I just updated to .11 and I think the api for calling torch.nn.DataParallel has changed. In the previous version if I only had one GPU I would call the function with None passed as the device_ids. Now if I pass None I get the following error:
File "/home/jtremblay/anaconda2/envs/py3/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 96, in data_parallel
output_device = device_ids[0]
TypeError: 'NoneType' object is not subscriptable
actually it applies to using the functional version data_parallel.
I’ve identified the issue and fixed it in https://github.com/pytorch/pytorch/pull/1187
It should be in our next release.
Sorry for the late reply I am travelling. I should have provided an example or do a PR. I have been using the ids from now. It was an easy fix for upgrading my scripts. But thank you so much for your time.
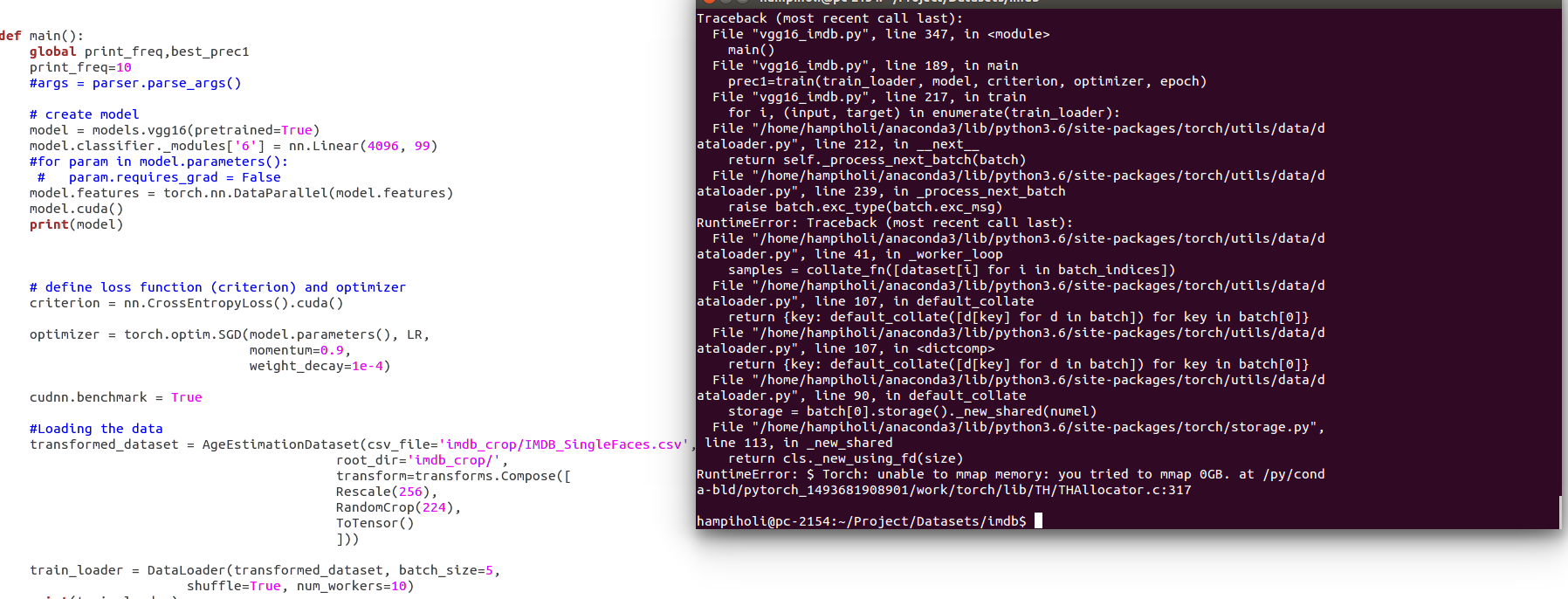
I am getting Torch: unable to mmap memory: you tried to mmap 0GB error. I have 12 GB RAM, 1 GPU core and the datasize is 7GB. Ideally it should not give this error. I think i am making mistake in cuda and dataparallel, but unable to figure it out. Attached image contains the details. Please help!!