Thanks for a leaving comment!
Actually, it’s the first time I’ve asked a question like this, so I’m still very inexperienced.
Thanks for letting me know that such a feature exists!!
class VGG_Cifar10(nn.Module):
def __init__(self, num_classes=10):
super(VGG_Cifar10, self).__init__()
self.infl_ratio=1
self.features = nn.Sequential(
nn.ConstantPad2d(1, 1),
BinarizeConv2d(3, 128*self.infl_ratio, kernel_size=3, stride=1, bias=True),
nn.BatchNorm2d(128*self.infl_ratio),
nn.Hardtanh(inplace=True),
nn.ConstantPad2d(1, 1),
BinarizeConv2d(128*self.infl_ratio, 128*self.infl_ratio, kernel_size=3, bias=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(128*self.infl_ratio),
nn.Hardtanh(inplace=True),
nn.ConstantPad2d(1, 1),
BinarizeConv2d(128*self.infl_ratio, 256*self.infl_ratio, kernel_size=3, bias=True),
nn.BatchNorm2d(256*self.infl_ratio),
nn.Hardtanh(inplace=True),
nn.ConstantPad2d(1, 1),
BinarizeConv2d(256*self.infl_ratio, 256*self.infl_ratio, kernel_size=3, bias=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(256*self.infl_ratio),
nn.Hardtanh(inplace=True),
nn.ConstantPad2d(1, 1),
BinarizeConv2d(256*self.infl_ratio, 512*self.infl_ratio, kernel_size=3, bias=True),
nn.BatchNorm2d(512*self.infl_ratio),
nn.Hardtanh(inplace=True),
nn.ConstantPad2d(1, 1),
BinarizeConv2d(512*self.infl_ratio, 512, kernel_size=3, bias=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(512),
nn.Hardtanh(inplace=True)
)
self.classifier = nn.Sequential(
BinarizeLinear(512 * 4 * 4, 1024, bias=True),
nn.BatchNorm1d(1024),
nn.Hardtanh(inplace=True),
#nn.Dropout(0.5),
BinarizeLinear(1024, 1024, bias=True),
nn.BatchNorm1d(1024),
nn.Hardtanh(inplace=True),
#nn.Dropout(0.5),
BinarizeLinear(1024, num_classes, bias=True),
nn.BatchNorm1d(num_classes, affine=False)
)
self.regime = {
0: {'optimizer': 'Adam', 'betas': (0.9, 0.999),'lr': 5e-3},
40: {'lr': 1e-3},
80: {'lr': 5e-4},
100: {'lr': 1e-4},
120: {'lr': 5e-5},
140: {'lr': 1e-5}
}
def forward(self, x):
x = self.features(x)
x = x.view(-1, 512 * 4 * 4)
x = self.classifier(x)
return x
model = VGG_Cifar10()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
params = torch.load("211201_vgg_cifar10_model.pt", map_location = "cpu")
model.load_state_dict(params, strict=False)
model.eval()
default_transform = {
'eval': get_transform(args.dataset,
input_size=args.input_size, augment=False)
}
transform = getattr(model, 'input_transform', default_transform)
val_data = get_dataset(args.dataset, 'val', transform['eval'])
val_loader = torch.utils.data.DataLoader(
val_data,
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
images, labels = next(iter(val_loader))
with torch.no_grad():
output = model(images)
num = 0
print(output[num])
The above code shows the model structure and the inference process with the trained model.
Here, BinarizeConv2d, BinarizeLinear is a function that performs convolution by binarizeing the weight and input.
