I am coding Dataloader for my own data. I return output as numpy but dataloader gives me torch.Tensor as the output. Don’t understand why.
from torch.utils import data
import torch
import nibabel as nib
class getdata(data.Dataset):
'''
Initializes a dataset for the network
Assumes that the data_dir has files named MRimages and CTimages that contain all the images
for all the patients in .hdr format.
'''
def __init__(self,data_dir,transform):
'Initialization'
self.data_dir = data_dir
self.transform = transform
self.list_IDs = np.arange(nib.load(self.data_dir+ '/MRimages.img').shape[2]) #list of all patients.
def __len__(self):
'Total no. of samples. Make sure that number of MR and CT samples are same.'
num = len(self.list_IDs) #total number of slices.
return num
def __getitem__(self,index): #index is patient ID
'Generate one sample of data'
ID = self.list_IDs[index]
MR = np.asarray(nib.load(self.data_dir+ '/MRimages.img').get_data()[:,:,ID])
CT = np.asarray(nib.load(self.data_dir+ '/CTimages.img').get_data()[:,:,ID])
sample = {'MR': MR,'CT': CT}
if self.transform:
sample = self.transform(sample)
return sample
Calling function:
data_dir = '...'#my data directory
a = np.arange(nib.load(data_dir+ '/MRimages.img').shape[2])
params = {'batch_size': 64,
'shuffle': True,
'num_workers': 2}
train_set = getdata(data_dir,transform=None)
train_gen = data.DataLoader(train_set,**params)
for s in train_gen:
print(type(s['MR']))
This gives me <class ‘torch.Tensor’> for every batch.
I want to make the self.tranform as class that works on numpy matrix and not torch matrix.
Any suggestions?
The reason for your DataLoader returning torch.tensors even though are are returning numpy arrays is most likely due to the usage of the default_collate method. You can see in the line of code I’m referring to how numpy arrays are wrapped in torch.tensors.
If you check the type of train_set[0] you should get a numpy array, which means that the transform in __getitem__ is actually working on numpy arrays. The DataLoader just makes your life a bit easier as you probably want to use torch.tensors in your training loop.
That makes sense. So my numpy arrays are contained in a torch batch, so I can do transform on numpy.
Another question. So I am assuming that since my batch size is 64, when getitem is called, the list ID should have 64 random indices that are used to get the images.
But when I do MR.transpose((2,1,0)), I get ValueError: axes don't match array error
And then MR.transpose((1,0)) works fine. So it seems that it’s getting ID one by one.
I want to do my self.transpose on 3D arrays and not on 2D arrays.
Is there something I am doing wrong? Also my pytorch version is 0.4.1.post2
The __getitem__ method uses an index to get a single samples not a batch, i.e. the batch dimension of your data is missing in __getitem__.
Usually this makes developing of a custom Dataset really easy, as you just have to think about how to get a single samples of data. The DataLoader yields a complete batch of samples and provides some additional functionalities like shuffling the dataset or using multiple workers.
It seems in your use case you would like to load a whole bunch of slices of your MRI images.
Could you print the shapes of MR and CT in __getitem__ since I’m currently not sure how your indexing works.
I assume the shape you’ve printed is the shape of the batch from the DataLoader.
If that’s the case your MR and CT data have the shape [200, 200] in __getitem__.
Based on your description it seems you would like to apply the same transformation on the whole batch instead of each single image.
If that’s the case one approach would be to create an own sampler and provide a list of random indices to your Dataset.
In the __getitem__ you would get a list of indices of the length batch_size, could load all images one by one and apply the same transformation on them.
In the training loop you would get an additional batch dimension and can just squeeze it.
Here is a small example:
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, index):
x = torch.stack([self.data[i] for i in index])
return x
def __len__(self):
return len(self.data)
class RandomBatchSampler(torch.utils.data.sampler.Sampler):
def __init__(self, data_source, batch_size):
self.data_source = data_source
self.batch_size = batch_size
def __iter__(self):
rand_idx = torch.randperm(len(self.data_source)).tolist()
data_iter = iter([rand_idx[i:i+self.batch_size] for i in range(0, len(rand_idx), self.batch_size)])
return data_iter
def __len__(self):
return len(self.data_source)//self.batch_size
data = torch.randn(100, 3, 24, 24)
dataset = MyDataset(data)
batch_size = 64
sampler = RandomBatchSampler(data, batch_size=batch_size)
loader = DataLoader(
dataset,
batch_size=1,
num_workers=2,
sampler=sampler
)
for x in loader:
x.squeeze_(0)
print(x.shape)
Is there a way to switch the default_collate fn off, since I dont needit, and it makes my live much more complicated …
My return from the CustomDataset would be a pandas.DF (which doesn’t work with the collate_fn).
If I use the list as return, the collate-fn makes very ugly-unreadable tensors out of it.
