Hi,
I am trying to extract random “slices” of tensors.
Is there a torch equivalent of numpy.random.choice ?
And if not, is there a reason why not ?
Thanks
Hi,
I am trying to extract random “slices” of tensors.
Is there a torch equivalent of numpy.random.choice ?
And if not, is there a reason why not ?
Thanks
You could generate a random number between 0 and the size of the outer dimension of your tensor, and then use that to index into your tensor.
We don’t have a built-in function like numpy.random.choice.
Thanks!
Actually I wanted to draw k samples, and without replacement,
so I ended up doing :
perm = torch.randperm(tensor.size(0))
idx = perm[:k]
samples = tensor[idx]
(but maybe that’s not computationally efficient)
Well, the main advantage of numpy.random.choice is the possibility to pass in an array of probabilities corresponding to each element, which this solution does not cover. Even python’s random library enables passing a weight list to its choices() function.
Oh, are you looking for torch.multinomial? http://pytorch.org/docs/master/torch.html?highlight=multinomial#torch.multinomial
There is an issue currently opened in PyTorch’s github repo about that subject: https://github.com/pytorch/pytorch/issues/16897
A first version of a full-featured numpy.random.choice equivalent for PyTorch is now available here (working on PyTorch 1.0.0). It includes CPU and CUDA implementations of:
torch::randint )Update: There is currently a PR waiting for review in the PyTorch’s repo.
This is extremely slow and unacceptable.
In my case: values.shape = (386363948, 2), k = 190973, the following code works fairly fast, 0.1 ~ 0.2 second.
indice = random.sample(range(386363948), 190973)
indice = torch.tensor(indice)
sampled_values = values[indice]
Using torch.randperm, however, would cost more than 20 seconds.
sampled_values = values[torch.randperm(386363948)[190973]]
Answer here !
you can do simply by applying below logic
samples=torch.tensor([-11,5,9])
rand_choices=samples[torch.randint(len(samples),(7,))] #’'7 choices ‘’
print(rand_choices)
hope this helps!
is there a reason why you prefer:
rand_choices=samples[torch.randint(len(samples),(7,))] #’'7 choices ‘’
vs
**perm = torch.randperm(tensor.size(0))**
?
Just curious
Hi !
To clear things up
If you want to do the equivalent of numpy.random.choice:
a = np.array([1, 2, 3, 4])
p = np.array([0.1, 0.1, 0.1, 0.7])
n = 2
replace = True
b = np.random.choice(a, p=p, size=n, replace=replace)
In pytorch you can use torch.multinomial :
a = torch.tensor([1, 2, 3, 4])
p = torch.tensor([0.1, 0.1, 0.1, 0.7])
n = 2
replace = True
idx = p.multinomial(num_samples=n, replacement=replace)
b = a[idx]
Careful, np.random.choice defaults to replace=True
But torch.multinomial defaults to replacement=False
In case the *num_samples* is not int type, how to deal implement the above case? Thank you!
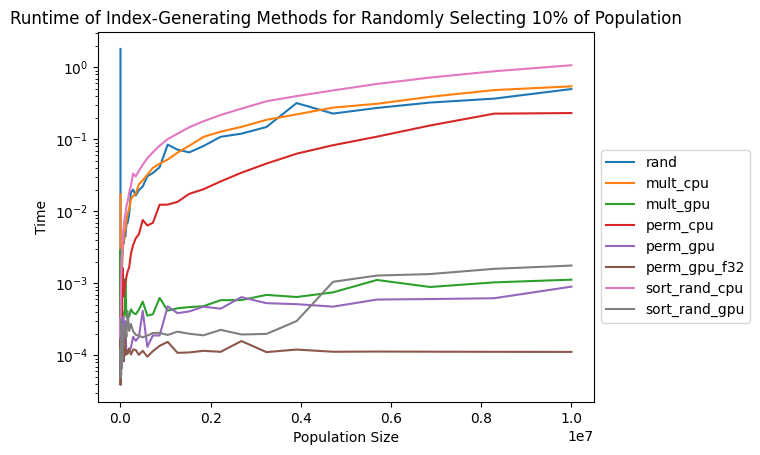
If anyone is here looking for fast ways to select samples, I created a small comparison to time some of the popular random indexing solutions from the forums. For the comparison, I wrote small functions with the goal of generating indices to select 10% of a population. For a fair comparison, the indices are returned as GPU-tensors.
