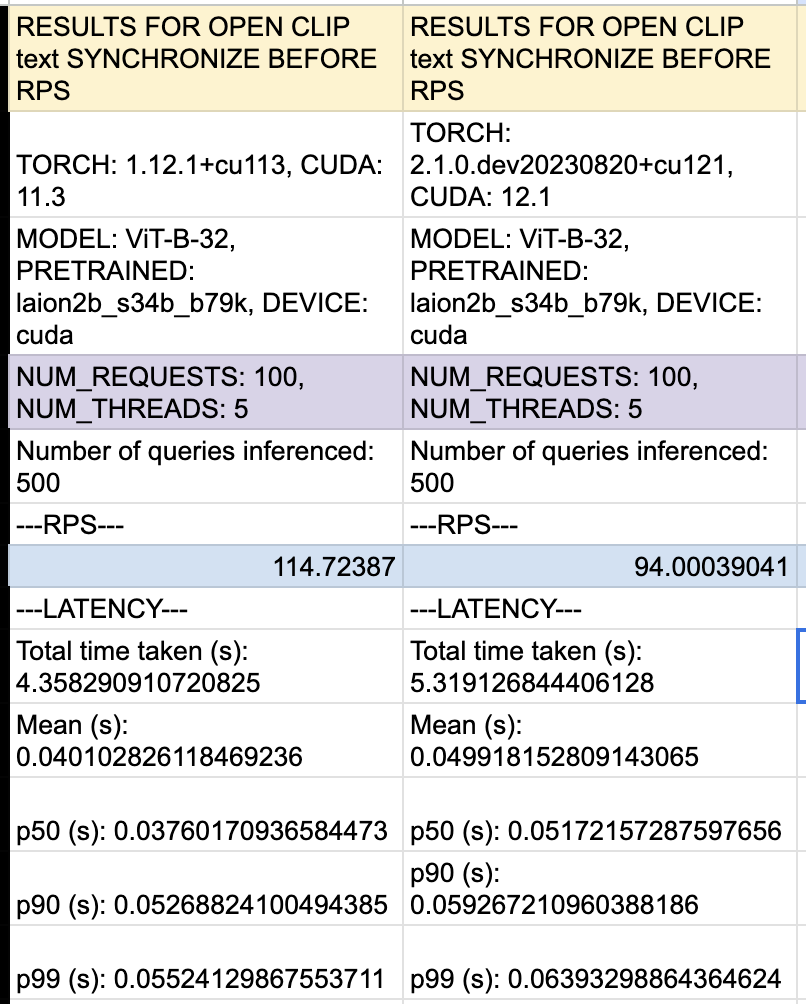
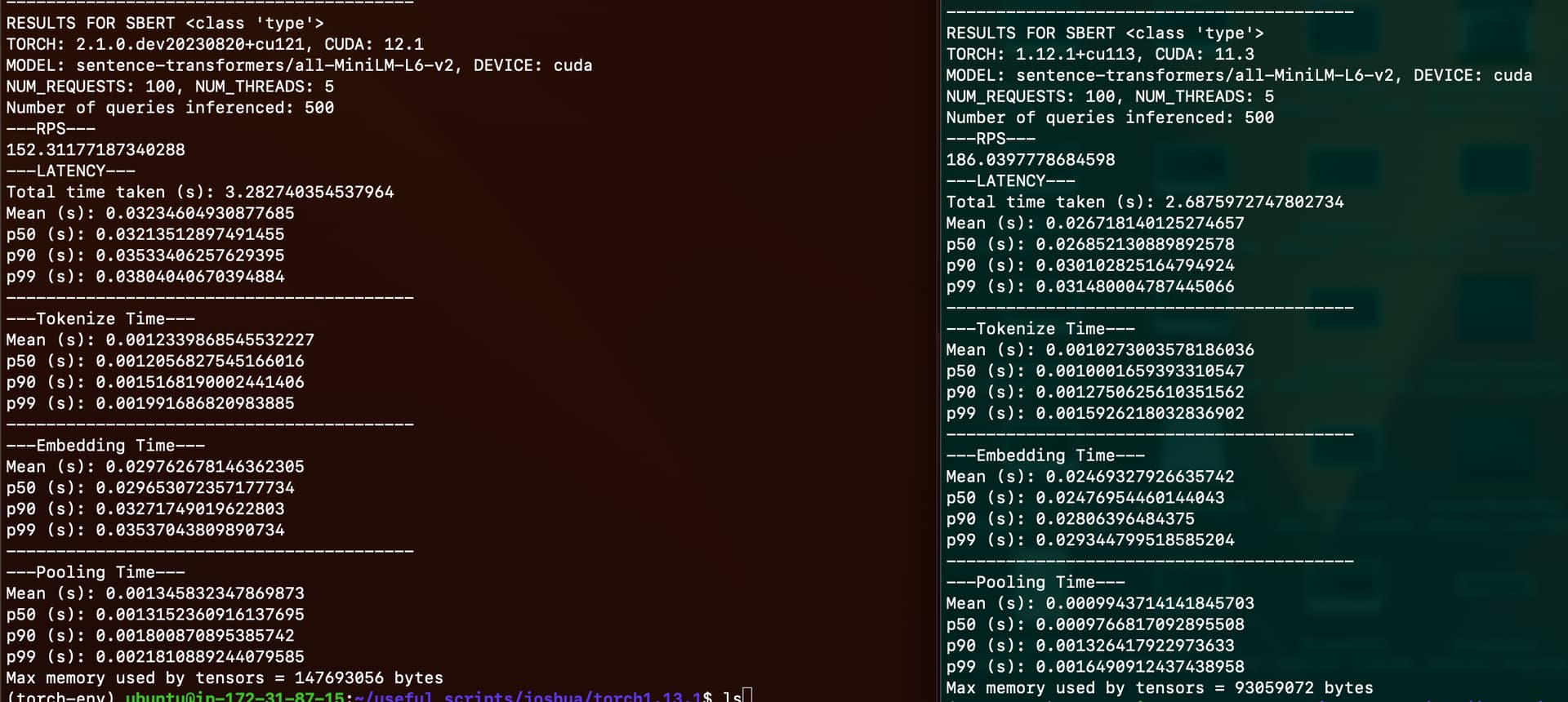
There is a significant speed degradation in encoding text (using model ViT-B-32/laion2b_s34b_b79k) with multiple threads when upgrading PyTorch versions. I have been encoding both images and text with open CLIP models, and have found that when upgrading from Torch 1.12.1 to 1.13.0, encoding latency increases significantly when using multiple threads. Here is sample data collected with 5 threads:
