I’m not familiar with this model, but note that you are already using TensorCores on the A100, since TF32 is enabled by default. With a proper synchronization I get a runtime of:
FP32: 102s
TF32: 50s
AMP: 47s
Based on the profile it also seems that the majority or kernels are (vectorized/unrolled) elementwise kernels and sporadically a cublas kernel is called:
FP32:
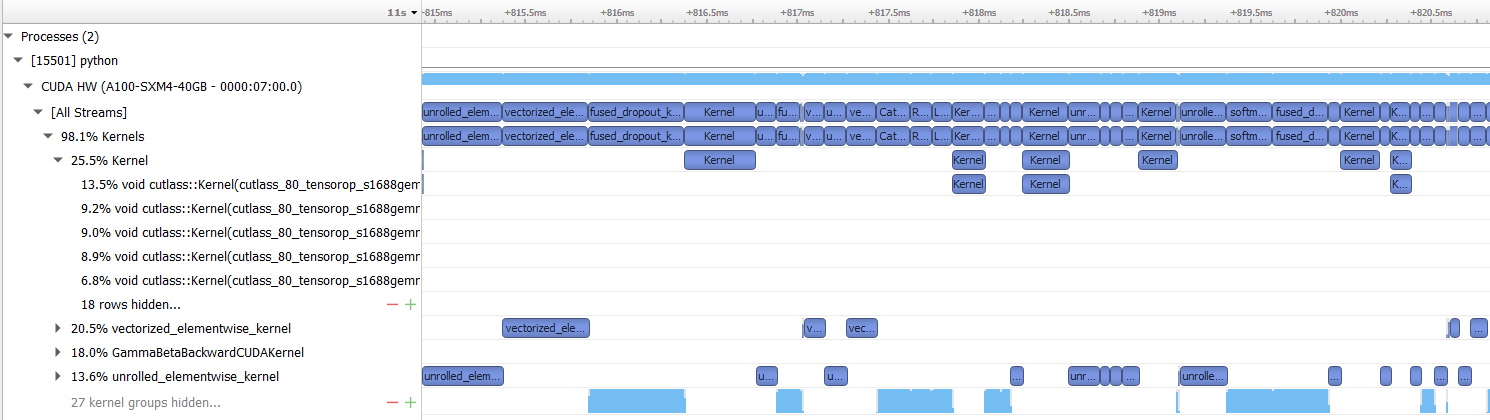
FP16:
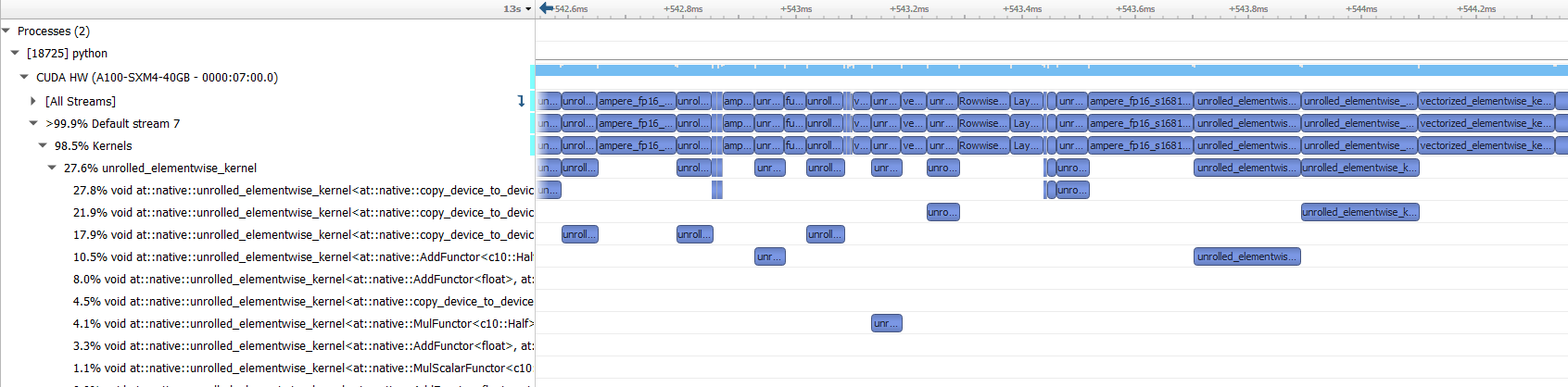
Based on the Ops that can autocast to float16 it seems that no many of these operations are used.