It looks like, if your population size is less than int32.MAX_VALUE, generating a random permutation on the GPU may be the fastest solution. Mileage may vary, so I’ve included my entire plotting script below so you can test it.
import numpy as np
import torch
import random
import time
import pandas as pd
import matplotlib.pyplot as plt
def rand(pop_size, num_samples):
"""Use random.sample to generate indices."""
return torch.Tensor(random.sample(range(pop_size), num_samples)).to('cuda')
def mult_cpu(pop_size, num_samples):
"""Use torch.Tensor.multinomial to generate indices on a CPU tensor."""
p = torch.ones(pop_size) / pop_size
return p.multinomial(num_samples=num_samples, replacement=False).to('cuda')
def mult_gpu(pop_size, num_samples):
"""Use torch.Tensor.multinomial to generate indices on a GPU tensor."""
p = torch.ones(pop_size, device='cuda') / pop_size
return p.multinomial(num_samples=num_samples, replacement=False)
def perm_cpu(pop_size, num_samples):
"""Use torch.randperm to generate indices on a CPU tensor."""
return torch.randperm(pop_size)[:num_samples].to('cuda')
def perm_gpu(pop_size, num_samples):
"""Use torch.randperm to generate indices on a GPU tensor."""
return torch.randperm(pop_size, device='cuda')[:num_samples]
def perm_gpu_f32(pop_size, num_samples):
"""Use torch.randperm to generate indices on a 32-bit GPU tensor."""
return torch.randperm(pop_size, dtype=torch.int32, device='cuda')[:num_samples]
def sort_rand_cpu(pop_size, num_samples):
"""Generate a random torch.Tensor (CPU) and sort it to generate indices."""
return torch.argsort(torch.rand(pop_size))[:num_samples]
def sort_rand_gpu(pop_size, num_samples):
"""Generate a random torch.Tensor (GPU) and sort it to generate indices."""
return torch.argsort(torch.rand(pop_size, device='cuda'))[:num_samples]
idx_fns = [rand,
mult_cpu,
mult_gpu,
perm_cpu,
perm_gpu,
perm_gpu_f32,
sort_rand_cpu,
sort_rand_gpu]
pop_size = np.logspace(3, 7, 50, dtype=int)
d = []
for n_p in pop_size:
print(f"Testing functions with {n_p} points.")
for fn in idx_fns:
tic = time.time()
num_samples = int(0.1 * n_p)
samples = fn(n_p, num_samples)
toc = time.time()
assert type(samples) == torch.Tensor
d.append({
'Population': n_p,
'Samples': num_samples,
'Function':fn.__name__,
'Time': toc - tic
})
df = pd.DataFrame(d)
fig, ax = plt.subplots()
for fn in idx_fns:
idxs = df['Function'] == fn.__name__
ax.plot(df['Population'][idxs], df['Time'][idxs], label=fn.__name__)
ax.set_title("Runtime of Index-Generating Methods for Randomly Selecting 10% of Population")
ax.set_xlabel('Population Size')
ax.set_ylabel('Time')
ax.set_yscale('log')
ax.legend(bbox_to_anchor=(1, 0.7))
plt.savefig('figs/randperm.png', bbox_inches='tight')
plt.show()
Thanks for sharing the code!
Since GPU operations are executed asynchronously, you would have to synchronize the code manually before starting and stopping the timer via torch.cuda.synchronize() to get the real execution time.
Otherwise you might be profiling the kernel launch times and blocking operations would accumulate the execution time of already running kernels.
torch.utils.benchmark provides a utility to run such comparisons and will add warmup iterations and the needed synchronizations for you.
Ooh, thanks! I’ll have a look and see if I can update with proper benchmarks when I have a minute.
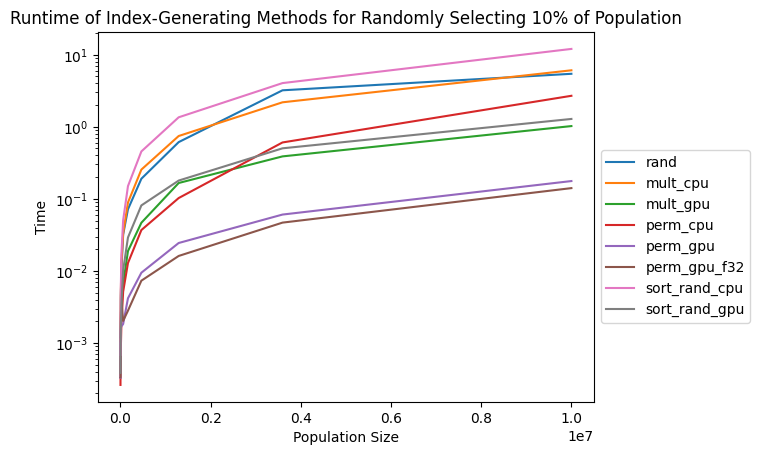
Here are the results with proper benchmarks! It looks like generating random permutations on the GPU is still the way to go, if you want to generate indices for random selection. However, the GPU methods do not scale quite as well as it seemed before.
