Hi, just following up on this. I have produced a minimal example where there is a clear regression in text encoding speed with an SBERT model. This example uses torch.synchronize, removes downloading & random text generation (uses one hard-coded sentence instead), proving that the encoding really slows down.
import argparse
import threading
import time
from typing import List, Tuple
import numpy as np
import torch
from transformers import AutoTokenizer, AutoModel
print("torch version:", torch.__version__)
print("CUDA version:", torch.version.cuda)
DEVICE = "cuda"
device = torch.device(DEVICE)
# Configurable parameters
parser = argparse.ArgumentParser(description='Pytorch Performance Test RPS Script')
parser.add_argument('--Threads', help='The number of threads', default=5, type=int)
parser.add_argument('--Requests', help='The number of requests', default=100, type=int)
parser.add_argument('--Model', help='The model', default="sentence-transformers/all-MiniLM-L6-v2", type=str)
args = parser.parse_args()
NUM_THREADS = args.Threads
NUM_REQUESTS = args.Requests
TARGET_MODEL = args.Model
test_text = 'A herd of horses standing on top of a lush green field.', 'A bird sitting on top of a wooden framed mirror.'
# Loading model
tokenizer = AutoTokenizer.from_pretrained(TARGET_MODEL)
model = AutoModel.from_pretrained(TARGET_MODEL).to(device)
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
def inference_time_on_text(text: str) -> dict:
times = {}
start_total = time.time()
start = time.time()
torch.cuda.synchronize()
# Tokenize sentences
encoded_input = tokenizer(text, padding=True, truncation=True, max_length=128, return_tensors='pt').to(device)
torch.cuda.synchronize()
elapsed_time = time.time() - start
times['tokenize'] = elapsed_time
start = time.time()
torch.cuda.synchronize()
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
torch.cuda.synchronize()
elapsed_time = time.time() - start
times['embeddings'] = elapsed_time
start = time.time()
torch.cuda.synchronize()
# Perform pooling. In this case, mean pooling
_ = mean_pooling(model_output, encoded_input['attention_mask'])
torch.cuda.synchronize()
elapsed_time = time.time() - start
times['pooling'] = elapsed_time
elapsed_time = time.time() - start_total
times['total'] = elapsed_time
return times
class RequestThread(threading.Thread):
def __init__(self, text):
super().__init__()
self.text = text
self.toekenize_times = []
self.embeddings_times = []
self.pooling_times = []
self.total_times = []
def run(self):
for _ in range(NUM_REQUESTS):
try:
times = inference_time_on_text(self.text)
self.toekenize_times.append(times['tokenize'])
self.embeddings_times.append(times['embeddings'])
self.pooling_times.append(times['pooling'])
