from torchvision import datasets, transforms
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
WORLD_SIZE = int(os.environ.get('WORLD_SIZE', 0))
RANK = int(os.environ.get('RANK', 0))
EXPE_ID = os.environ.get('EXPE_ID', "no-expe-id")
POD_NAME = os.environ.get("K8S_POD_ID", "unknown pod name")
class MockProfiler(object):
def __enter__(self):
logging.debug(f"Entering {self}")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
logging.debug(f"Exiting {self}")
def step(self):
pass
class WallTime(object):
def __init__(self, name):
self.wall = 0
self.name = name
def __repr__(self):
return f"WallTime({self.name}) @ {time.time()}"
def __enter__(self):
logging.debug(f"Entering {self}")
self.wall = time.time_ns()
def __exit__(self, exc_type, exc_val, exc_tb):
self.wall -= time.time_ns()
logging.debug(f"Exiting {self} after {abs(self.wall) / 1e9:.3f} WALL seconds")
class FashionMNISTInRam(datasets.FashionMNIST):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.buffer: List[Any] = [None] * len(self)
def prefetch(self):
for _ in range(len(self)):
_ = self[_]
return self
def __getitem__(self, index: int):
if self.buffer[index] is None:
self.buffer[index] = super().__getitem__(index)
return self.buffer[index]
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4 * 4 * 50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4 * 4 * 50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def should_distribute():
return dist.is_available() and WORLD_SIZE > 1
def is_distributed():
return dist.is_available() and dist.is_initialized()
def setup_logging():
stderr_handler = logging.StreamHandler(stream=sys.stdout)
formatter = logging.Formatter('[%(asctime)s on {}] %(message)s'.format(POD_NAME))
stderr_handler.setLevel(logging.DEBUG)
stderr_handler.setFormatter(formatter)
logging.root.setLevel(logging.DEBUG)
logging.root.addHandler(stderr_handler)
def setup_cli():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=1, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
parser.add_argument('--dir', default='logs', metavar='L',
help='directory where summary logs are stored')
if dist.is_available():
parser.add_argument('--backend', type=str, help='Distributed backend',
choices=[dist.Backend.GLOO, dist.Backend.NCCL, dist.Backend.MPI],
default=dist.Backend.GLOO)
return parser.parse_args()
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
logging.info('Train Epoch: {} [{}/{} ({:.0f}%)]\tloss={:.4f}'.format(
epoch, batch_idx * len(data), len(train_loader) * len(data),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
logging.info('accuracy={:.4f}'.format(float(correct) / len(test_loader.dataset)))
def main():
args = setup_cli()
torch.manual_seed(args.seed)
use_cuda = not args.no_cuda and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
is_master = RANK == 0
if should_distribute():
logging.info('Using distributed PyTorch with {} backend'.format(args.backend))
dist.init_process_group(backend=args.backend)
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
with WallTime("data load"):
train_set = FashionMNISTInRam('../data', train=True, download=True, transform=transform).prefetch()
test_set = FashionMNISTInRam('../data', train=False, transform=transform).prefetch()
kwargs = \
{"sampler": torch.utils.data.distributed.DistributedSampler(
train_set,
num_replicas=WORLD_SIZE,
rank=RANK,
shuffle=True)} if is_distributed() else {"shuffle": True}
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.test_batch_size,
shuffle=False,
num_workers=1,
pin_memory=True)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=args.batch_size,
num_workers=1,
pin_memory=True,
**kwargs)
model = Net().to(device)
if is_distributed():
if not use_cuda:
raise RuntimeError("Not using cuda")
model = nn.parallel.DistributedDataParallel(
model,
broadcast_buffers=True,
process_group=None,
bucket_cap_mb=25,
find_unused_parameters=False,
check_reduction=False)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
profiler = MockProfiler()
if is_master:
trace_handler = torch.profiler.tensorboard_trace_handler(os.path.join(args.dir))
profiler = torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA, ],
on_trace_ready=trace_handler)
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
logging.info(f"The model has {params} trainable parameters")
with WallTime("training"):
with profiler as p:
for epoch in range(1, args.epochs + 1):
if is_distributed():
train_loader.sampler.set_epoch(epoch)
train(args, model, device, train_loader, optimizer, epoch)
if is_master:
logging.info("Testing")
test(model, device, test_loader)
p.step()
if __name__ == '__main__':
setup_logging()
logging.info(os.environ)
with WallTime("main"):
main()
Kubeflow CRD
I run this POC using the dedicated CRD, which looks like:
apiVersion: "kubeflow.org/v1"
kind: "PyTorchJob"
metadata:
name: "classif-minst-nccl"
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: pytorch
imagePullPolicy: IfNotPresent
image: debug-dist-pytroch-minst:$VERSION
args: ["--backend", "nccl", "--dir", "/tmp/tb/nccl-$VERSION", "--epochs", "20", "--batch-size", "1024"]
resources:
limits:
nvidia.com/gpu: 1
Worker:
# The "replicas" value is 2 when doing distributed training
replicas: 0
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: pytorch
image: debug-dist-pytroch-minst:$VERSION
args: ["--backend", "nccl", "--dir", "/tmp/tb/nccl-$VERSION", "--epochs", "20", "--batch-size", "1024"]
resources:
limits:
nvidia.com/gpu: 1
Docker
The docker image is simply:
FROM pytorch/pytorch:1.10.0-cuda11.3-cudnn8-runtime
RUN pip install tensorboardX==1.6.0
RUN mkdir -p /opt/mnist
WORKDIR /opt/mnist/src
ADD mnist.py /opt/mnist/src/mnist.py
RUN chgrp -R 0 /opt/mnist \
&& chmod -R g+rwX /opt/mnist
ENTRYPOINT ["python", "/opt/mnist/src/mnist.py"]
Thank a lot for reading until the end ![]()