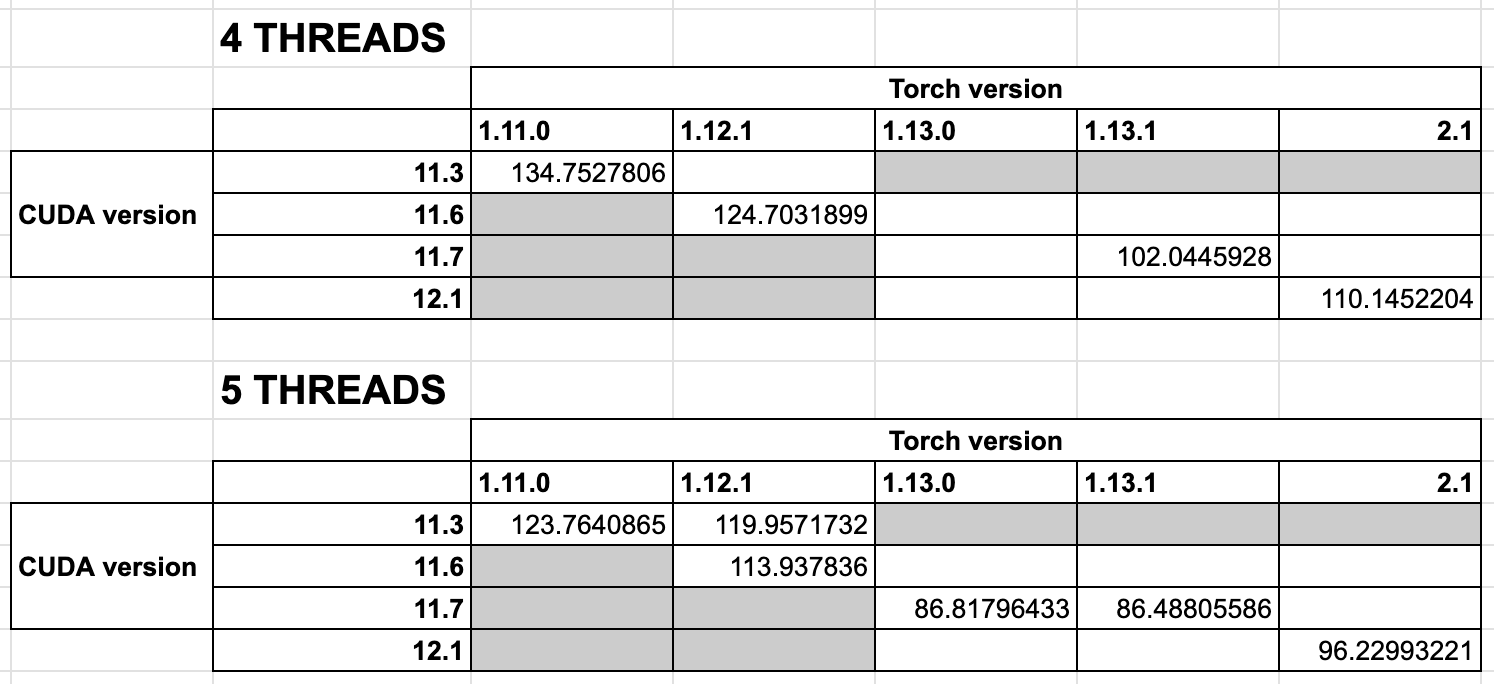
Text Encoding mean latency comparison (5 threads)
Torch version | 1.11.0 | 1.12.1 | 1.13.0
Latency (s) | 0.03681 | 0.03786 | 0.05414
Text Encoding Requests per second comparison (5 threads)
Torch version | 1.11.0 | 1.12.1 | 1.13.0
RPS | 123.76 | 119.96 | 86.82
This degradation does not occur when encoding with a single thread or when encoding images. Does anyone have an explanation why performance would degrade when upgrading my version?