self.total_times.append(times['total'])
except Exception as e:
print(f"Error ({e})")
def warm_up_calls():
_ = inference_time_on_text("hello world")
def data_processed(time_list: List[float]) -> Tuple:
sample_size = len(time_list)
time_list_copy = np.copy(time_list)
mean = np.mean(time_list_copy)
p50 = np.percentile(time_list_copy, 50)
p90 = np.percentile(time_list_copy, 90)
p99 = np.percentile(time_list_copy, 99)
return sample_size, mean, p50, p90, p99
def multi_threaded_test():
# Create the threads
threads: List[RequestThread] = list()
for i in range(NUM_THREADS):
threads.append(RequestThread(test_text))
print(f'Starting threads')
start = time.time()
torch.cuda.synchronize()
[t.start() for t in threads]
[t.join() for t in threads]
torch.cuda.synchronize()
end = time.time()
elapsed = end - start
total_requests = sum(len(t.total_times) for t in threads)
latencies = [l for t in threads for l in t.total_times]
sample_size, mean, p50, p90, p99 = data_processed(latencies)
print("-----------------------------------------")
print(f"RESULTS FOR SBERT {type}")
print(f"TORCH: {torch.__version__}, CUDA: {torch.version.cuda}")
print(f"MODEL: {TARGET_MODEL}, DEVICE: {DEVICE}")
print(f"NUM_REQUESTS: {NUM_REQUESTS}, NUM_THREADS: {NUM_THREADS}")
print("Number of queries inferenced:", sample_size)
print("---RPS---")
print(total_requests / elapsed)
print("---LATENCY---")
print("Total time taken (s):", elapsed)
print("Mean (s):", mean)
print("p50 (s):", p50)
print("p90 (s):", p90)
print("p99 (s):", p99)
# Tokenize
latencies = [l for t in threads for l in t.toekenize_times]
sample_size, mean, p50, p90, p99 = data_processed(latencies)
print("-----------------------------------------")
print("---Tokenize Time---")
print("Mean (s):", mean)
print("p50 (s):", p50)
print("p90 (s):", p90)
print("p99 (s):", p99)
# Embeddings
latencies = [l for t in threads for l in t.embeddings_times]
sample_size, mean, p50, p90, p99 = data_processed(latencies)
print("-----------------------------------------")
print("---Embedding Time---")
print("Mean (s):", mean)
print("p50 (s):", p50)
print("p90 (s):", p90)
print("p99 (s):", p99)
# Pooling
latencies = [l for t in threads for l in t.pooling_times]
sample_size, mean, p50, p90, p99 = data_processed(latencies)
print("-----------------------------------------")
print("---Pooling Time---")
print("Mean (s):", mean)
print("p50 (s):", p50)
print("p90 (s):", p90)
print("p99 (s):", p99)
print("Max memory used by tensors = {} bytes".format(torch.cuda.max_memory_allocated()))
def main():
warm_up_calls()
multi_threaded_test()
if __name__ == "__main__":
main()
Side-by-side comparison of Torch 2.1.0 vs Torch 1.12.1:
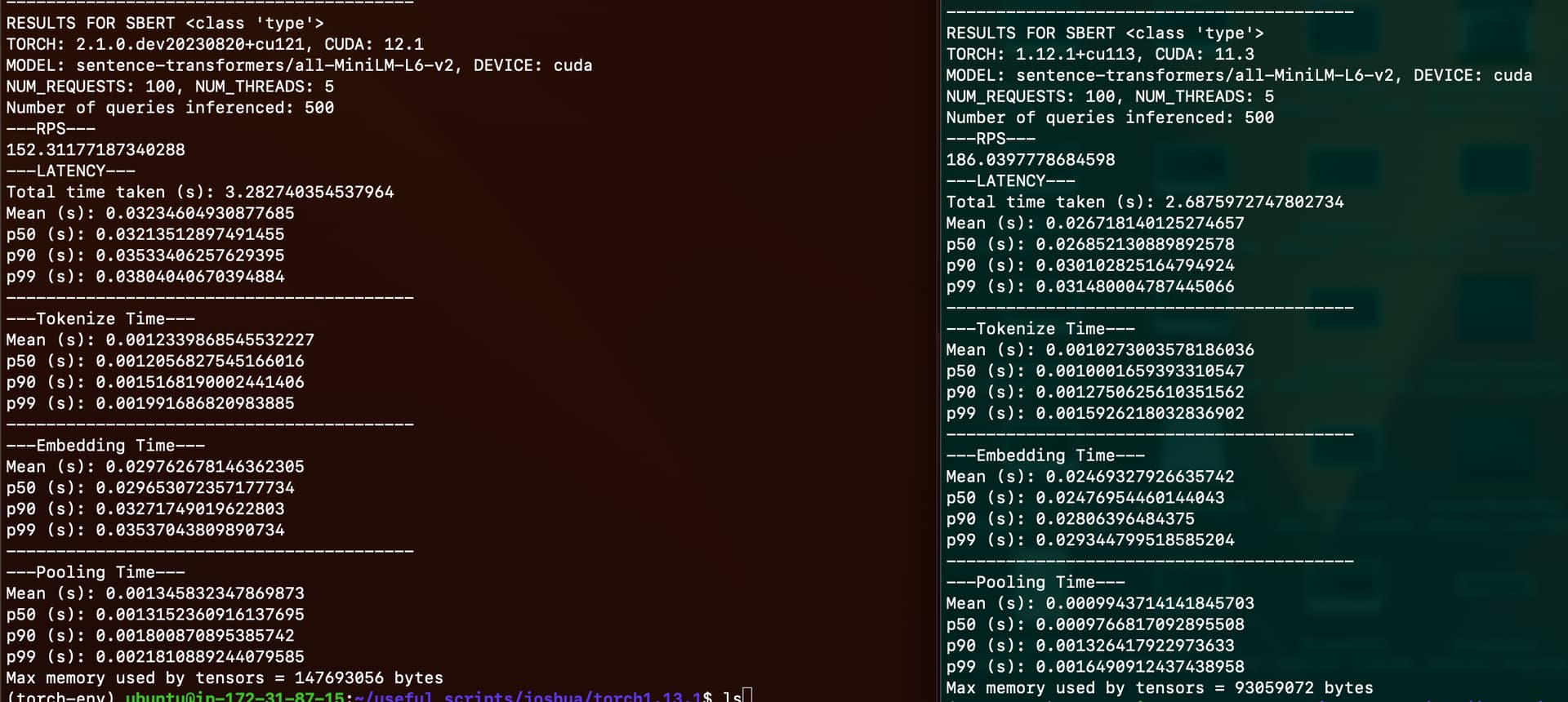
Observe that Torch 2.1.0 is slower (152 RPS < 186 RPS).