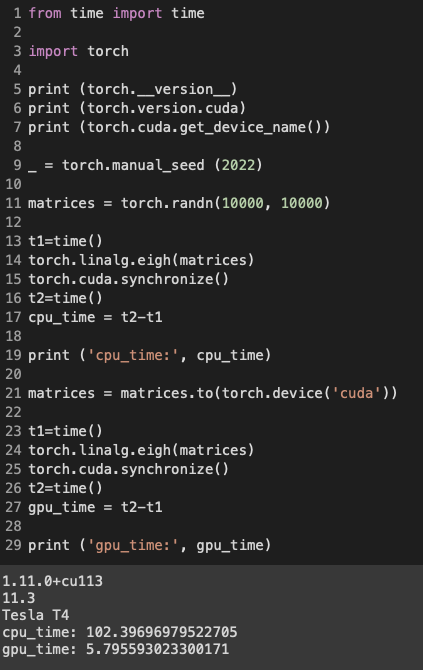
Hi @KFrank!
Thanks for the detailed response! After reading your comments, it did give me a thought about potentially using functorch and seeing if that affects performance. This problem seems to primarily affect larger matrices, and using functorch actually seems to speed up the GPU to be better than the CPU for small matrices. I’ve got some results below with all time measured in seconds.
version: 1.12.0a0+git7c2103a
CUDA: 11.6
Size of Tensor: torch.Size([1000, 32, 32])
CPU time: 0.05937480926513672
GPU time: 0.5319147109985352
FUNC time: 0.004615306854248047
Size of Tensor: torch.Size([1000, 64, 64])
CPU time: 0.1272900104522705
GPU time: 0.8110277652740479
FUNC time: 0.7586314678192139
Size of Tensor: torch.Size([1000, 128, 128])
CPU time: 0.4362821578979492
GPU time: 1.8971400260925293
FUNC time: 1.9026517868041992
Size of Tensor: torch.Size([1000, 256, 256])
CPU time: 1.5289278030395508
GPU time: 5.590537071228027
FUNC time: 5.531857967376709
Size of Tensor: torch.Size([10000, 32, 32])
CPU time: 0.4745197296142578
GPU time: 0.515204906463623
FUNC time: 0.04160284996032715
Size of Tensor: torch.Size([10000, 64, 64])
CPU time: 1.1662471294403076
GPU time: 6.958388805389404
FUNC time: 6.955511808395386
Size of Tensor: torch.Size([10000, 128, 128])
CPU time: 3.8899362087249756
GPU time: 18.134103775024414
FUNC time: 18.80874514579773
To reproduce these results the script is below,
from time import time
import torch
from functorch import vmap
veigh = vmap(torch.linalg.eigh)
#same as vmap(torch.linalg.eigh, in_dims=(0))(matrices)
print("version: ",torch.__version__)
print("CUDA: ",torch.version.cuda, "\n")
for B in [1000]:
for N in [32, 64, 128, 256]:
matrices = torch.randn(B, N, N)
matrices = matrices @ matrices.transpose(-2,-1)
torch.cuda.synchronize()
t1=time()
torch.linalg.eigh(matrices)
torch.cuda.synchronize()
t2=time()
cpu_time = t2-t1
matrices = matrices.to(torch.device('cuda'))
torch.cuda.synchronize()
t1=time()
torch.linalg.eigh(matrices)
torch.cuda.synchronize()
t2=time()
gpu_time = t2-t1
torch.cuda.synchronize()
t1=time()
veigh(matrices)
torch.cuda.synchronize()
t2=time()
func_time=t2-t1
print("Size of Tensor: ",matrices.shape)
print("CPU time: ",cpu_time)
print("GPU time: ",gpu_time)
print("FUNC time: ",func_time, "\n")