[Problem description] I use torch.gather to index a tensor, and find uncontrollable randomness. Example code is below:
# batchsize=16, feature dim=3, pixels = 128
feature = torch.randn(16, 3, 128)
# index feature: find 64 pixels in 128 and search 24 relevant pixels all over 64 pixels.
pixel_index = torch.randint(0, 128, (16, 64, 24)).long().cuda()
pixel_index = pixel_index.view(16, 64*24).unsqueeze(1).expand(-1, 3, -1) # (16, 3, 64*24)
# get the indexed feature with shape (16, 3, 64, 24)
indexed_feature = torch.gather(feature, dim=2, index=pixel_index).view(16, 3, 64, 24)
Only using torch.gather once can get determined result while using it above twice would lead to undetermined result. All random seeds are fixed. I have found the key issue locates in the backward of torch.gather, but why? Is there a way to fix this quirky randomness?
[Test code for reproducing the issue]
import torch
import torch.optim as optim
import torch.nn as nn
import numpy as np
import os
import random
seed = 123
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
os.environ['PYTHONHASHSEED'] =str(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def gather_op(feat, idx):
"""
features : (B, C, N)
idx : (B, M)
return: (B, C, M)
"""
return torch.gather(feat, 2, idx.unsqueeze(1).expand(-1, feat.shape[1], -1))
class sampling(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, idx):
B, N, M = idx.shape
return gather_op(x, idx.view(B, N*M)).view(B, -1, N, M)
class model_test1(nn.Module): # only use gather_op once
def __init__(self, num_classes, input_dim=3):
super().__init__()
self.conv1d_L1 = nn.Conv1d(input_dim, 32, 1)
self.conv2d_L2 = nn.Conv2d(32, 128, 1)
self.relu = nn.ReLU(inplace=True)
self.sampling = sampling()
self.classifier = nn.Linear(128, 10)
def forward(self, x, idx):
x = self.relu(self.conv1d_L1(x)) # (16, 32, 128)
x = self.sampling(x, idx) # (16, 32, 64, 24)
x = self.relu(self.conv2d_L2(x)) # (16, 128, 64, 24)
x = torch.sum(torch.sum(x, dim = 3), dim = 2) # (16, 128)
x = self.classifier(x) # (16, 10)
return x
class model_test2(nn.Module): # use gather_op twice
def __init__(self, num_classes, input_dim=3):
super().__init__()
self.conv1d_L1 = nn.Conv1d(input_dim, 32, 1)
self.conv2d_L2 = nn.Conv2d(32, 128, 1)
self.conv2d_L3 = nn.Conv2d(128, 256, 1)
self.relu = nn.ReLU(inplace=True)
self.sampling = sampling()
self.classifier = nn.Linear(256, 10)
def forward(self, x, idx1, idx2):
x = self.relu(self.conv1d_L1(x)) # (16, 32, 128)
x = self.sampling(x, idx1) # (16, 32, 64, 24)
x = self.relu(self.conv2d_L2(x)) # (16, 128, 64, 24)
x = torch.sum(x, dim = 3) # (16, 128, 64)
x = self.sampling(x, idx2) # (16, 128, 32, 24)
x = self.relu(self.conv2d_L3(x)) # (16, 256, 32, 24)
x = torch.sum(torch.sum(x, dim = 3), dim = 2) # (16, 256)
x = self.classifier(x) # (16, 10)
return x
model1, model2 = model_test1(10, 3), model_test2(10, 3)
model1, model2 = model1.cuda(), model2.cuda()
optimizer1, optimizer2 = optim.Adam(model1.parameters(), lr=0.001), optim.Adam(model2.parameters(), lr=0.001)
data = torch.randn(1000, 3, 128).cuda() # 1000 samples, 3-d features, 128 pixels
label = torch.randint(0, 10, (1000,)).long().cuda()
criterion = nn.CrossEntropyLoss()
model1.train()
model2.train()
for iter in range(60):
index = torch.arange(16*iter, 16*(iter+1)).long().cuda() # batchsize = 16
input, target = data[index, ...], label[index, ...]
