Hi there,
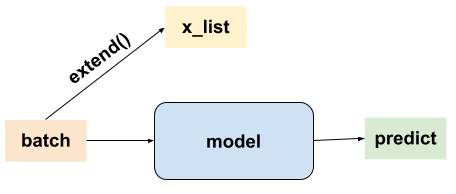
I am trying to build a cascaded model, model1 can be tested in batch (see below).
Then the resulting features of all the samples in the dataset should be concatenated and input to model 2 (kinda like a graph node prediction where all node features generated in model1 have to be aggregated in one graph).
After training, I am expecting to calculate the prediction derivatives in model2 w.r.t the input features in each samples used in model1, and somehow I got stuck and got None gradients. The general pipeline looks similar to the code below, if anyone could give me any idea of what went wrong that would be awesome, thanks ![]()
To reproduce:
import torch.nn as nn
import torch
from torch.utils.data import Dataset, DataLoader
class datasetTest(Dataset):
def __init__(self):
super(datasetTest, self).__init__()
self.x = torch.rand(1024, 3)
def __getitem__(self, item):
return self.x[item]
def __len__(self):
return self.x.shape[0]
class Model1(nn.Module):
def __init__(self):
super(Model1, self).__init__()
self.l1 = nn.Linear(3, 64)
def forward(self, x):
return torch.relu(self.l1(x))
class Model2(nn.Module):
def __init__(self):
super(Model2, self).__init__()
self.l2 = nn.Linear(64, 128)
self.droput = nn.Dropout()
def forward(self, x):
x = torch.relu(self.l2(x))
x = self.droput(x)
return x
model1 = Model1().eval() # a pyg model with graph input
model2 = Model2().eval() # model with dropout layers
dataset = datasetTest()
dataloader = DataLoader(dataset, batch_size=16)
feature_list = []
x_list = []
for batch in dataloader:
batch.requires_grad_(True)
feature = model1(batch) # model1 on one sample
x_list.extend(batch)
feature_list.extend(feature)
feature_dataset = torch.stack(feature_list, dim=0) # get the feature of all the samples in the dataset
feature_dataset.requires_grad_(True)
predict = model2(feature_dataset) # prediction for the whole dataset
# what I want to do: prediction derivative w.r.t. original inputs, got None
deriv = torch.autograd.grad(outputs=predict, inputs=x_list, grad_outputs=torch.ones_like(predict),
allow_unused=True, retain_graph=True, create_graph=True)
# feature_dataset -> original inputs : got None
deriv = torch.autograd.grad(outputs=feature_dataset, inputs=x_list, grad_outputs=torch.ones_like(feature_dataset),
allow_unused=True, retain_graph=True, create_graph=True)
# what I am able to do: predict -> feature_dataset: has values
deriv = torch.autograd.grad(outputs=predict, inputs=feature_dataset, grad_outputs=torch.ones_like(predict),
allow_unused=True, retain_graph=True, create_graph=True)