Hi everyone!
I’m having an issue where I’m pretty confident that CUDA and pytorch are setup properly, but I’m nevertheless failing to initialize pytorch with CUDA:
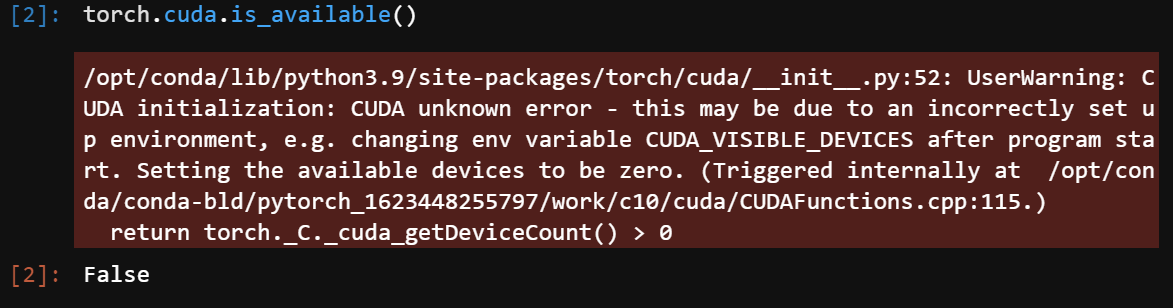
The context of my situation is that I’m setting up JupyterHub on AKS by building on top of the JupyterHub pyspark image which has Ubuntu (focal) as its base image. The AKS node image version that I’m using is AKSUbuntu-1804gen2gpucontainerd-2021.08.07, which has the NVIDIA 470.57.02 driver version.
In my dockerfile that I use to build on top of the JupyterHub PySpark image, I use the following to install CUDA and then install PyTorch (which I essentially just copied from the installation instructions online).
USER root
# Add directories to conda virtual environments
RUN mkdir /etc/conda && \
echo -e "envs_dirs:\n - /home/jovyan/my-conda-envs/\n - /home/jovyan/shared/shared-conda-envs" > /etc/conda/.condarc
# Install cURL, bash, Azure CLI, ViM, tmux, essential GNU compiler collection (C, C++ compiler), PCI utils, linux headers.
RUN apt-get upgrade && apt-get update && \
apt-get install -y apt-utils && \
apt-get install -y \
curl \
bash \
vim \
tmux \
htop \
build-essential \
pciutils \
linux-headers-$(uname -r) && \
curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash
# Install CUDA and clean stuff up
RUN echo 'debconf debconf/frontend select Noninteractive' | sudo debconf-set-selections && \
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin && \
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600 && \
wget https://developer.download.nvidia.com/compute/cuda/11.4.1/local_installers/cuda-repo-ubuntu2004-11-4-local_11.4.1-470.57.02-1_amd64.deb && \
sudo dpkg -i cuda-repo-ubuntu2004-11-4-local_11.4.1-470.57.02-1_amd64.deb && \
sudo apt-key add /var/cuda-repo-ubuntu2004-11-4-local/7fa2af80.pub && \
sudo apt-get update && \
sudo apt-get -y install cuda && \
apt-get clean && rm -rf /var/lib/apt/lists/*
USER ${NB_UID}
# Install pytorch
RUN mamba install --quiet --yes \
pytorch \
torchvision \
torchaudio \
cudatoolkit=11.1 \
-c pytorch \
-c nvidia \
&& \
mamba clean --all -f -y && \
fix-permissions "${CONDA_DIR}" && \
fix-permissions "/home/${NB_USER}"
WORKDIR "${HOME}"
I can post the entire dockerfile if needed (it’s not too long), but I thought that this was the relevant part.
