Recently I have migrated a simple parallel orthogonalization function from numpy to pytorch. However, the torch.eig() function seems very unstable (or the precision is very low).
The core of the code is the following:
# Step1: Initialization:
P_cuda = torch.randn([300,40000]).type(dtype)
# Step2: orthogonalization:
L = torch.mm(P_cuda,P_cuda.t())
w,v = torch.eig(L,eigenvectors=True)
U = torch.mm(torch.mm(v,torch.diag(torch.sqrt(1./w[:,0]))),v.t())
P_cuda = torch.mm(U,P_cuda)
# Step3: Now the rows of P_cuda should be orthogonal and normalized that L2 norm is 1. So the output of the following code should be very close to 300.
normSquareSum = torch.pow(P_cuda,2).sum()
print(normSquareSum)
The first iteration of step2 and step seems successful. However, when I repeat them, I get a bunch of different numbers range from 300 to 370. Is this due a low precision of torch.eig()? If this is the case, how can I improve the precision? This result makes the algorithm almost unusable since if I loop these 2 steps a little while, it will give me a nan.
The above code has a numpy implementation, which is a direct translation. The numpy version on the other hand is very stable and gives constantly 300. It is attached here too for comparison:
def orthogonalization_parallel(P):
#This method orthogonalizes and normalizes the rows of P and the original matrix will not be changed.
#P -> P_ such that P_*P_^T = I
w, v = la.eig(np.dot(P,P.T))
U = np.dot(np.dot(v,np.diag(np.sqrt(1./w))),v.T)
return np.dot(U,P)
My pytorch version is ‘0.2.0_4’.
Thanks a lot for your help in advance!
I was thinking about upgrading to 0.3 and see if that solves the problem. But the conda default upgrading seems will replace 0.2 with 0.18, which was a little weird. Do you know a good way to upgrade from 0.2 to 0.3?
I do have cuda 8 installed, but when I used the instruction you provided. A lot of packages got downgraded and further the pytorch version is now downgraded to 0.1.12 as I previously said. Do you have an idea why this is the case?
user_data$ conda install pytorch -c pytorch
Fetching package metadata .............
Solving package specifications: .
The following NEW packages will be INSTALLED:
libtorch: 0.1.12-0
mkl-rt: 11.1-p0
The following packages will be UPDATED:
conda: 4.3.30-py27h6ae6dc7_0 --> 4.4.4-py27_0
mkl: 11.3.3-0 --> 2017.0.4-h4c4d0af_0
pycosat: 0.6.2-py27h1cf261c_1 --> 0.6.3-py27ha4109ae_0
The following packages will be SUPERSEDED by a higher-priority channel:
pytorch: 0.2.0-py27hc03bea1_4cu80 soumith [cuda80] --> 0.1.12-py27_0
torchvision: 0.1.9-py27hdb88a65_1 soumith --> 0.1.8-py27_0
The following packages will be DOWNGRADED:
accelerate: 2.3.1-np111py27_0 --> 2.0.1-np110py27_p0
cudatoolkit: 8.0-3 --> 7.0-1
llvmlite: 0.15.0-py27_0 --> 0.8.0-py27_0
mkl-service: 1.1.2-py27_3 --> 1.1.0-py27_p0
numba: 0.30.1-np111py27_0 --> 0.22.1-np110py27_0
numexpr: 2.6.1-np111py27_1 --> 2.4.4-np110py27_p0 [mkl]
numpy: 1.11.2-py27_0 --> 1.10.2-py27_p0 [mkl]
scikit-image: 0.13.0-py27h06cb35d_1 --> 0.12.3-np110py27_1
scikit-learn: 0.18.1-np111py27_0 --> 0.17-np110py27_p1 [mkl]
scipy: 0.18.1-np111py27_0 --> 0.16.1-np110py27_p0 [mkl]
Proceed ([y]/n)? y
Yikes. I’ve seen some other people report this as well. You might need to update your conda first. You can do this with conda update conda, and then try conda install pytorch -c pytorch again.