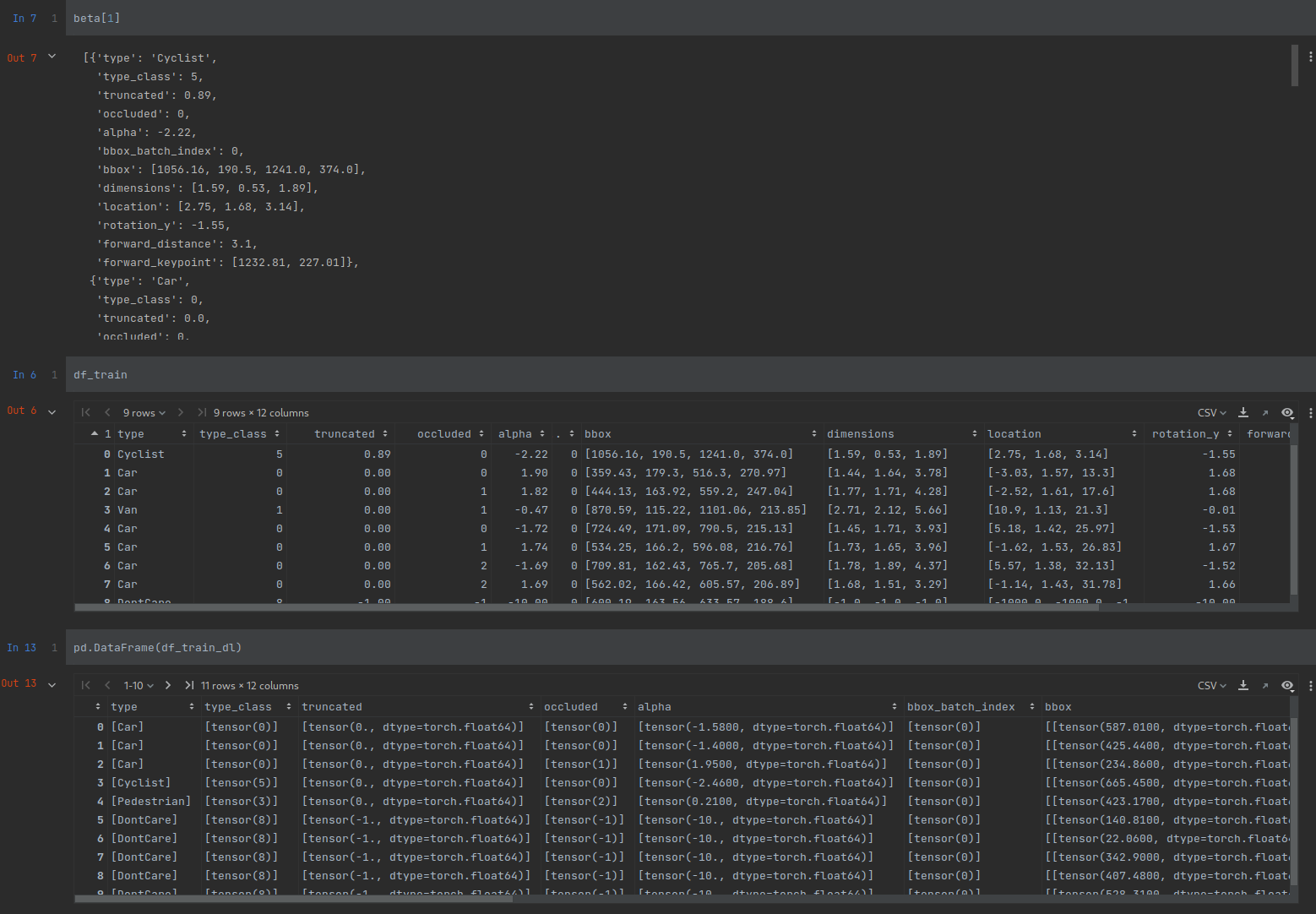
beta[1]: Is the usual return of the CustomDataset (type: list) df_train: Is the pd.Dataframe of beta[1] pd.DataFrame(df_train_dl): Is the output of the DataLoader as pd.DataFrame
as stacked tensors are expected.
You should be able to directly return the pd.DataFrames, but then your model would most likely not accept it (or you would transform the input to proper tensors in your forward which also sounds quite late).
Yes, I would recommend transforming the data into a tensor inside the __getitem__ so that the default collate function could then create batches from these samples.
Would this work or does it not fit your use case?
I don’t need any batches, so just returning the following would be good enough: 1. feature: image – for CNN feature extractor –– could be easily converted to Tensor in the __getitem__) 2. feature: BoundingBoxes – for ROI pooling –– (not needed as Tensor) 3. feature: Keypoints (maye used later) –– (not needed as Tensor) 4. feature: type (object classes) – not sure; if I really use it, since I want to use a classifier –– (could be easily converted to Tensor in the __getitem__) y: label: distance –– (could be easily converted to Tensor in the __getitem__)
Items 2–y usually would be in the pd.DF. But I wouldn’t have issues with return them one-by-one.
The issue is, that right now everything already works manually (every transform, resize, …).
From fetching the Data, to the CNN-feature-extractor, to the roi_pooling and my last two “models” aka “custom_classifier” and “distance_regressor” (which is not done).
Just wanted to automate it now with the DataLoader and stuck with the collate_fn which is causing me problems now …
So my questions would be:
Do I really need the collate_fn?
What kind of real benefit does the collate_fn have (since my model already works manually great)?
What kind of disadvanteges do I have by using: collate_fn= None, batch_size=None
It seems like the DataLoader still returns my image, and my target (pd.Dataframe), but doesn’t apply the collate_fn (as described by pytorch-Doc.).
But is this kind of “equal” to “batch_size=1”, just that I don’t get the extra batch_dim in my image, data, …?
So let’s say I would use 2): Do you see any problems by doing so?
You don’t necessarily need to use a collate_fn, but then automatic batching would be disabled. The DataLoader could still be useful, e.g. if you want to shuffle the dataset, but you could also directly iterate the Dataset alternatively.
Yes, this approach would be similar to just specifying a batch size of 1, but note that you might need to further process the data (in case its not in tensors already).
Yes, this should work but are you sure that a batch size of 1 is really what you want and that you won’t increase it during training?
Thanks! @1) Yes; using the DL for shuffling is still great. That’s why I want to use the DL. @2) Great – good to know.
Batch size = 1 should be good, and enough, since every picture has a couple of rois (up to 9+ per image, which are passing my_classifier and distance_regressor one after another. So these rois are already kind of my “batch” with which my two models are trained.
(The paper I am trying to reproduce also just used batch size = 1; so hopefully they were not sooo wrong )