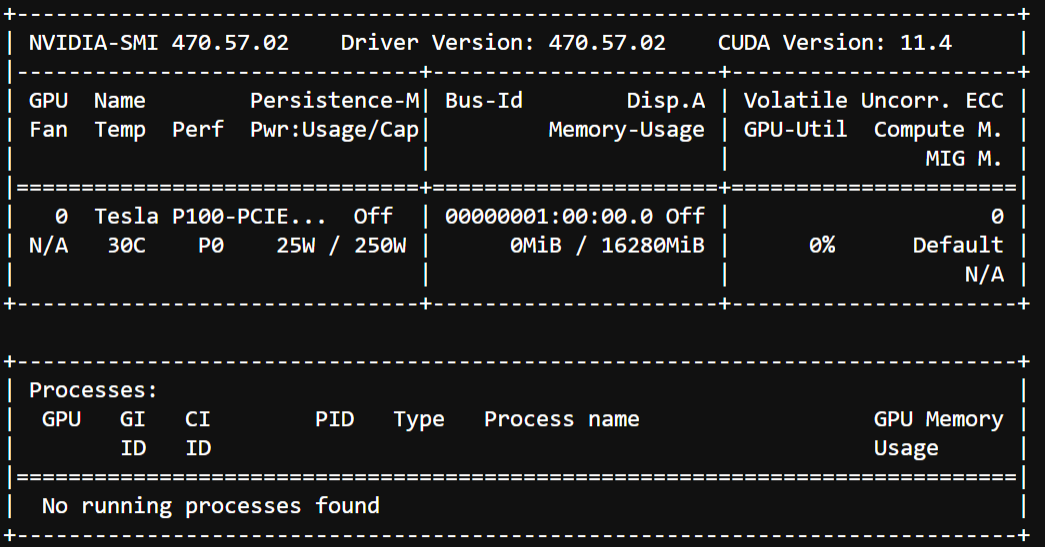
When I start up a terminal in JupyterHub and run nvidia-smi, I get the following positive output showing that CUDA is properly setup with version 11.4 and can detect my single Tesla P100 GPU:
Additionally, collect_env.py also detects the GPU, but not CUDA:
jovyan@jupyter-nomi-20ringach:~/RCA_test$ python collect_env.py
Collecting environment information...
/opt/conda/lib/python3.9/site-packages/torch/cuda/__init__.py:52: UserWarning: CUDA initialization: CUDA unknown error - this may be due to an incorrectly set up environment, e.g. changing env variable CUDA_VISIBLE_DEVICES after program start. Setting the available devices to be zero. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448255797/work/c10/cuda/CUDAFunctions.cpp:115.)
return torch._C._cuda_getDeviceCount() > 0
PyTorch version: 1.9.0
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.9.6 | packaged by conda-forge | (default, Jul 11 2021, 03:39:48) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-1055-azure-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: Tesla P100-PCIE-16GB
Nvidia driver version: 470.57.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.2
[pip3] torch==1.9.0
[pip3] torchaudio==0.9.0a0+33b2469
[pip3] torchvision==0.2.2
[conda] blas 2.108 mkl conda-forge
[conda] blas-devel 3.9.0 8_mkl conda-forge
[conda] cudatoolkit 11.1.74 h6bb024c_0 nvidia
[conda] libblas 3.9.0 8_mkl conda-forge
[conda] libcblas 3.9.0 8_mkl conda-forge
[conda] liblapack 3.9.0 8_mkl conda-forge
[conda] liblapacke 3.9.0 8_mkl conda-forge
[conda] mkl 2020.4 h726a3e6_304 conda-forge
[conda] mkl-devel 2020.4 ha770c72_305 conda-forge
[conda] mkl-include 2020.4 h726a3e6_304 conda-forge
[conda] numpy 1.21.2 py39hdbf815f_0 conda-forge
[conda] pytorch 1.9.0 py3.9_cuda11.1_cudnn8.0.5_0 pytorch
[conda] torchaudio 0.9.0 py39 pytorch
[conda] torchvision 0.2.2 py_3 pytorch
I’ve seen similar issues on the forum, but none of them seem to quite address or solve my particular issue. I’d also be content with a way to debug this, since the error message isn’t very specific.
Any help, tips, or advice would be amazing!
Thank you!