I couldn’t find a good way to access the benchmark results, so I settled for timeit(N).raw_times[0], which seems to give the median time spent.
import numpy as np
import torch
import random
import pandas as pd
import matplotlib.pyplot as plt
import torch.utils.benchmark as benchmark
def rand(pop_size, num_samples):
"""Use random.sample to generate indices."""
return torch.Tensor(random.sample(range(pop_size), num_samples)).to('cuda')
def mult_cpu(pop_size, num_samples):
"""Use torch.Tensor.multinomial to generate indices on a CPU tensor."""
p = torch.ones(pop_size) / pop_size
return p.multinomial(num_samples=num_samples, replacement=False).to('cuda')
def mult_gpu(pop_size, num_samples):
"""Use torch.Tensor.multinomial to generate indices on a GPU tensor."""
p = torch.ones(pop_size, device='cuda') / pop_size
return p.multinomial(num_samples=num_samples, replacement=False)
def perm_cpu(pop_size, num_samples):
"""Use torch.randperm to generate indices on a CPU tensor."""
return torch.randperm(pop_size)[:num_samples].to('cuda')
def perm_gpu(pop_size, num_samples):
"""Use torch.randperm to generate indices on a GPU tensor."""
return torch.randperm(pop_size, device='cuda')[:num_samples]
def perm_gpu_f32(pop_size, num_samples):
"""Use torch.randperm to generate indices on a 32-bit GPU tensor."""
return torch.randperm(pop_size, dtype=torch.int32, device='cuda')[:num_samples]
def sort_rand_cpu(pop_size, num_samples):
"""Generate a random torch.Tensor (CPU) and sort it to generate indices."""
return torch.argsort(torch.rand(pop_size))[:num_samples]
def sort_rand_gpu(pop_size, num_samples):
"""Generate a random torch.Tensor (GPU) and sort it to generate indices."""
return torch.argsort(torch.rand(pop_size, device='cuda'))[:num_samples]
idx_fns = [rand,
mult_cpu,
mult_gpu,
perm_cpu,
perm_gpu,
perm_gpu_f32,
sort_rand_cpu,
sort_rand_gpu]
pop_size = np.logspace(3, 7, 10, dtype=int)
d = []
for n_p in pop_size:
print(f"Testing functions with {n_p} points.")
for fn in idx_fns:
num_samples = int(0.1 * n_p)
t0 = benchmark.Timer(
stmt=f"{fn.__name__}(n_p, num_samples)",
setup=f"from __main__ import {fn.__name__}",
globals={'n_p': n_p, 'num_samples': num_samples}
)
d.append({
'Population': n_p,
'Samples': num_samples,
'Function':fn.__name__,
'Time': t0.timeit(11).raw_times[0]
})
df = pd.DataFrame(d)
fig, ax = plt.subplots()
for fn in idx_fns:
idxs = df['Function'] == fn.__name__
ax.plot(df['Population'][idxs], df['Time'][idxs], label=fn.__name__)
ax.set_title("Runtime of Index-Generating Methods for Randomly Selecting 10% of Population")
ax.set_xlabel('Population Size')
ax.set_ylabel('Time')
ax.set_yscale('log')
ax.legend(bbox_to_anchor=(1, 0.7))
plt.savefig('figs/randperm.png', bbox_inches='tight')
plt.show()
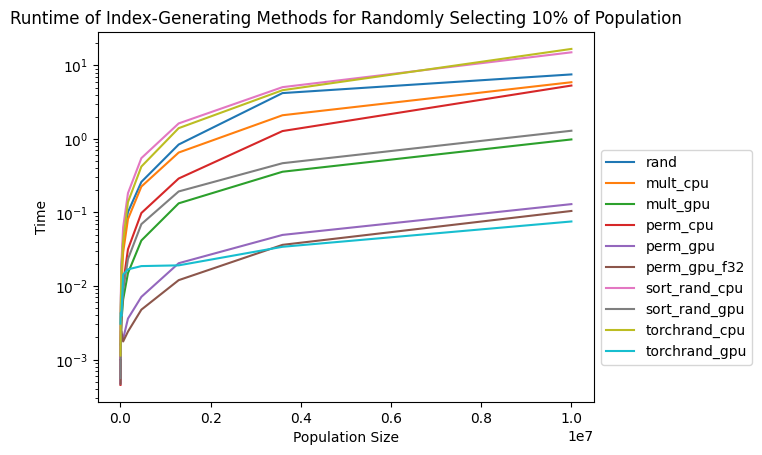
I had the same problem and came up with an additional way to implement my own, and it seems to work fairly well actually. I ran it with the code above (I’ll post my exact code below).