To recreate:
- Start machine with torch 1.12.1 installed
pip3 install --no-cache-dir torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113 --upgrade
- Start another machine with torch 1.13.0 installed
pip3 install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117 --upgrade
- Install other requirements on both machines
pip install open_clip_torch==2.18.0 validators cython matplotlib
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
- Run the following script, which encodes entries from the COCO dataset, on both machines:
from PIL import Image
from open_clip import create_model_and_transforms, get_tokenizer
import torch
from typing import List, Tuple
import numpy as np
import os
import time
import validators
import requests
from pycocotools.coco import COCO
import random
import zipfile
import urllib
from tqdm import tqdm
import threading
import argparse
print("torch version:", torch.__version__)
print("CUDA version:", torch.version.cuda)
# Test 1
TARGET_MODEL = "ViT-B-32"
TARGET_PRETRAINED = "laion2b_s34b_b79k"
DEVICE = "cuda"
# Configurable parameters
parser = argparse.ArgumentParser(description='Pytorch Performance Test RPS Script')
parser.add_argument('--Threads', help='The number of threads', default = 5, type = int)
parser.add_argument('--Requests', help='The number of requests', default = 100, type = int)
args = parser.parse_args()
NUM_THREADS = args.Threads
NUM_REQUESTS = args.Requests
model, _, transform = create_model_and_transforms(model_name=TARGET_MODEL, pretrained=TARGET_PRETRAINED, device=DEVICE)
tokenizer = get_tokenizer(TARGET_MODEL)
def inference_time_on_image(image_path: str) -> float:
image = load_image_from_path(image_path)
processed_image = transform(image).unsqueeze(0).to(DEVICE)
start = time.time()
with torch.no_grad():
if DEVICE.startswith("cuda"):
with torch.cuda.amp.autocast():
image_features = model.encode_image(processed_image)
else:
image_features = model.encode_image(processed_image)
elapsed_time = time.time() - start
return elapsed_time
def load_image_from_path(image_path: str):
"""Loads an image into PIL from a string path that is either local or a url
Args:
image_path (str): Local or remote path to image.
Returns:
ImageType: In-memory PIL image.
"""
if os.path.isfile(image_path):
img = Image.open(image_path)
elif validators.url(image_path):
with requests.get(image_path, stream=True) as resp:
img = Image.open(resp.raw)
return img
def inference_time_on_text(text: str) -> float:
processed_text = tokenizer(text).to(DEVICE)
start = time.time()
with torch.no_grad():
if DEVICE.startswith("cuda"):
with torch.cuda.amp.autocast():
text_features = model.encode_text(processed_text)
else:
text_features = model.encode_text(processed_text)
elapsed_time = time.time() - start
return elapsed_time
class RequestThread(threading.Thread):
def __init__(self, queries, type):
# Should be given list of queries (generated beforehand)
super().__init__()
self.queries = queries
self.latencies = []
self.type = type
def run(self):
for q in self.queries:
try:
if self.type == "text":
self.latencies.append(inference_time_on_text(q))
elif self.type == "image":
self.latencies.append(inference_time_on_image(q))
else:
raise Exception(f"Invalid request type: {self.type}")
except Exception as e:
print(f"Error ({e})")
def warm_up_calls():
_ = inference_time_on_text("hello world")
_ = inference_time_on_image(
"https://raw.githubusercontent.com/marqo-ai/marqo/mainline/examples/ImageSearchGuide/data/image1.jpg")
def data_processed(time_list: List[float]) -> Tuple:
sample_size = len(time_list)
time_list_copy = np.copy(time_list)
mean = np.mean(time_list_copy)
p50 = np.percentile(time_list_copy, 50)
p90 = np.percentile(time_list_copy, 90)
p99 = np.percentile(time_list_copy, 99)
return sample_size, mean, p50, p90, p99
def download_util(
url: str,
cache_dir: str = "./",
):
buffer_size = 8192
if not cache_dir:
cache_dir = os.path.expanduser(ModelCache.clip_cache_path)
os.makedirs(cache_dir, exist_ok=True)
filename = os.path.basename(url)
download_target = os.path.join(cache_dir, filename)
if os.path.isfile(download_target):
print(f"File already exists at {download_target}. Skipping download.")
