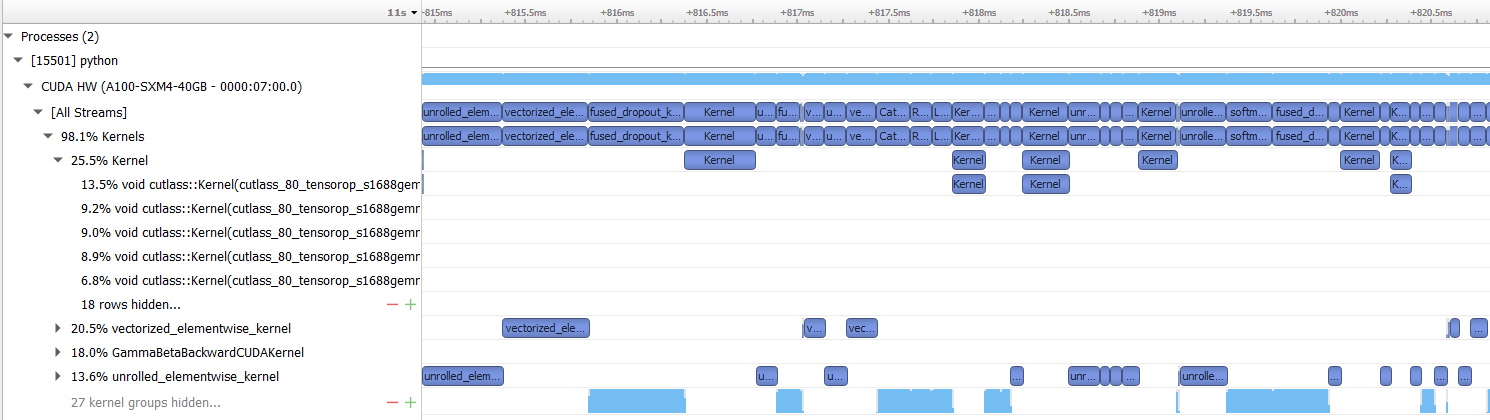
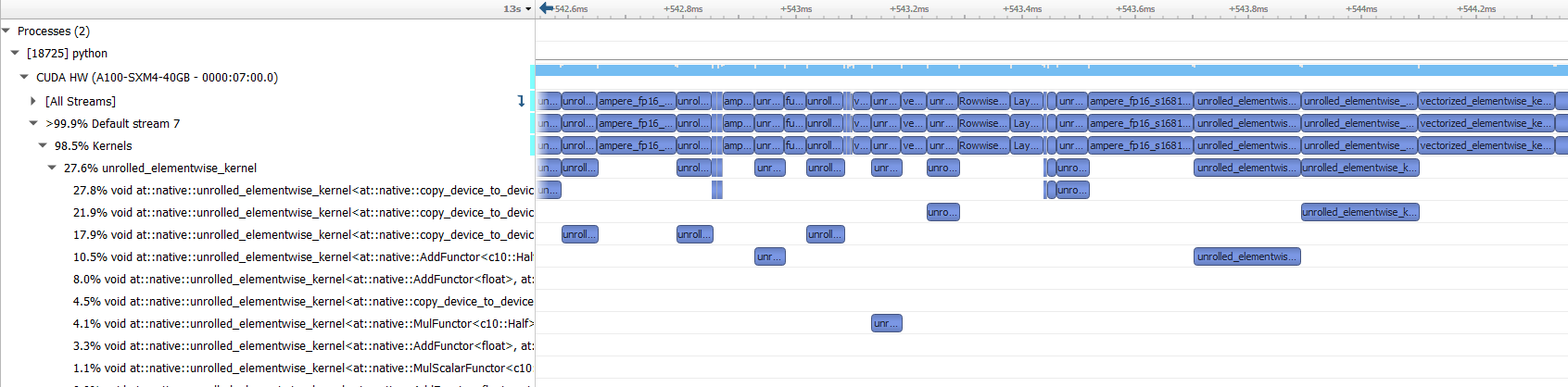
I am trying to use torch.cuda.amp to speed up training. The following code works well on V100 (120s w/o amp and 67s w/ amp), but cannot get a reasonable speedup on A100 (53s w/o amp and 50s w/ amp).
I am using the most recent NGC docker nvcr.io/nvidia/pytorch:21.04-py3, which has CUDA 11.3, pytorch 1.9.0.
The strange thing is if I change the model to resnet101, both V100 and A100 can get speedup, but not for the swin transformer on A100. See the following table for the running time (in sec) on different machines.
| resnet101 | resnet101 amp | swin_base | swin_base amp | |
|---|---|---|---|---|
| V100 | 49.19 | 19.62 | 120.07 | 67.19 |
| A100 | 40.9 | 29.35 | 47.19 | 44.97 |
| A100 w/ docker | 24.32 | 13.26 | 53.68 | 50.04 |
import torch
import argparse
import os
import time
import timm
from tqdm import trange
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, default='swin_base')
parser.add_argument("--fp16", action='store_true')
args = parser.parse_args()
N = 32
input_size = 384
x = torch.randn(N, 3, input_size, input_size).cuda()
y = torch.randint(1000, (N,)).cuda()
if args.model == 'swin_base':
model = timm.create_model('swin_base_patch4_window12_384').cuda()
elif args.model == 'resnet101':
model = timm.create_model('resnet101').cuda()
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
if args.fp16:
scaler = torch.cuda.amp.GradScaler()
start = time.time()
for t in trange(100):
# optimizer.zero_grad()
with torch.cuda.amp.autocast(enabled=args.fp16):
y_pred = model(x)
if args.fp16:
assert y_pred.dtype is torch.float16
loss = loss_fn(y_pred, y)
if args.fp16:
scaler.scale(loss).backward()
else:
loss.backward()
# optimizer.step()
end = time.time()
print('Time:', end-start)