itemlist = model.state_dict()
features_1_weight = itemlist['features.1.weight']
features_1_bias = itemlist['features.1.bias']
features_2_weight = itemlist['features.2.weight']
features_2_bias = itemlist['features.2.bias']
features_2_mean = itemlist['features.2.running_mean']
features_2_var = itemlist['features.2.running_var']
features_5_weight = itemlist['features.5.weight']
features_5_bias = itemlist['features.5.bias']
features_7_weight = itemlist['features.7.weight']
features_7_bias = itemlist['features.7.bias']
features_7_mean = itemlist['features.7.running_mean']
features_7_var = itemlist['features.7.running_var']
features_10_weight = itemlist['features.10.weight']
features_10_bias = itemlist['features.10.bias']
features_11_weight = itemlist['features.11.weight']
features_11_bias = itemlist['features.11.bias']
features_11_mean = itemlist['features.11.running_mean']
features_11_var = itemlist['features.11.running_var']
features_14_weight = itemlist['features.14.weight']
features_14_bias = itemlist['features.14.bias']
features_16_weight = itemlist['features.16.weight']
features_16_bias = itemlist['features.16.bias']
features_16_mean = itemlist['features.16.running_mean']
features_16_var = itemlist['features.16.running_var']
features_19_weight = itemlist['features.19.weight']
features_19_bias = itemlist['features.19.bias']
features_20_weight = itemlist['features.20.weight']
features_20_bias = itemlist['features.20.bias']
features_20_mean = itemlist['features.20.running_mean']
features_20_var = itemlist['features.20.running_var']
features_23_weight = itemlist['features.23.weight']
features_23_bias = itemlist['features.23.bias']
features_25_weight = itemlist['features.25.weight']
features_25_bias = itemlist['features.25.bias']
features_25_mean = itemlist['features.25.running_mean']
features_25_var = itemlist['features.25.running_var']
classifier_0_weight = itemlist['classifier.0.weight']
classifier_0_bias = itemlist['classifier.0.bias']
classifier_1_weight = itemlist['classifier.1.weight']
classifier_1_bias = itemlist['classifier.1.bias']
classifier_1_mean = itemlist['classifier.1.running_mean']
classifier_1_var = itemlist['classifier.1.running_var']
classifier_3_weight = itemlist['classifier.3.weight']
classifier_3_bias = itemlist['classifier.3.bias']
classifier_4_weight = itemlist['classifier.4.weight']
classifier_4_bias = itemlist['classifier.4.bias']
classifier_4_mean = itemlist['classifier.4.running_mean']
classifier_4_var = itemlist['classifier.4.running_var']
classifier_6_weight = itemlist['classifier.6.weight']
classifier_6_bias = itemlist['classifier.6.bias']
classifier_7_mean = itemlist['classifier.7.running_mean']
classifier_7_var = itemlist['classifier.7.running_var']
I got the parameters in this way
a = images[num]
a = torch.sign(a)
a = a.unsqueeze(0)
PAD = nn.ConstantPad2d(1, 1)
MAX = nn.MaxPool2d(2, 2)
cifar = PAD(a)
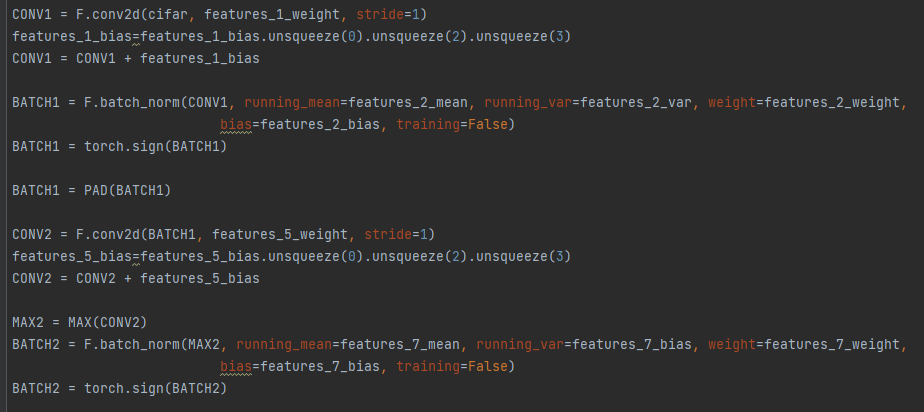
CONV1 = F.conv2d(cifar, features_1_weight, stride=1)
features_1_bias=features_1_bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
CONV1 = CONV1 + features_1_bias
BATCH1 = F.batch_norm(CONV1, running_mean=features_2_mean, running_var=features_2_var, weight=features_2_weight,
bias=features_2_bias, training=False)
