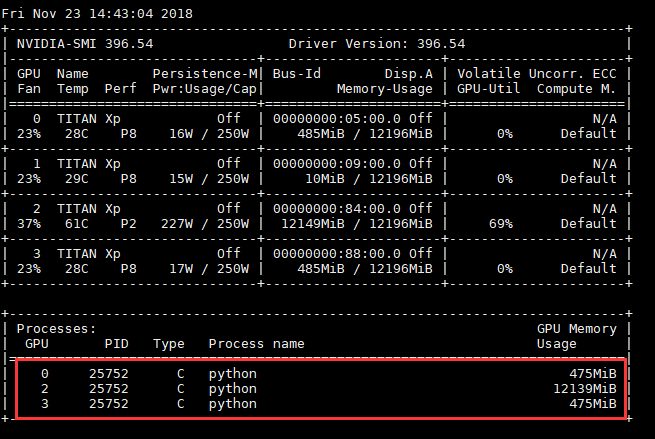
Hi all,
In my program, I restore a model(torch.nn.DataParallel) and use device 2 to continue training. However, Like the picture shows, the program not only uses device 2, but also takes up some gpu memory of device 0 and 3. I am confused about that.
I guess it may happen when my model is first trained from device 0 or 3, and when I restore the model to device 2, it still use some gpu memory from the device it was trained before. But I am not sure and I want to find out the essential reason so that I can prevent this phenomenon happening again. Can anyone help me?
475MB is most certainly only the cuda initialisation on this device, no Tensor.
Maybe you want to specify the map_location argument of torch.load when you load your model to avoid initializing the other GPUs.
Another way is to use CUDA_VISIBLE_DEVICES=2 as an env variable for your script so that only a single GPU is ever visible and the other ones will never be used.
Nice, I solve this problem with your answer. I don’t know in pytorch the models will be loaded to the device they were saved from. Thank you very much!