Do note that this is only highly useful if you don’t care about having random shuffles, but rather just random slices. If you want random shuffles, it has the same speed as randperm, more or less. This is due to torch.unique currently automatically sorting the array in the cuda case.
import numpy as np
import torch
import random
import pandas as pd
import matplotlib.pyplot as plt
import torch.utils.benchmark as benchmark
def rand(pop_size, num_samples):
"""Use random.sample to generate indices."""
return torch.Tensor(random.sample(range(pop_size), num_samples)).to("cuda")
def mult_cpu(pop_size, num_samples):
"""Use torch.Tensor.multinomial to generate indices on a CPU tensor."""
p = torch.ones(pop_size) / pop_size
return p.multinomial(num_samples=num_samples, replacement=False).to("cuda")
def mult_gpu(pop_size, num_samples):
"""Use torch.Tensor.multinomial to generate indices on a GPU tensor."""
p = torch.ones(pop_size, device="cuda") / pop_size
return p.multinomial(num_samples=num_samples, replacement=False)
def perm_cpu(pop_size, num_samples):
"""Use torch.randperm to generate indices on a CPU tensor."""
return torch.randperm(pop_size)[:num_samples].to("cuda")
def perm_gpu(pop_size, num_samples):
"""Use torch.randperm to generate indices on a GPU tensor."""
return torch.randperm(pop_size, device="cuda")[:num_samples]
def perm_gpu_f32(pop_size, num_samples):
"""Use torch.randperm to generate indices on a 32-bit GPU tensor."""
return torch.randperm(pop_size, dtype=torch.int32, device="cuda")[:num_samples]
def sort_rand_cpu(pop_size, num_samples):
"""Generate a random torch.Tensor (CPU) and sort it to generate indices."""
return torch.argsort(torch.rand(pop_size))[:num_samples]
def sort_rand_gpu(pop_size, num_samples):
"""Generate a random torch.Tensor (GPU) and sort it to generate indices."""
return torch.argsort(torch.rand(pop_size, device="cuda"))[:num_samples]
def torchrand(pop_size, num_samples, device: str):
vec = torch.unique(
(torch.rand(num_samples, device=device) * pop_size).floor().long()
)
# Eliminate all duplicate entries. Might slow down the procedure but totally worth it.
while vec.shape[0] != num_samples:
vec = torch.unique(
torch.cat(
[
vec,
(torch.rand(num_samples - vec.shape[0], device=device) * pop_size)
.floor()
.long(),
]
)
)
return vec.view(-1)
def torchrand_cpu(pop_size, num_samples, shuffle=False):
return (
torchrand(pop_size, num_samples, device="cpu")
if shuffle is False
else torch.randperm(pop_size)
) # [:num_samples]
def torchrand_gpu(pop_size, num_samples, shuffle=False):
return (
torchrand(pop_size, num_samples, device="cuda")
if shuffle is False
else torch.randperm(pop_size)
) # [:num_samples]
idx_fns = [
rand,
mult_cpu,
mult_gpu,
perm_cpu,
perm_gpu,
perm_gpu_f32,
sort_rand_cpu,
sort_rand_gpu,
torchrand_cpu,
torchrand_gpu,
]
pop_size = np.logspace(3, 7, 10, dtype=int)
d = []
for n_p in pop_size:
print(f"Testing functions with {n_p} points.")
for fn in idx_fns:
num_samples = int(0.1 * n_p)
t0 = benchmark.Timer(
stmt=f"{fn.__name__}(n_p, num_samples)",
setup=f"from __main__ import {fn.__name__}",
globals={"n_p": n_p, "num_samples": num_samples},
)
d.append(
{
"Population": n_p,
"Samples": num_samples,
"Function": fn.__name__,
"Time": t0.timeit(11).raw_times[0],
}
)
df = pd.DataFrame(d)
fig, ax = plt.subplots()
for fn in idx_fns:
idxs = df["Function"] == fn.__name__
ax.plot(df["Population"][idxs], df["Time"][idxs], label=fn.__name__)
ax.set_title(
"Runtime of Index-Generating Methods for Randomly Selecting 10% of Population"
)
ax.set_xlabel("Population Size")
ax.set_ylabel("Time")
ax.set_yscale("log")
ax.legend(bbox_to_anchor=(1, 0.7))
plt.savefig("figs/randperm.png", bbox_inches="tight")
plt.show()