return download_target
print(f"About to start downloading annotations from url: {url}")
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
with tqdm(total=int(source.headers.get("Content-Length")), ncols=80, unit='iB', unit_scale=True) as loop:
while True:
buffer = source.read(buffer_size)
if not buffer:
break
output.write(buffer)
loop.update(len(buffer))
print(f"Finished downloading annotations from url: {url}")
return download_target
#######################################################
# LOADING COCO DATASET
#######################################################
tmp_path = './tmp/'
dataDir='./tmp'
dataType='train2014'
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataType)
capsFile = '{}/annotations/captions_{}.json'.format(dataDir,dataType)
annotations_url = "http://images.cocodataset.org/annotations/annotations_trainval2014.zip"
annotations_extract_path = f'{tmp_path}annotations'
if os.path.exists(annotations_extract_path):
print('Annotations already exist on disk. Skipping.')
else:
annotations_zip = download_util(annotations_url, tmp_path)
with zipfile.ZipFile(annotations_zip, 'r') as zf:
zf.extractall(tmp_path)
print('Annotations downloaded and extracted')
print("Loading COCO Dataset")
coco=COCO(annFile)
print("Loading COCO Caps File")
coco_caps = COCO(capsFile)
print("Loading COCO ANN File")
coco_anns = COCO(annFile)
img_id_list = coco.getImgIds()
def rps_test_for_type(type: str):
if type not in ["text", "image"]:
raise Exception("Invalid type")
# Create the threads
threads: List[RequestThread] = list()
for i in range(NUM_THREADS):
threads.append(RequestThread(queries[type][i], type))
print(f'Starting threads for type {type}')
start = time.time()
[t.start() for t in threads]
[t.join() for t in threads]
end = time.time()
elapsed = end - start
total_requests = sum(len(t.latencies) for t in threads)
latencies = [l for t in threads for l in t.latencies]
sample_size, mean, p50, p90, p99 = data_processed(latencies)
print("-----------------------------------------")
print(f"RESULTS FOR {type}")
print(f"TORCH: {torch.__version__}, CUDA: {torch.version.cuda}")
print(f"MODEL: {TARGET_MODEL}, PRETRAINED: {TARGET_PRETRAINED}, DEVICE: {DEVICE}")
print(f"NUM_REQUESTS: {NUM_REQUESTS}, NUM_THREADS: {NUM_THREADS}")
print("Number of queries inferenced:", sample_size)
print("---RPS---")
print(total_requests / elapsed)
print("---LATENCY---")
print("Total time taken (s):", elapsed)
print("Mean (s):", mean)
print("p50 (s):", p50)
print("p90 (s):", p90)
print("p99 (s):", p99)
def random_query():
"""
Get a random ID and get the text and image for that ID
"""
img_id = random.choice(img_id_list)
text = coco_caps.loadAnns(coco_caps.getAnnIds(img_id))[0]["caption"]
image = coco_anns.loadImgs(img_id)[0]["coco_url"]
return text, image
print('Generating random queries')
queries = {
"text": [],
"image": []
}
for i in tqdm(range(NUM_THREADS)):
thread_text_queries = []
thread_image_queries = []
for _ in tqdm(range(NUM_REQUESTS)):
text, image = random_query()
thread_text_queries.append(text)
thread_image_queries.append(image)
print(f"Generated (FOR THREAD {i}): {len(thread_text_queries)} texts and {len(thread_image_queries)} images.")
queries["text"].append(thread_text_queries)
queries["image"].append(thread_image_queries)
print('Done generating queries')
def main():
warm_up_calls()
rps_test_for_type("text")
rps_test_for_type("image")
if __name__ == "__main__":
main()
Observe that the latency is higher for the later torch version. You can change the --Threads and --Requests args to observe the effect of concurrency on latency.