I have just tested the 0.3. It’s the eig() function will give an oscillation too. This seems to be a bug and it might need some work to verify the function’s stability.
The configuration:
GPU: 1080 Ti, with driver 387.26.
PyTorch Version: ‘0.3.0.post4’.
The easiest way to reproduce the result is to loop the following code after the step-1 initialization (only initialize once):
L = torch.mm(P_cuda,P_cuda.t())
w,v = torch.eig(L,eigenvectors=True)
v.mul_(torch.sqrt(torch.sqrt(1./w[:,0])))
U = torch.mm(v,v.t())
P_cuda = torch.mm(U,P_cuda)
print(w)
Ideally, after 1 step, the print should be all real number 1’s. However, this gives me quite a bunch different eigenvalues. I wonder if the problem comes from a large ‘tolerance’ setting in the back-end implementation of this function.
I guess I don’t have to use this function since there is torch.symeig(). But this is still a problem worth investigation. symeig() is quite stable.
Okay. I looked into this a little bit, and I think I have some more insight into what’s going on.
I don’t 100% understand the math behind your code, but I’ve noticed the following:
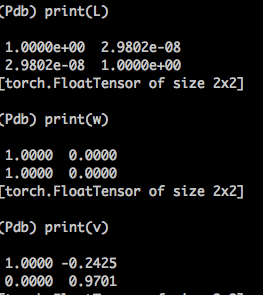
When one sends the identity matrix through torch.eig() (or something very close to it) it seems like it just returns any vector as the eigenvectors. For example, in a 2 x 2 case:
(the top is the original vector L and the bottom is the result of v, w = torch.eig(L, eigenvectors=True)).
Does your code rely on any properties of the returned eigenvectors? I know torch.symeig is nice because the returned eigenvectors are guaranteed to satisfy L = V W V^T
Thanks a lot for looking into this! My code needs both eigenvalues and eigenvectors. In your case, it seems that the eigenvectors are not orthogonal to each other, which might be part of the reason why the oscillation happened in the loop of my code.
Torch.symeig() works well for me now. I just figured that torch.eig() function is very important too since sometimes people just pick either of them to do some quick experiement. Do you think there is a bug in the eig() function?
I think your code might be assuming that the eigenvectors are orthogonal to each other, which would explain why torch.symeig works but torch.eig doesn’t work.
The docs don’t give any guarantees on the results of torch.eig so this might not be a bug. In the backend, torch.eig binds to Lapack (for CPU) and magma (for CUDA). At any rate, I don’t think the issue is a precision problem.
I see … I never realized that eig() function doesn’t have this guarantee.
I think the reason leads me to this false prior that the eigenvectors returned by torch.eig() are orthonormal is that the eig() function in both numpy and matlab has this property. And that’s why in a lot of cases I use eig() and eigh() interchangeably when the matrix is Hermitian.
Anyway, this gives me a significant message and I will think twice before choosing between them in the future.
I also had trouble recently with the stability of eig() and symeig() results. I found that doing it in double precision was far, far superior. It went from holy-crap-how-can-this-happen to perfect results just with that one change.
If this is the case, then it might still be a precision issue of the underlying library used by pytorch. Not sure though, but I will never use eig() function since I’m living in the Hermitian world.
I did a poll in my research center and it turned out many other people had a similar expectation.
E.g. Given an identity matrix, of course the eigenvectors should not be unique up to a permutation since this is a degenerate problem (any rotation or reflection will be equally valid). However, people still tend to believe the result is going to be at least orthonormal.
I think this hidden bias are shared by many more people. In the document, there should be a warning on this and always suggest users to use symeig() if the matrix is Hermitian.
Thank you, I’ll add a warning to the docs to warn against the eigenvectors of torch.eig not being orthonormal.
I’ll also do some more investigation. numpy’s eig binds to Lapack (which is the same thing that torch.eig does on the CPU), so it seems weird to me that some inputs are strange. For example, for most of the cases I tested, when given a symmetric input torch.eig usually returns orthonormal vectors.