optimizer1.zero_grad()
optimizer2.zero_grad()
# index to sample 24 pixels
idx1 = torch.randint(0, 128, (16, 64, 24)).long().cuda() # (16, 64, 24)
idx2 = torch.randint(0, 64, (16, 32, 24)).long().cuda() # (16, 32, 24)
pred1, pred2 = model1(input, idx1), model2(input, idx1, idx2)
target = target.view(-1)
loss1, loss2 = criterion(pred1, target), criterion(pred2, target)
loss1.backward()
loss2.backward()
optimizer1.step()
optimizer2.step()
print('[%2d] loss1: %0.16f \t [%2d] loss2: %0.16f' % (iter, loss1.data.clone(), iter, loss2.data.clone()))
[Results show]
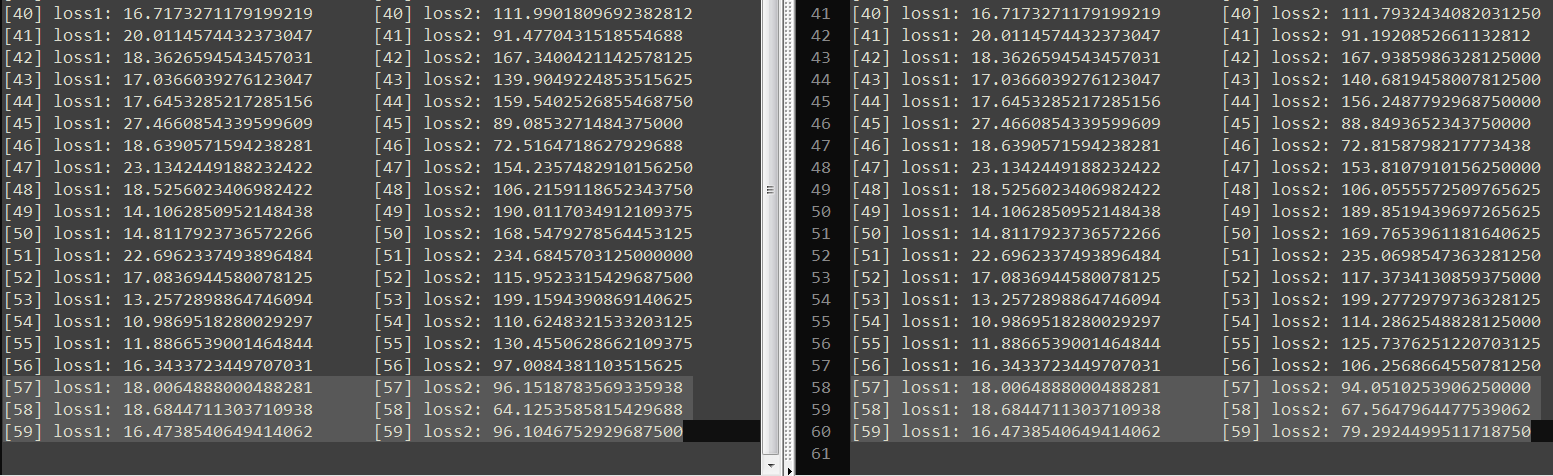
loss1 of model_test1 that uses torch.gather once is determined.
loss2 of model_test2 that uses torch.gather twice is undetermined in the two runs, as highlighted in the figure.
[Environment]
14.04.1-Ubuntu
cuda8.0 + cudnn v7.1
anaconda3 (Python 3.6.5)
pytorch 0.4.0/1.0.0 (both have this problem)
numpy 1.14.3
[Why not try other indexing methods]
I have tried the two methods below (for some reasons, I prefer to use pytorch 0.4.0 in my project):
METHOD 1: directly use advanced indexing
B, N, M = idx.shape
batch_indices = torch.arange(B).type(torch.cuda.LongTensor).view(B, 1, 1).expand(-1, N, M)
return feat.transpose(1, 2)[batch_indices, idx, :].permute(0, 3, 1, 2) # (B, C, N, M)
No randomness indeed, but in pytorch 0.4.0, this will cause huge memory issue and is very slow. Moreover, directly indexing for each batch (for i in range(batchsize)) also suffers the same memory issue.
METHOD 2: use torch.index_select
B = idx.shape[0]
new_feat = [torch.index_select(feat[i, ...], 1, idx[i, ...]).unsqueeze(0) for i in range(B)]
return torch.cat(new_feat, 0)
There is also randomness in torch.index_select.
torch.gather for me is fast and memory-saving, thus I want to use it for indexing.
Any useful help is welcome! Thanks.