i was trying to _record_memory_history() api to get a snapshot of the memory allocations and profile my code, upon observation i saw a lot of memory fragmentations.
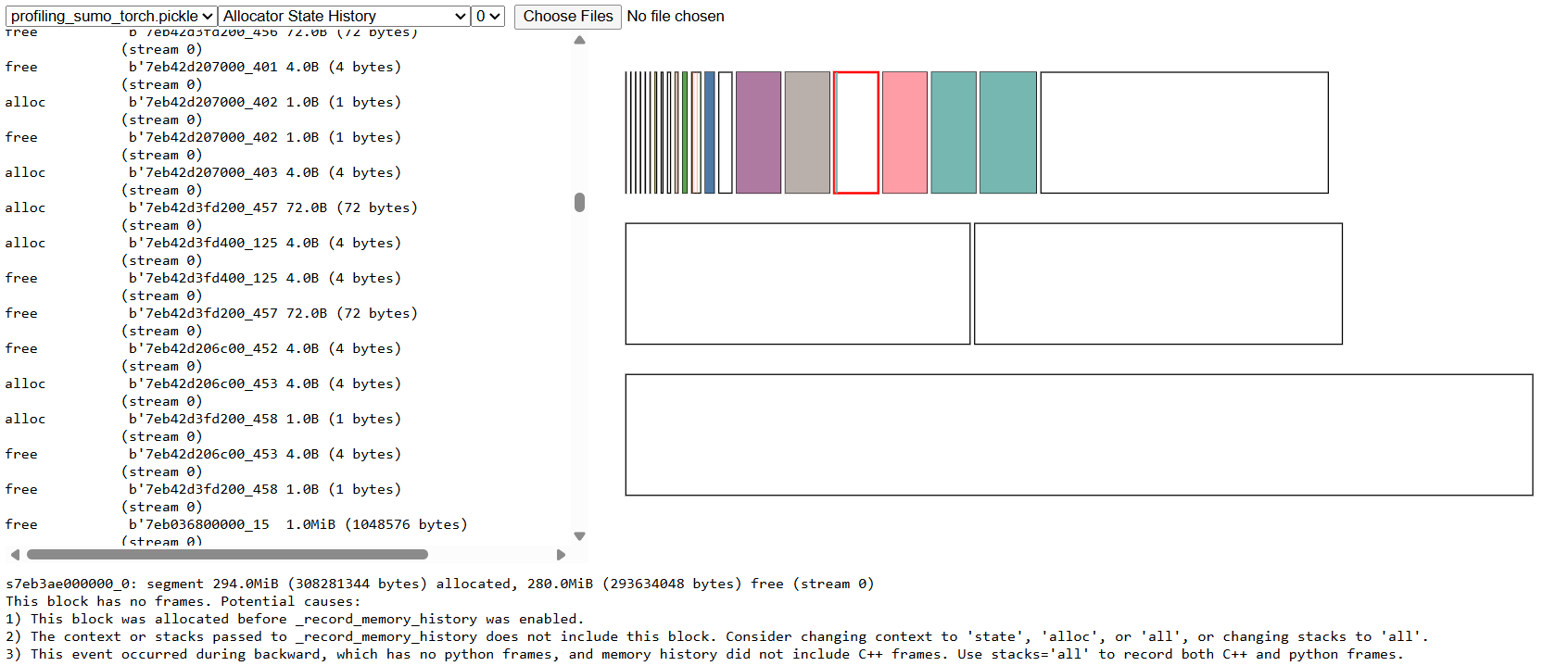
upon referring to referring to CUDA semantics — PyTorch 2.9 documentation , i saw that you can set PYTORCH_CUDA_ALLOC_CONF=backend:cudaMallocAsync to call cuda’s async memory allocation api which should ideally avoid fragmentation. but i wasn’t able to execute record_memory_snapshot and ran into this error, and says that it is not supported yet.
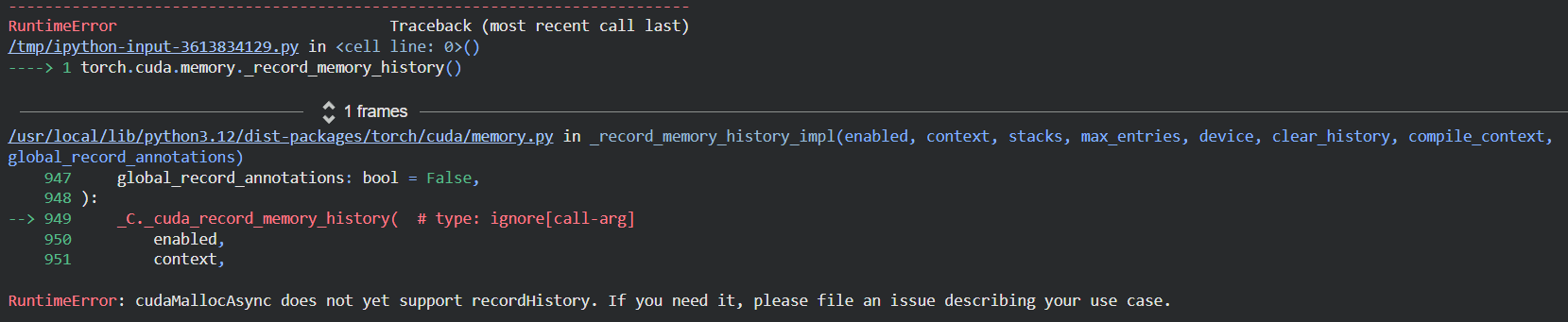
why is it the case ?
or are there any workarounds for this ?
also how can i avoid fragmentation, or any tips in general to be aware of ?
PS : I’m very new to profiling torch, so any help would be greatly appreciated.
Thanks!