BATCH1 = torch.sign(BATCH1)
BATCH1 = PAD(BATCH1)
CONV2 = F.conv2d(BATCH1, features_5_weight, stride=1)
features_5_bias=features_5_bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
CONV2 = CONV2 + features_5_bias
MAX2 = MAX(CONV2)
BATCH2 = F.batch_norm(MAX2, running_mean=features_7_mean, running_var=features_7_bias, weight=features_7_weight,
bias=features_7_bias, training=False)
BATCH2 = torch.sign(BATCH2)
BATCH2 = PAD(BATCH2)
CONV3 = F.conv2d(BATCH2, features_10_weight, stride=1)
features_10_bias=features_10_bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
CONV3 = CONV3 + features_10_bias
BATCH3 = F.batch_norm(CONV3, running_mean=features_11_mean, running_var=features_11_var, weight=features_11_weight,
bias=features_11_bias, training=False)
BATCH3 = torch.sign(BATCH3)
BATCH3 = PAD(BATCH3)
CONV4 = F.conv2d(BATCH3, features_14_weight, stride=1)
features_14_bias=features_14_bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
CONV4 = CONV4 + features_14_bias
MAX4 = MAX(CONV4)
BATCH4 = F.batch_norm(MAX4, running_mean=features_16_mean, running_var=features_16_bias, weight=features_16_weight,
bias=features_16_bias, training=False)
BATCH4 = torch.sign(BATCH4)
BATCH4 = PAD(BATCH4)
CONV5 = F.conv2d(BATCH4, features_19_weight, stride=1)
features_19_bias=features_19_bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
CONV5 = CONV5 + features_19_bias
BATCH5 = F.batch_norm(CONV5, running_mean=features_20_mean, running_var=features_20_var, weight=features_20_weight,
bias=features_20_bias, training=False)
BATCH5 = torch.sign(BATCH5)
BATCH5 = PAD(BATCH5)
CONV6 = F.conv2d(BATCH5, features_23_weight, stride=1)
features_23_bias=features_23_bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
CONV6 = CONV6 + features_23_bias
MAX6 = MAX(CONV6)
BATCH6 = F.batch_norm(MAX6, running_mean=features_25_mean, running_var=features_25_var, weight=features_25_weight,
bias=features_25_bias, training=False)
BATCH6 = torch.sign(BATCH6)
BATCH6 = BATCH6.view(-1, 512 * 4 * 4)
LIN1 = F.linear(BATCH6, classifier_0_weight)
classifier_0_bias = classifier_0_bias.unsqueeze(0)
LIN1 = LIN1 + classifier_0_bias
BATCH_1C = F.batch_norm(LIN1, running_mean=classifier_1_mean, running_var=classifier_1_var,
weight=classifier_1_weight, bias=classifier_1_bias, training=False)
batch_1c = batchnorm(LIN1, classifier_1_weight, classifier_1_bias, classifier_1_mean, classifier_1_var)
BATCH_1C = torch.sign(BATCH_1C)
LIN2 = F.linear(BATCH_1C, classifier_3_weight)
classifier_3_bias = classifier_3_bias.unsqueeze(0)
LIN2 = LIN2 + classifier_3_bias
BATCH_2C = F.batch_norm(LIN2, running_mean=classifier_4_mean, running_var=classifier_4_var,
weight=classifier_4_weight, bias=classifier_4_bias, training=False)
BATCH_2C = torch.sign(BATCH_2C)
LIN3 = F.linear(BATCH_2C, classifier_6_weight)
classifier_6_bias = classifier_6_bias.unsqueeze(0)
LIN3 = LIN3 + classifier_6_bias
BATCH_3C = F.batch_norm(LIN3, running_mean=classifier_7_mean, running_var=classifier_7_var, training=False)
print(BATCH_3C)
I am trying to perform inference by putting the parameter values obtained in the above code directly into the torch function. But output[num] in the first code and BATCH_3C in the third code do not have the same result value.