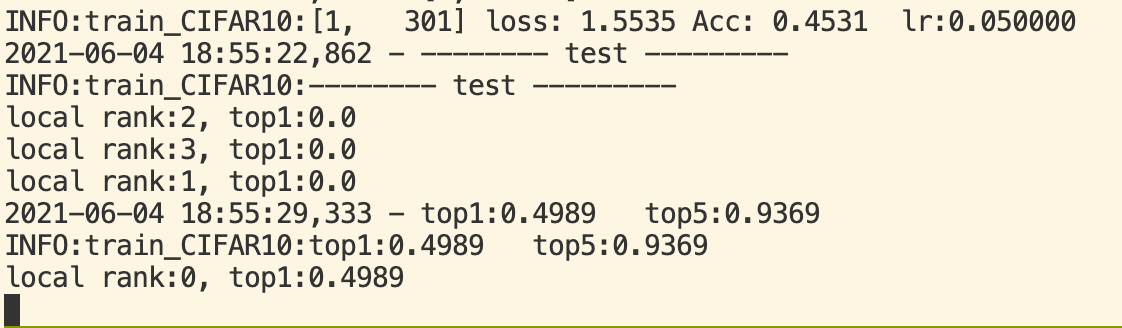
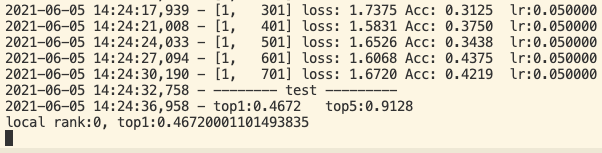
when I train a model using DDP in 4 GPUs and evaluate it in one GPU with args.local_rank==0, I want to broadcast the top1 to other GPUs. but I got the deadlock. The GPUs (local_rank=1,2,3) just enter the next command without blocking to get the broadcast results.
The code is shown below. It was execuated after finishing training one epoch.
Hi, @mrshenli
I created a mini-repo: GitHub - SHu0421/Question-Repo. you can directly run it by bash train.sh. my torch version is 1.8.1 and the cuda version is 10.2.
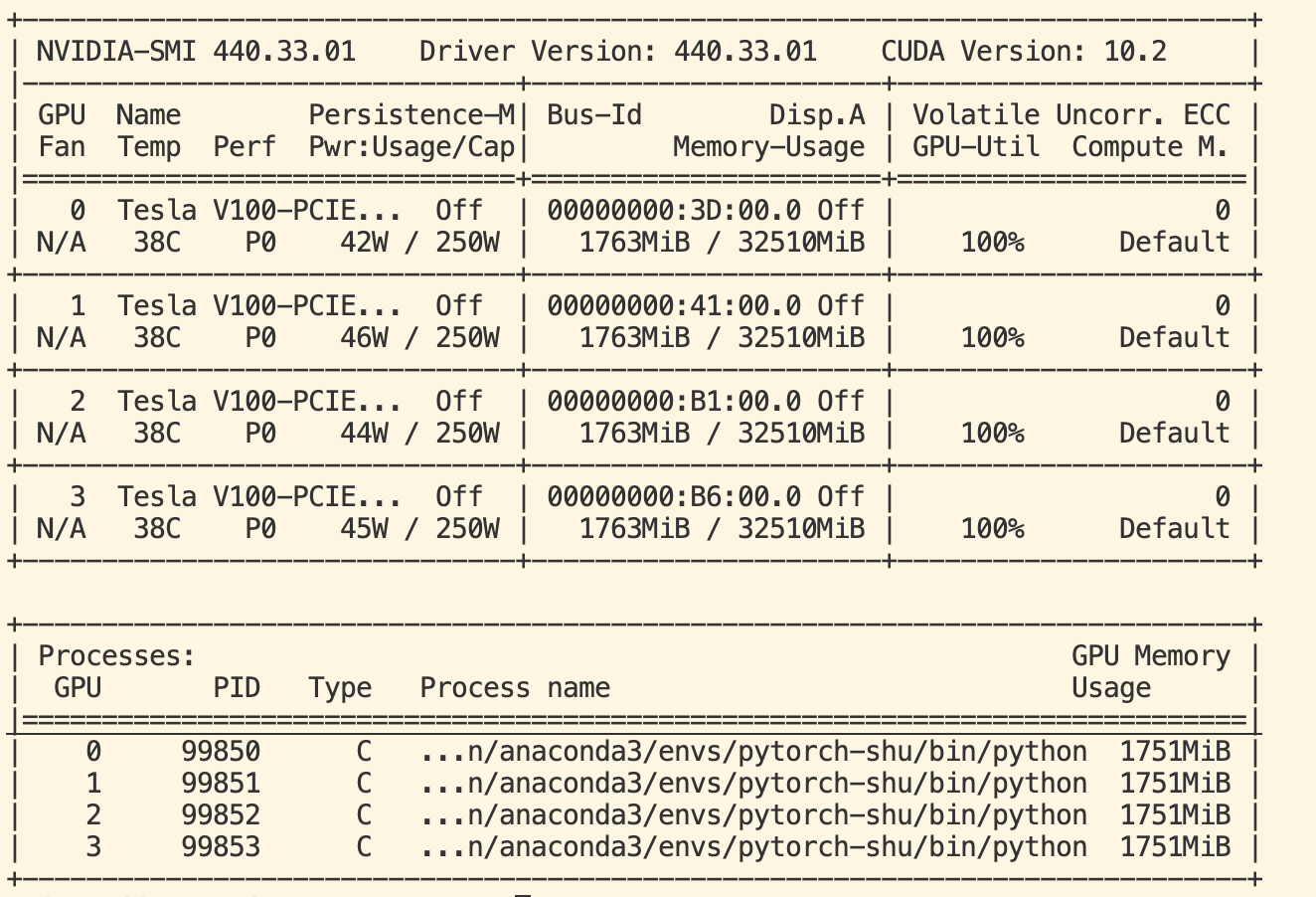
I run the code on four Tesla v100 GPUs (one node). It hung out as before with all GPUs usage 100%